一、主题式网络爬虫设计方案
1.主题式网络爬虫名称:豆瓣电影数据评分
2.主题式网络爬虫爬取的内容:豆瓣电影的榜单数字、名称、评星、评分、评论数量。
3.设计方案概述:
实现思路:使用requests爬取网页,然后实现数据解析,借助pandas将数据写出到Excel;把数据进行清洗处理;然后对清洗的数据进行分析,进行相关的可视化;最后,将这些代码进行整理。
技术难点:网页内容繁杂,刚开始接触,不太好懂;对数据的解析有些漫长;可视化中,数据不匹配。
二、主题页面的结构特征分析
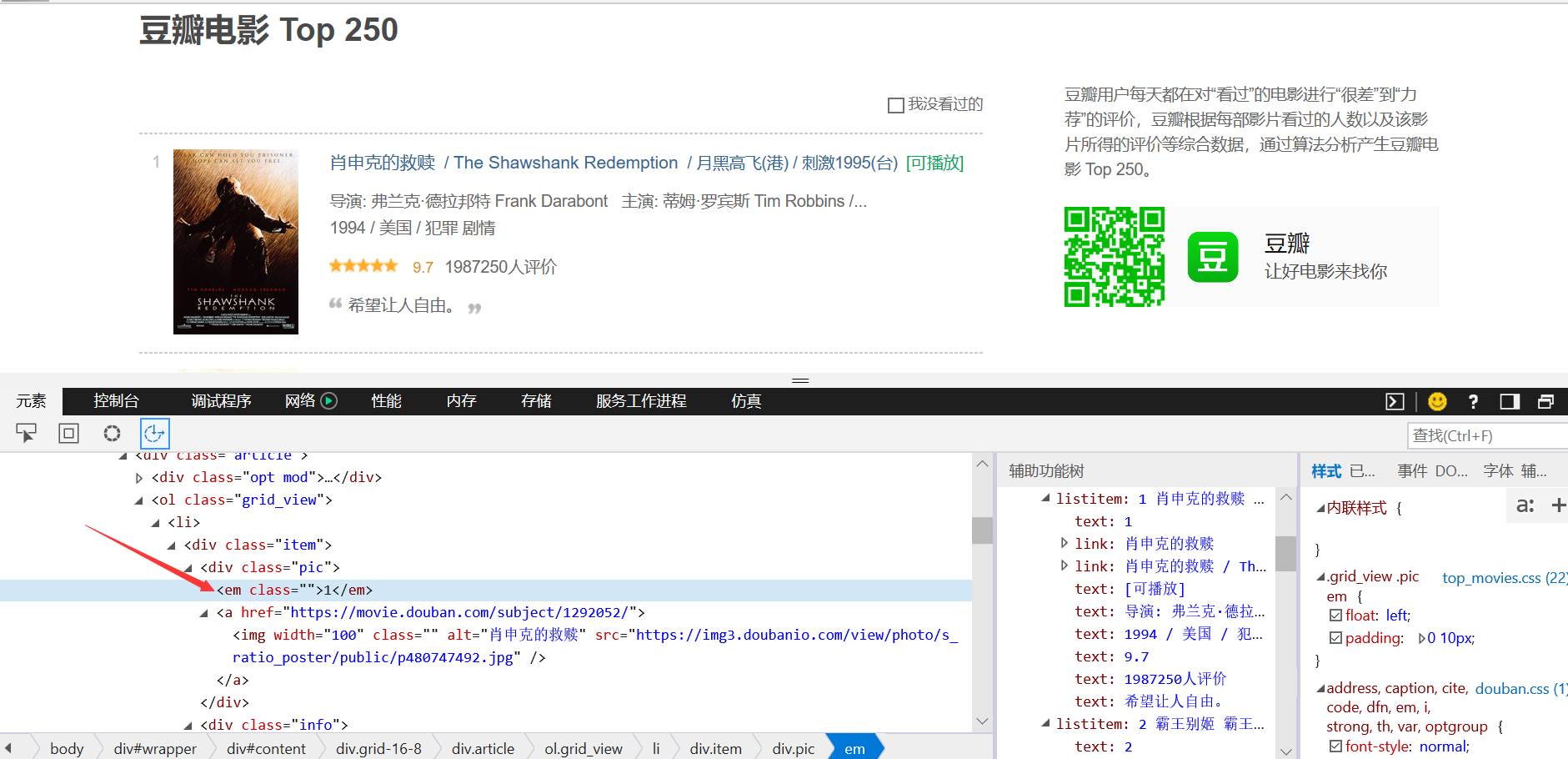
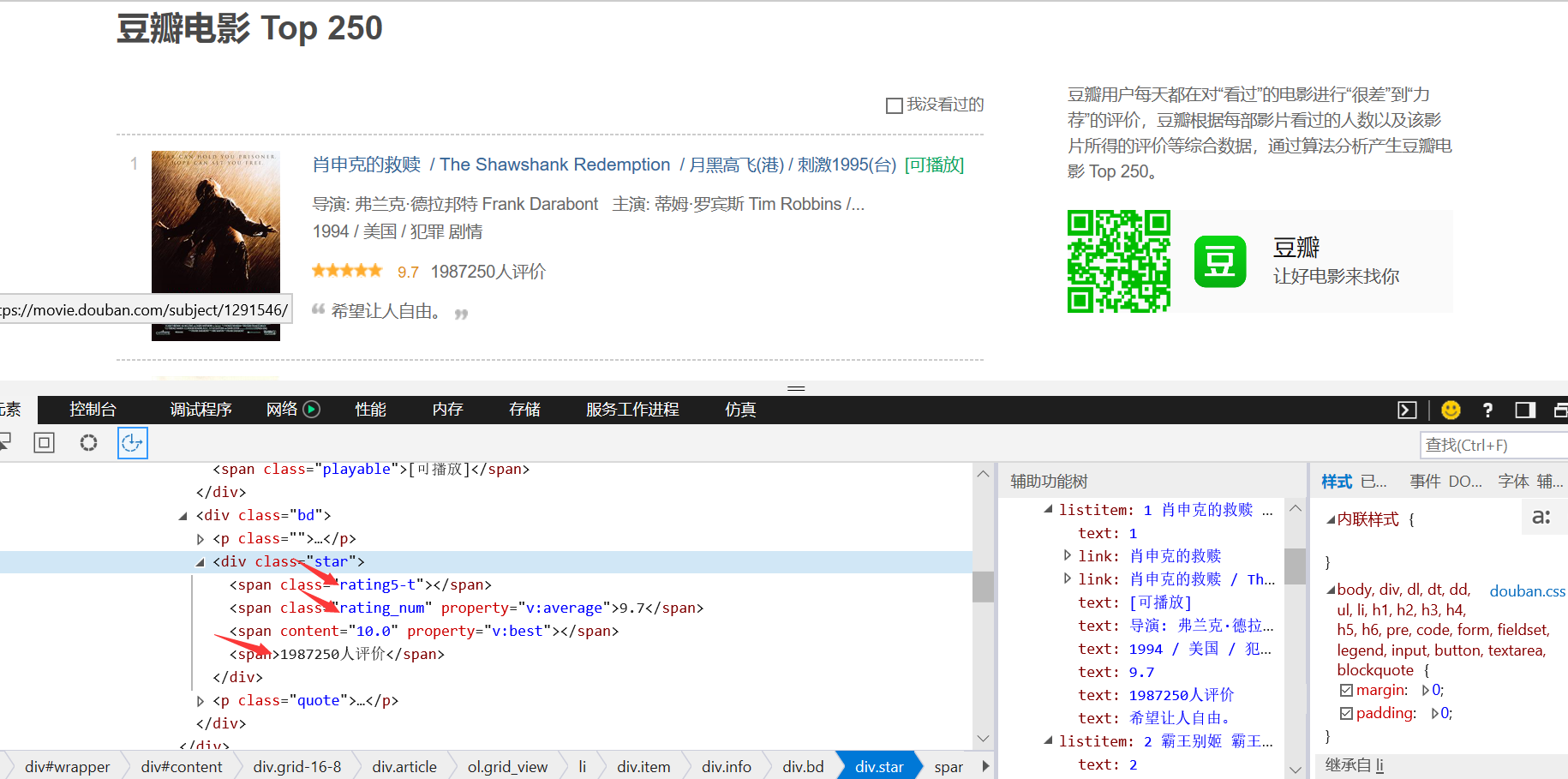
1.打开开发者工具,查找我所需的内容,以及它所在的标签;在 div class="item" 中查找。
2.进行页面解析

3分析节点
三、网络爬虫程序设计
1.数据爬取与采集
#获取页面 import requests from bs4 import BeautifulSoup import pandas as pd # 构造分页数字列表 page_indexs = range(0, 250, 25) list(page_indexs) def download_all_htmls(): """ 下载所有列表页面的HTML,用于后续的分析 """ htmls = [] for idx in page_indexs: url = f"https://movie.douban.com/top250?start={idx}&filter=" print("craw html:", url) r = requests.get(url, headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"}) if r.status_code != 200: raise Exception("error") htmls.append(r.text) return htmls htmls = download_all_htmls() htmls[0] def parse_single_html(html): """ 解析单个HTML,得到数据 @return list({"link", "title", [label]}) """ soup = BeautifulSoup(html, 'html.parser') article_items = ( soup.find("div", class_="article") .find("ol", class_="grid_view") .find_all("div", class_="item") ) datas = [] for article_item in article_items: rank = article_item.find("div", class_="pic").find("em").get_text() info = article_item.find("div", class_="info") title = info.find("div", class_="hd").find("span", class_="title").get_text() stars = ( info.find("div", class_="bd") .find("div", class_="star") .find_all("span") ) rating_star = stars[0]["class"][0] rating_num = stars[1].get_text() comments = stars[3].get_text() datas.append({ "rank":rank, "title":title, "rating_star":rating_star.replace("rating","").replace("-t",""), "rating_num":rating_num, "comments":comments.replace("人评价", "") }) return datas import pprint pprint.pprint(parse_single_html(htmls[0])) # 执行所有的HTML页面的解析 all_datas = [] for html in htmls: all_datas.extend(parse_single_html(html)) all_datas len(all_datas) df = pd.DataFrame(all_datas) df.to_excel("豆瓣电影TOP250.xlsx")
#保存成功
2.对数据进行清洗和处理
#数据读取
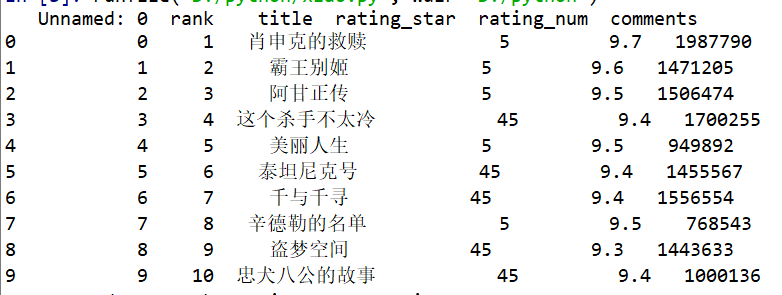
df= pd.read_excel('D:\python\\豆瓣电影TOP250.xlsx',encoding='gbk')
print(df.head(10))
#删除无效行列
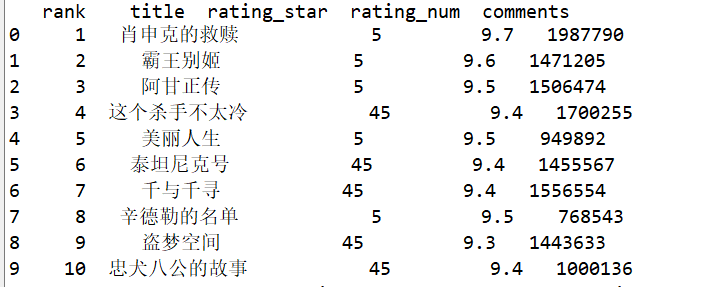
df.drop('Unnamed: 0',axis=1,inplace=True)
print(df.head(10))
#重复值处理
print(df.duplicated())
#异常值处理
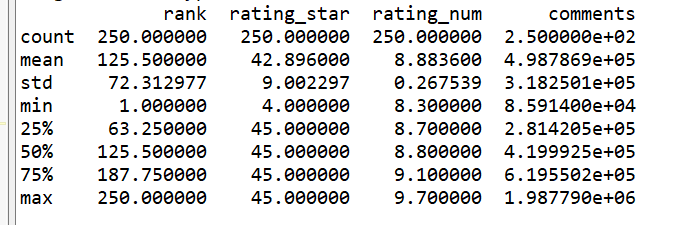
print(df.describe())
4.数据分析与可视化
#导入各库 import numpy as np import pandas as pd import matplotlib.pyplot as plt import sklearn import seaborn as sns from sklearn.linear_model import LinearRegression from mpl_toolkits.mplot3d import Axes3D
(1)
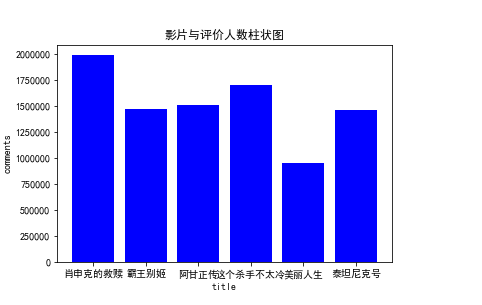
#绘制垂直柱状图 x = df.title[:6] y = df.comments[:6]#由于数据太多,只列了前几个 plt.bar(x,y,color="b") plt.xlabel("title") plt.ylabel("comments") plt.title('影片与评价人数柱状图') plt.show()
(2)
#散点图 x = df.rating_num y = df.comments plt.scatter(x,y,color="g",label="散点") plt.xlabel("rating_num") plt.ylabel("comments") plt.title('评分与评价人数散点图') plt.show()

(3)
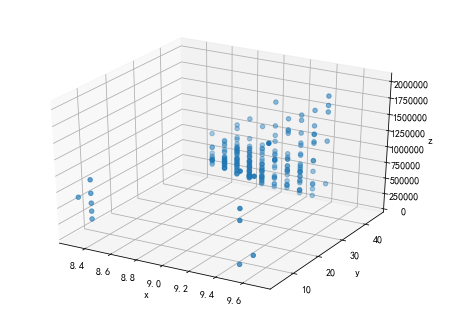
#绘制3D散点图 fig=plt.figure() ax=Axes3D(fig) x=df.rating_num y=df.rating_star z=df.comments ax.scatter(x,y,z) ax.set_xlabel('x') ax.set_ylabel('y') ax.set_zlabel('z')
plt.show() #由于评价人数过多,所以数据比较贴近
(4)
#绘制折线图 x = df.title[:6] y = df.comments[:6] #探究前几影片评价人数的关系 plt.scatter(x,y) plt.xlabel("title") plt.ylabel("comments") plt.plot(x,y,'y-*') plt.title('影片与评价人数折线图') plt.show()

(5)
#绘制盒图 x = df.rating_num y = df.comments sns.boxplot(x='rating_num',y='comments',data=df)

(6)
#绘制直方图
sns.distplot(df['rating_num'])
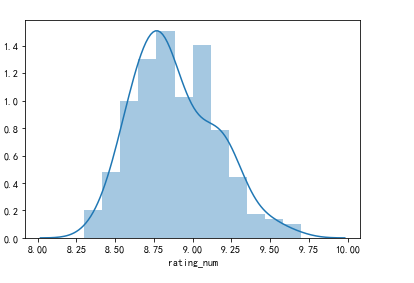
(7)
#绘制单变量小提琴图 sns.violinplot(df['rating_num'])
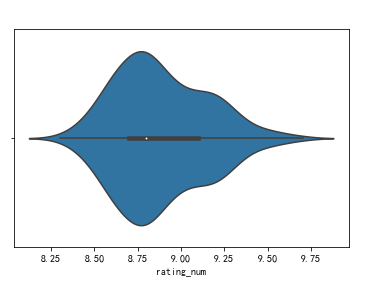
(8)
#绘制热力图 data=df.pivot('comments','rating_num','rating_star') sns.heatmap(data)
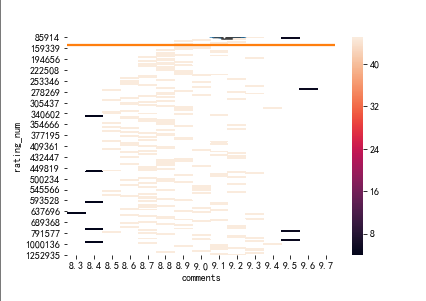
5.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变量之间的回归方程
