1、前言
孩子:妈妈我想看电影
妈妈:看,看大片,480部够吗?
孩子:够了,谢谢妈妈,妈妈真好
奈何烂片层出不穷,电影荒就成了常事,不如回归经典,看一看电影历史上票房排行位于前端的一些电影,票房高的电影不一定精彩,但烂片票房低则是必然
本文基于requests和BeautifulSoup爬取了电影历史票房Top480的基本信息,在观察这份文件同时也会考虑,票房的高低和评分是否存在一定的关系呢?与时间呢?与地区呢?在利用pandas完成对这份数据概况的分析后,自然而然就会得到答案
2、爬虫概况简要
豆瓣是一个静态网页,所以利用requests结合BeautifulSoup就能够爬取需要的信息,但前提是我们要登陆豆瓣,这会涉及到模拟登陆的知识,例如爬取微博,知乎类似网页都需要用到模拟登陆
在密码框可以输入一个错误的密码,为了能够找到准确的登陆网址,要注意这是一个POST请求
模拟登陆代码如下
#建立Session保存Cookie对话维持登陆状态
s = requests.Session()
def login_in():
#登陆的网址
login_url = 'https://accounts.douban.com/j/mobile/login/basic'
#请求头
headers = {'User-Agent': 'Mozilla/5.0','Referer': 'https://accounts.douban.com/passport/login_popup?login_source=anony'}
#登陆数据
data = {
'name': '***********',#*为豆瓣正确账号和密码
'password':'***********',
'remember': 'false'
}
try:
r = s.post(login_url,headers = headers,data=data)
except:
