1.采用Chrome无头浏览模式,后台自动运行
2.函数结构化,易于扩展改变
3.异常重启,防止崩溃
已经封装完毕
import re
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support import expected_conditions as EC
from pyquery import PyQuery as pq
# 创建chrome参数对象
chrome_options = Options()
chrome_options.add_argument('--headless')
brower = webdriver.Chrome(chrome_options=chrome_options)
wait = WebDriverWait(brower, 10)
def search(word):
print('开始爬取淘宝:\n\n正在翻页:1')
try:
brower.get('https://www.taobao.com')
# 等待主页搜索框和搜索按钮出现
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#q'))
)
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_TSearchForm > div.search-button > button'))
)
# 输入Aj,并且点击搜索按钮
input.send_keys(word)
submit.click()
# 等待搜索页页数出现
total = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.total'))
)
get_products()
return total.text
except TimeoutException:
return search()
def next_page(page_number):
print('正在翻页:' + str(page_number))
try:
# 等待页码输入框和确定按钮出现
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.form > input'))
)
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit'))
)
# 输入页码,并且点击确定按钮
input.clear()
input.send_keys(page_number)
submit.click()
# 判断是否翻页成功
wait.until(
EC.text_to_be_present_in_element((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > ul > li.item.active > span'), str(page_number))
)
get_products()
except TimeoutError:
next_page(page_number)
def get_products():
# 获取页面内所有产品信息
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-itemlist .items .item')))
html = brower.page_source
doc = pq(html)
items = doc('#mainsrp-itemlist .items .item').items()
for item in items:
product = {
'image': item.find('.pic .img').attr('src'),
'price': item.find('.price').text()[2:],
'deal': item.find('.deal-cnt').text()[:-3],
'title': item.find('.title').text(),
'shop': item.find('.shop').text(),
'location': item.find('.location').text(),
}
print(product, '\n')
print('')
def main():
try:
total = search(input('输入淘宝关键词:'))
total = int(re.compile('(\d+)').search(total).group(1))
for i in range(2, total + 1):
next_page(i)
except Exception:
print('程序崩溃')
finally:
brower.close()
if __name__ == '__main__':
main()
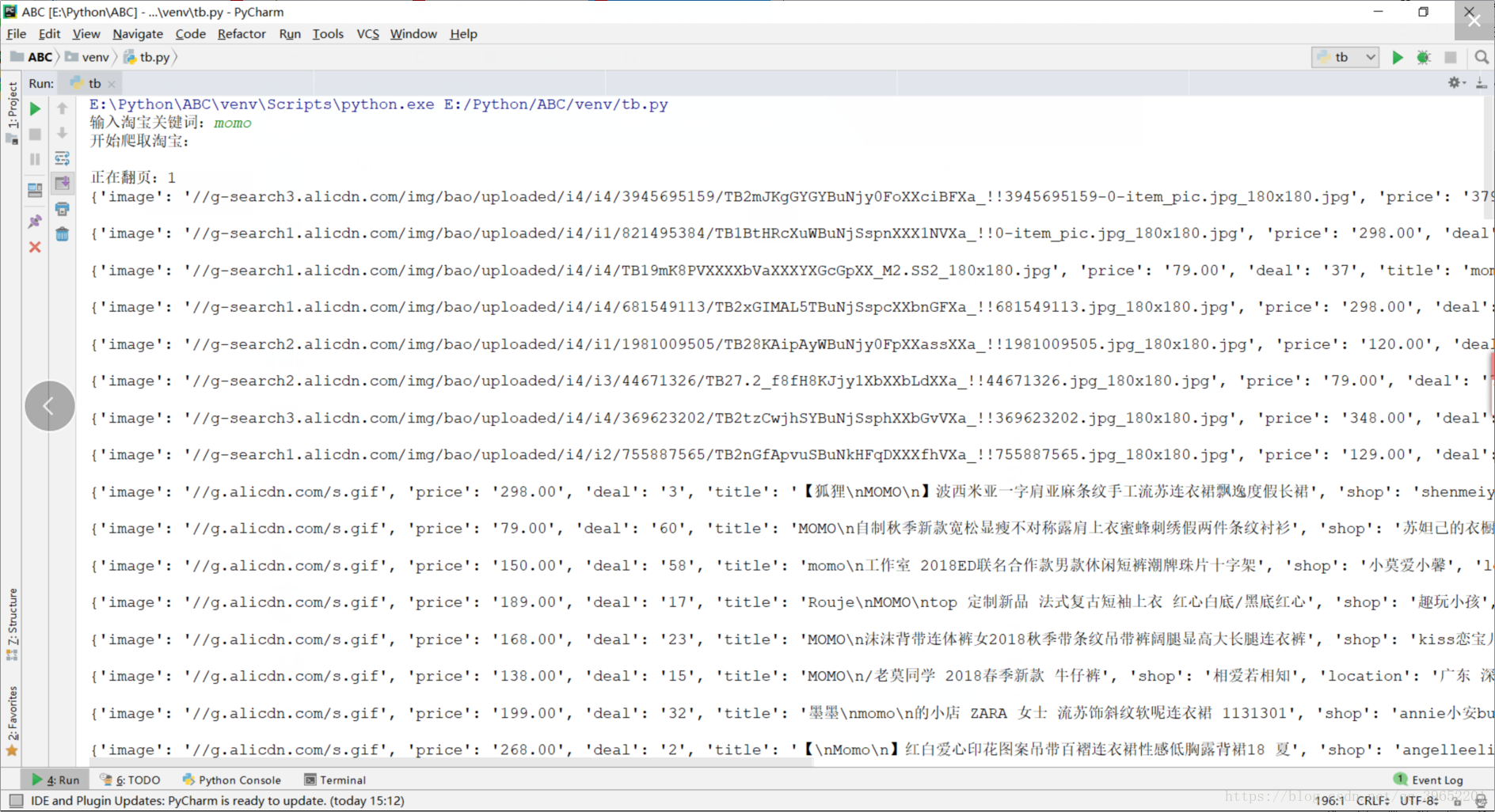
运行截图: