页面分析
打开淘宝搜索卫衣男
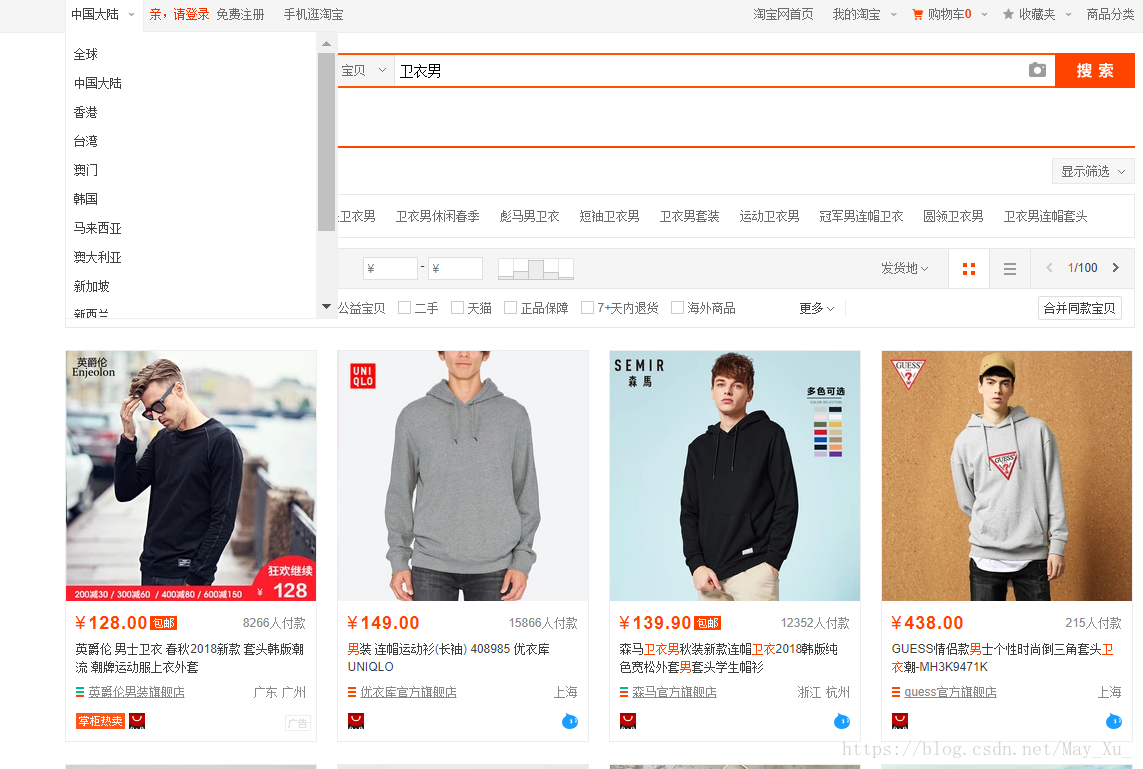
查看源代码
我们这里可以找到几个关键词

通过分析我们可以找到价格,邮费,商家地址,付款人数,商家ID,店铺名称。
分析URL
我们可以看到
通过对比,我们就能发现每一页的url最后面的数字都是44的倍数,因此程序可以写成:
url="https://s.taobao.com/search?initiative_id=tbindexz_20170306&ie=utf8&spm=a21bo.2017.201856-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5-e&commend=all&imgfile=&q=%E5%8D%AB%E8%A1%A3%E7%94%B7&suggest=0_2&_input_charset=utf-8&wq=%E5%8D%AB%E8%A1%A3&suggest_query=%E5%8D%AB%E8%A1%A3&source=suggest&bcoffset=0&ntoffset=6&p4ppushleft=1%2C48&s="+str(flag)我的思路:
1,复制cookie模拟登陆,多弄几个代理IP防止反爬虫
2,观察每个页面的url变化,找寻规律
3,把每个功能切割成函数来写
4,把正则写出来的数据迭代出来
from urllib import request
import random
import re
proxy_list = [ #列表中存放的是dict类型
{"http":"150.95.211.160:3128"},
{"http":"104.248.115.1:8080"},
{"http":"27.208.28.236:8060"},
{"http":"195.235.204.60:3128"},
{"http":"111.165.99.58:8060"},
{"http":"218.58.193.98:8060"},
{"http":"140.143.96.216:80"},
{"http":"114.243.211.34:8060"},
]
proxy_handler_list=[]
for proxy in proxy_list: #创建ProxyHandler
proxy_handler = request.ProxyHandler(proxy)
proxy_handler_list.append(proxy_handler)
opener_list = []
for proxy_handler in proxy_handler_list:
opener = request.build_opener(proxy_handler)#创建Opener
opener_list.append(opener)
headers={
"""
这里直接复制自己的cookie,用字典格式
"""
}
opener=random.choice (opener_list)
request.install_opener (opener)# 安装Opener
def response(url):
req = request.Request(url,headers=headers)
rsp = request.urlopen(req)
html = rsp.read().decode()
respon = re.compile(r'"view_price":"(.*?)".*?"view_fee":"(.*?)".*?"item_loc":"(.*?)".*?"view_sales":"(.*?)".*?"user_id":"(.*?)".*?"nick":"(.*?)"',re.S)
items = re.findall(respon,html)
for item in items:
yield {
"价格":item[0],
"邮费":item[1],
"商家地址":item[2],
"付款人数":item[3],
"商家ID":item[4],
"店铺名称":item[5]
}
def write_file(res):
res = str(res)
with open("taobao.txt","a",encoding="gbk") as f:
f.write(res+"\n")
f.close()
def main(flag):
url="https://s.taobao.com/search?initiative_id=tbindexz_20170306&ie=utf8&spm=a21bo.2017.201856-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5-e&commend=all&imgfile=&q=%E5%8D%AB%E8%A1%A3%E7%94%B7&suggest=0_2&_input_charset=utf-8&wq=%E5%8D%AB%E8%A1%A3&suggest_query=%E5%8D%AB%E8%A1%A3&source=suggest&bcoffset=0&ntoffset=6&p4ppushleft=1%2C48&s="+str(flag)
for res in response(url):
print(res)
write_file(res)
if __name__ == '__main__':
for i in range(1,4):
i*=44
main(i)