print("登陆失败")
#输出登陆结果
print(r.text)
Session()的作用是在登陆这个网站之后,进入网站的其他分页时也可以维持登陆状态
登陆成功后,会出现下图提示

剩下的爬虫内容比较简单,介于篇幅问题,不再陈述
数据如下

附上该网页链接:电影票房排行榜
3、数据分析
库与工具
再进行数据分析之前,先将必要的库导入
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import jieba
from wordcloud import WordCloud
#词云图加载背景图会用到
from PIL import Image
%matplotlib inline
seaborn简介:seaborn是基于matplotlib的图形可视化python包,在matplotlib的基础上进行了高级的API封装,能够用更简洁的代码绘制出更吸引人的可视化图。
工具:jupyter notebook
导入数据
数据分析第一步即将被分析的csv文件上传至jupyter notebook交互页面,并利用pandas读取文件,查看文件的基本内容
df = pd.read_csv('movie_ranking.csv')
df.head()
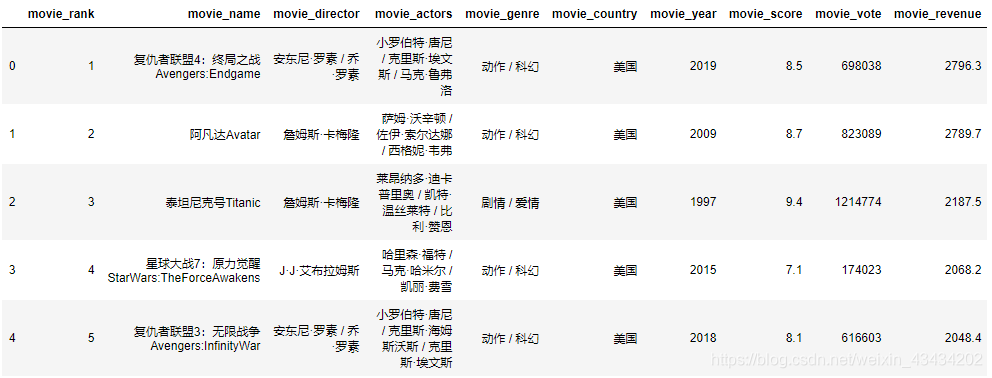
从左至右依次为:排名、电影名字、导演、主演、类型、制片国家、上映年份、豆瓣评分、投票人数、票房
由于位列170的电影被删除,无法获取相关信息,就只剩479部电影
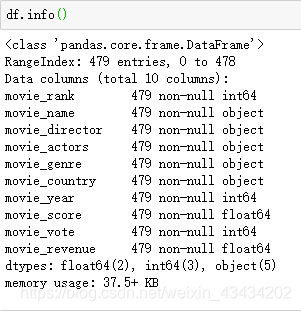
由于数据是自己爬取的,并且数据集很小,所以数据比较完整,可以跳过数据清洗直接进行数据可视化
数据可视化
电影评分与制片国家的关系
国家种类太多会导致绘图时不太美观,所以按照制片多少将国家分为四类即‘America’,‘Britain‘,’China‘,’Others‘四个地区
