现在网上很多疫情数据已经比较难进行爬取,而且爬取出来的数据需要比较复杂的处理,现在可以使用许老师给的网址进行数据爬取,直接返回的是一个json数据。
一、数据爬取
import requests,json
import time
url = ‘https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&callback=&=%d’%int(time.time()*1000)#timet得到当前的时间戳
res = requests.get(url)
a = json.loads(res.text)
print(a)
 可以看到我们需要的数据是在data里,但后面的数据并不是标准的字典数据,而是json数据,需要进一步解析
可以看到我们需要的数据是在data里,但后面的数据并不是标准的字典数据,而是json数据,需要进一步解析
b = a[‘data’]
b = json.loads(b)
print(b)

这个数据看上去确实头痛,那我们怎么获得我们最终想要的数据呢,可以使用b.keys(),一步步往下面拆,就可找到了,最终数据放在了[‘areaTree’][0][‘children’],里面有城市名与总的各个小项数据
c = [i[‘name’] for i in b[‘areaTree’][0][‘children’]]
d = [i[‘total’] for i in b[‘areaTree’][0][‘children’]]

二、数据整理
整理主要使用的是pandas
import pandas as pd
e = dict(zip(c,d))
df = pd.DataFrame(e)
df.drop([‘showHeal’,‘showRate’],inplace = True)#把不要的数据删除
df =df.rename(dict(zip(df.index,[‘确认’,‘死忘’,‘死忘率’,‘治愈’,‘治愈率’,‘疑似’])),axis = 0)#重命名索引轴
df.drop([‘死忘率’,‘治愈率’],inplace =True)
df

三、数据可视化
这边介绍两种数据可视化的库seaborn和pyecharts做地图可视化
1.searborn
由于数据是一种宽型数据,将其转化为长型数据
df =df.reset_index()
df = pd.melt(df,[‘index’])
df = df.rename(dict(zip(df.columns,[‘指标’,‘城市’,‘数值’])),axis =1)
print(df)

mpl.rcParams[‘font.sans-serif’] =[‘SimHei’]#需要用到pylab库,显示中文
fig,ax = plt.subplots(figsize = (15,5))
sns.barplot(‘城市’,‘数值’,data = df,hue = ‘指标’)

