介绍
该博文主要讲解利用python爬取淘宝页面上的商品内容,包括款式和价格~~~
源代码
需要chorm浏览器,以及对应的chormdriver,这些百度上可以直接搜到,除此之外还需要安装selenium库,pip install ~
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.set_page_load_timeout(30)
browser.get('http://www.17huo.com/search.html?sq=2&keyword=%E7%BE%8A%E6%AF%9B')
page_info = browser.find_element_by_css_selector('body > div.wrap > div.pagem.product_list_pager > div')
# print(page_info.text)
pages = int((page_info.text.split(',')[0]).split(' ')[1])
for page in range(pages):
url = 'http://www.17huo.com/?mod=search&sq=2&keyword=%E7%BE%8A%E6%AF%9B&page=' + str(page + 1)
browser.get(url)
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(3) # 不然会load不完整
goods = browser.find_element_by_css_selector('body > div.wrap > div:nth-child(2) > div.p_main > ul').find_elements_by_tag_name('li')
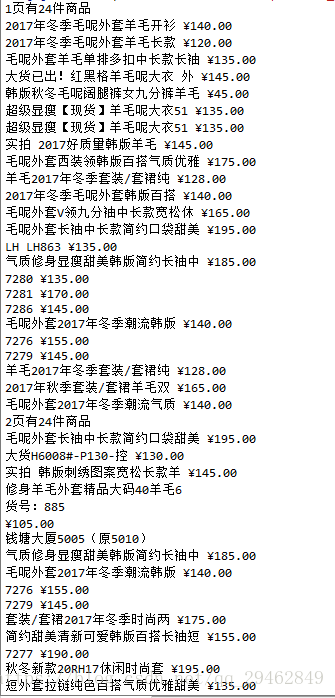
print('%d页有%d件商品' % ((page + 1), len(goods)))
for good in goods:
try:
title = good.find_element_by_css_selector('a:nth-child(1) > p:nth-child(2)').text
price = good.find_element_by_css_selector('div > a > span').text
print(title, price)
except:
print(good.text)
爬取的结果
这里只是把结果输出,有需要的话可以保存成json文件或者xml文件以便后续处理,在这里不再多说。