df['movie_country'].value_counts()
def Country(t):
if '美国' in t:
return 'America'
elif '英国' in t:
return 'Britain'
elif '中国大陆' in t:
return 'China'
else:
return 'Others'
#增加新一列————分类后的国家
df['Country'] = df['movie_country'].map(Country)
df1 = df.loc[:,('movie_score','Country')]
我们只讨论电影评分和制片地区的关系,所以将两列提取生成一个新的DataFrame对象
可视化选择用箱线图和散点图叠加
箱线图主要包含六个数据节点,将一组数据从大到小排列,分别计算出他的上边缘,上四分位数,中位数,下四分位数,下边缘,还有一个异常值,加入散点图后,也能呈现出电影评分的分布概况
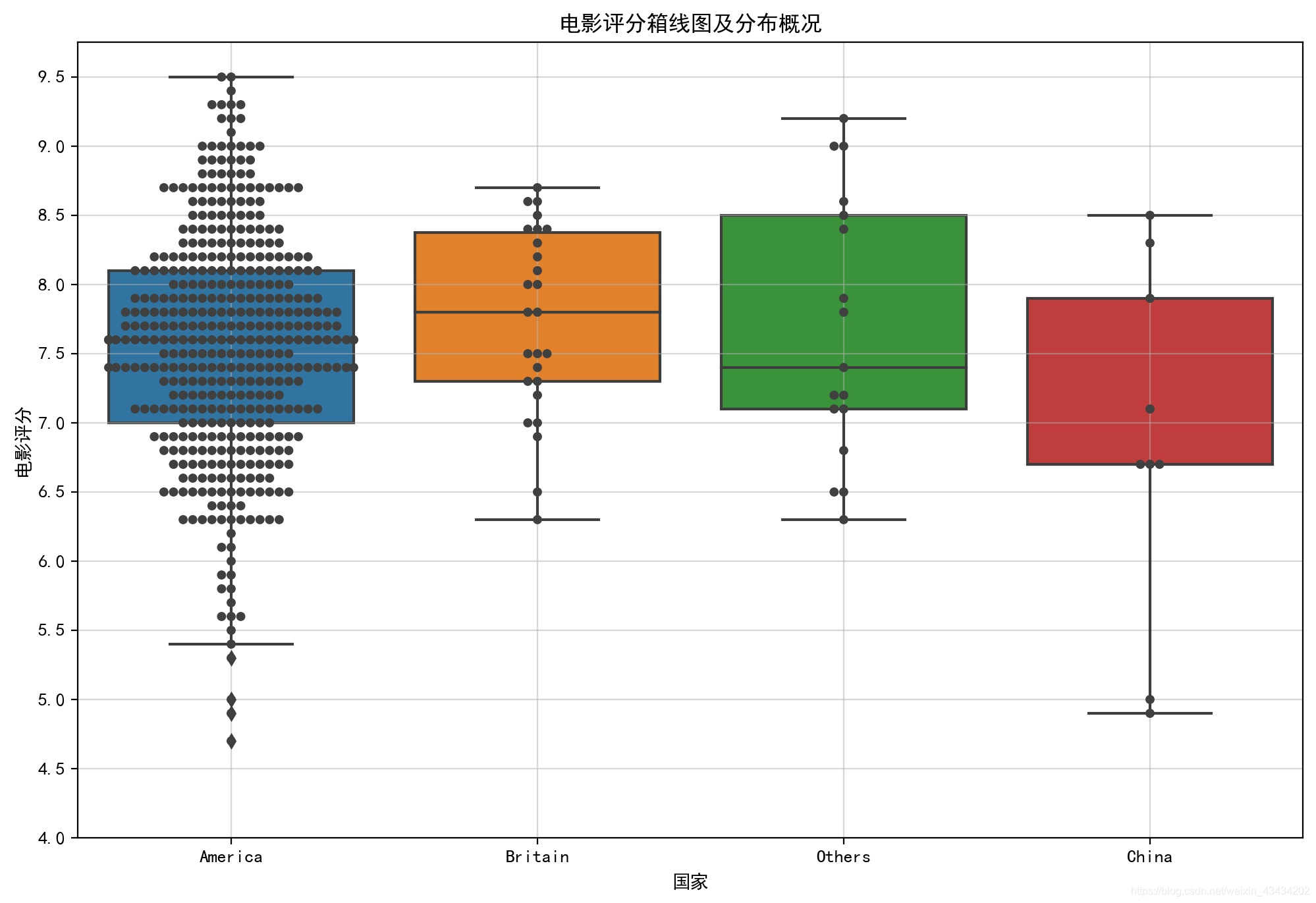
美国在电影方面的造诣堪称完美,排行榜中超九成的电影都是由美国制作的,同时生产的大片都时间长、质量好、评价高,但是也有一些评分比较低的电影上榜,可谓是萝卜青菜各有所爱
电影上映时间与地区的关系
电影上映时间的分布也十分广泛,我们用同样的方法,让时间以年代的方式出现即’2010s’,‘2000s’,‘1990s’,‘1980s’,1970s’,'others’六个时间段
df['movie_year'].value_counts()
def Time(t):
if t>=2010 and t<2020:
return '2010s'
elif t>=2000 and t<2010:
return '2000s'
elif t>=1990 and t<2000:
return '1990s'