sns.factorplot(‘城市’,‘数值’,kind =‘bar’,col = ‘指标’,data = df )
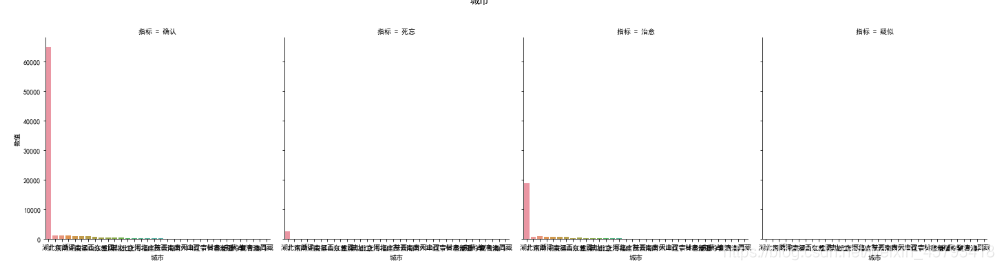
2.pyecharts
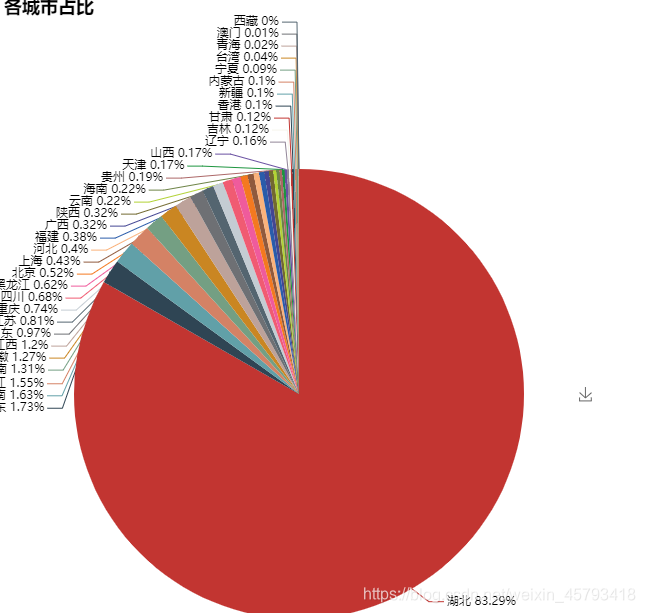
各城市的的Pie图
e = pyecharts.Pie(‘各城市占比’,width = 600,height = 800)
e.add(’’,df[df.指标 == ‘确认’][‘城市’],df[df.指标 == ‘确认’][‘数值’],is_label_show =True, is_legend_show = False)
e.render()
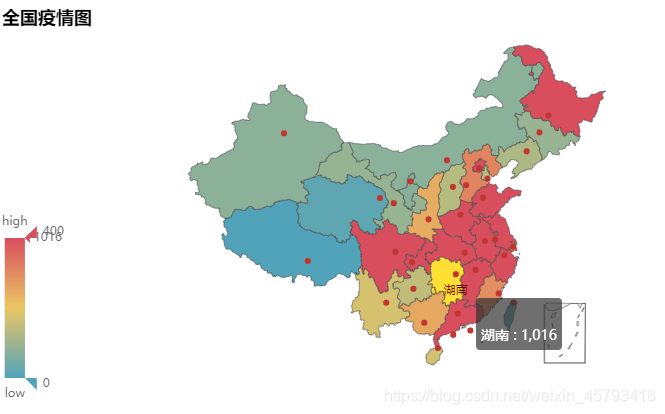
map1 = pyecharts.Map(‘全国疫情图’)
map1.add(’’,df[df.指标 == ‘确认’][‘城市’],df[df.指标 == ‘确认’][‘数值’],maptype =‘china’,is_visualmap=True,visual_range=[0,400],visual_text_color =’#6E6E6E’)
map1.render(‘1.html’)
附上原代码:
import requests,json
import time
import pandas as pd
import seaborn as sns
from pylab import *
import pyecharts
import matplotlib.pyplot as plt
url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&callback=&=%d’%int(time.time()*1000)
#print(url)
res = requests.get(url)
a = json.loads(res.text)
#print(a)
b = a[‘data’]
b = json.loads(b)
c = [i[‘name’] for i in b[‘areaTree’][0][‘children’]]
d = [i[‘total’] for i in b[‘areaTree’][0][‘children’]]
e = dict(zip(c,d))
df = pd.DataFrame(e)
df.drop([‘showHeal’,‘showRate’],inplace = True)
df =df.rename(dict(zip(df.index,[‘确认’,‘死忘’,‘死忘率’,‘治愈’,‘治愈率’,‘疑似’])),axis = 0)
df.drop([‘死忘率’,‘治愈率’],inplace =True)
df =df.reset_index()
df = pd.melt(df,[‘index’])
df = df.rename(dict(zip(df.columns,[‘指标’,‘城市’,‘数值’])),axis =1)
mpl.rcParams[‘font.sans-serif’] =[‘SimHei’]
fig,ax = plt.subplots(figsize = (15,5))
#sns.pointplot(‘城市’,‘数值’,data = df,hue = ‘指标’)
#sns.barplot(‘城市’,‘数值’,data = df,hue = ‘指标’)
#sns.factorplot(‘城市’,‘数值’,kind =‘bar’,col = ‘指标’,data = df )
#map1 = pyecharts.Map(‘全国疫情图’)
#map1.add(’’,df[df.指标 == ‘确认’][‘城市’],df[df.指标 == ‘确认’][‘数值’],maptype =‘china’,is_visualmap=True,visual_range=[0,400],visual_text_color =’#6E6E6E’,is_label_show = True,label_formatter=’{a}’+’{b}’+’{c}’)
#map1.render(‘1.html’)
e = pyecharts.Pie(‘各城市占比’,width = 600,height = 800)
e.add(’’,df[df.指标 == ‘确认’][‘城市’],df[df.指标 == ‘确认’][‘数值’],is_label_show =True, is_legend_show = False)
e.render()
后疫情数据爬取与可视化

猜你喜欢
转载自blog.csdn.net/weixin_45793418/article/details/104498452
今日推荐
周排行