elif t>=1980 and t<1990:
return '1980s'
elif t>=1970 and t<1980:
return '1970s'
else:
return 'other'
df['Time'] = df['movie_year'].map(Time)
散点图最大化的展示了电影上映时间的分布,而饼图更高的展示出电影上映年代的分布比例
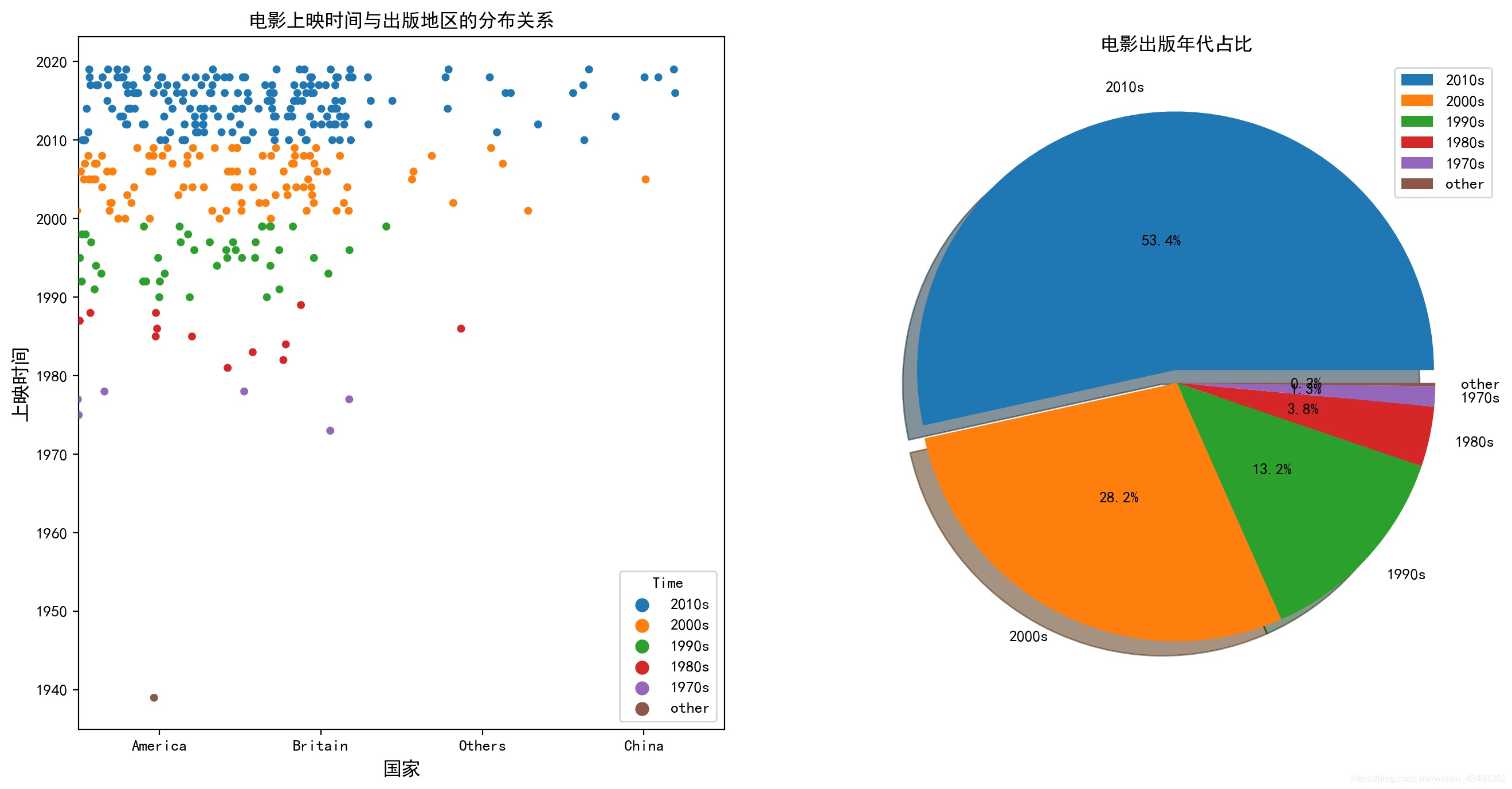
近20年上映的电影上榜的较多,占据了榜单的80%,不可否认人们生活条件变好是一个重要因素,但科技、人文进步也具有一定影响;榜单上也有许多上个世纪的电影,比如《泰坦尼克号》、《侏罗纪公园》、《狮子王》都是经典中的经典
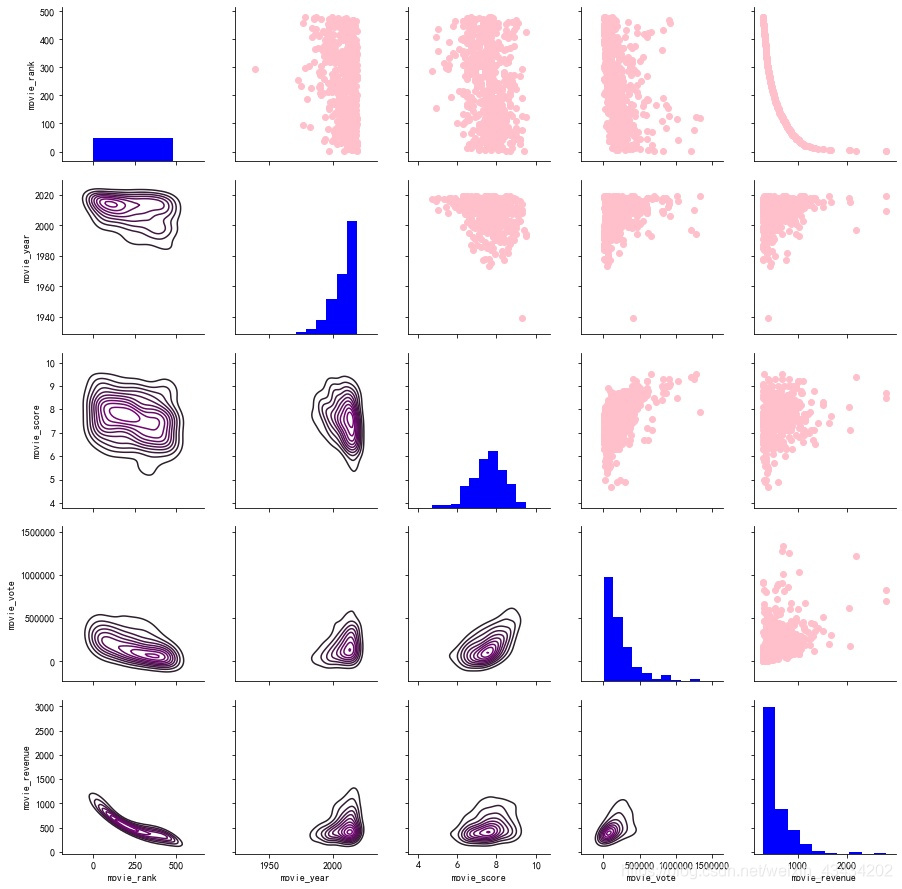
电影评分、投票人数、票房之间的联系
关于电影票房会有一个规律,.电影口碑好→评价人数多→评分高→观看人数多→电影票房高,这一套龙服务也决定了一部电影的地位如何
电影评分和评价人数的线性关系比较明显,评分越高的电影恰恰评价人数也多,在互联网世界,电影口碑的传播速度极快,具有明显因果效应。而对于同评分的电影票房有时差异很大,不能说电影评分对票房无影响,但是其中演员阵容,电影体裁等等都会有一定的影响
画对图PairGrid
这份数据中,可能数据元素之间都会存在些关联,互相影响,画对图恰恰能够展现出这种“可能存在的关联”
词云图
想看大咖怎么办?上词云呀!

不知道有没有你喜欢的明星呢,反正我雷神克里斯已经占领了C位
总结
电影的好坏不能点点单单用票房判定,但是票房高的电影确实它的独到之处,演员阵容虽说很重要,可演员的演技和选题不应该才是一部大片的立足之本嘛,必须要吹一波《肖申克的救赎》,虽然票房不高,但依靠着口碑的它涅槃重生,成为了电影史上的经典
!!!有需要的小伙伴可以私信要数据和源码!!!