df= pd.read_excel('D:\python\\豆瓣电影TOP250.xlsx',encoding='gbk') df.drop('title',axis=1,inplace=True) #由于title里的文字无法进行数据分析,所以进行删除 X=df.drop("rating_num",axis=1) predict_model=LinearRegression() predict_model.fit(X,df['rating_num'])#训练模型 print("回归系数为:",predict_model.coef_)#判断相关性 #呈现回归图 sns.regplot(df.comments ,df.rating_num)
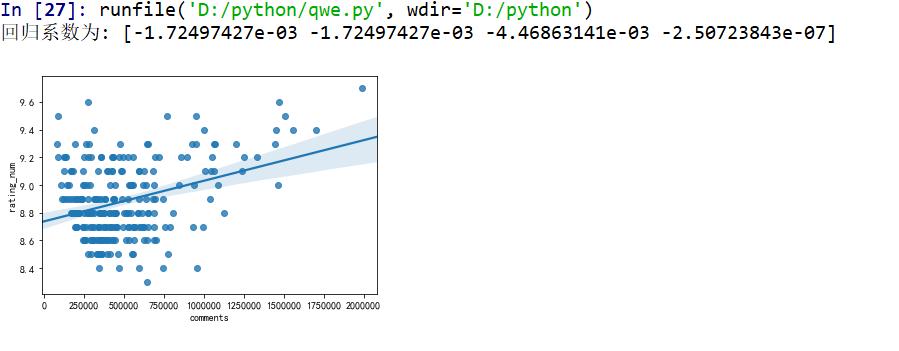
7.将以上各部分的代码汇总,附上完整程序代码
import requests from bs4 import BeautifulSoup import pandas as pd # 构造分页数字列表 page_indexs = range(0, 250, 25) list(page_indexs) def download_all_htmls(): """ 下载所有列表页面的HTML,用于后续的分析 """ htmls = [] for idx in page_indexs: url = f"https://movie.douban.com/top250?start={idx}&filter=" print("craw html:", url) r = requests.get(url, headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"}) if r.status_code != 200: raise Exception("error") htmls.append(r.text) return htmls htmls = download_all_htmls() htmls[0] def parse_single_html(html): """ 解析单个HTML,得到数据 @return list({"link", "title", [label]}) """ soup = BeautifulSoup(html, 'html.parser') article_items = ( soup.find("div", class_="article") .find("ol", class_="grid_view") .find_all("div", class_="item") ) datas = [] for article_item in article_items: rank = article_item.find("div", class_="pic").find("em").get_text() info = article_item.find("div", class_="info") title = info.find("div", class_="hd").find("span", class_="title").get_text() stars = ( info.find("div", class_="bd") .find("div", class_="star") .find_all("span") ) rating_star = stars[0]["class"][0] rating_num = stars[1].get_text() comments = stars[3].get_text() datas.append({ "rank":rank, "title":title, "rating_star":rating_star.replace("rating","").replace("-t",""), "rating_num":rating_num, "comments":comments.replace("人评价", "") }) return datas import pprint pprint.pprint(parse_single_html(htmls[0])) # 执行所有的HTML页面的解析 all_datas = [] for html in htmls: all_datas.extend(parse_single_html(html)) all_datas len(all_datas) df = pd.DataFrame(all_datas) df.to_excel("豆瓣电影TOP250.xlsx") #数据清洗 import pandas as pd
df= pd.read_excel('D:\python\\豆瓣电影TOP250.xlsx',encoding='gbk') print(df.head(10))
#删除无效行列
df.drop('Unnamed: 0',axis=1,inplace=True) print(df.head(10))
#重复值处理
print(df.duplicated())
#异常值处理
print(df.describe()) #数据分析与可视化
#导入所需的库 import numpy as np import pandas as pd import matplotlib.pyplot as plt import sklearn import seaborn as sns from sklearn.linear_model import LinearRegression #绘制垂直柱状图 x = df.title[:6] y = df.comments[:6]#由于数据太多,只列了前几个 plt.bar(x,y,color="b") plt.xlabel("title") plt.ylabel("comments") plt.title('影片与评价人数柱状图') plt.show() #散点图 x = df.rating_num y = df.comments plt.scatter(x,y,color="g",label="散点") plt.xlabel("rating_num") plt.ylabel("comments") plt.title('评分与评价人数散点图') plt.show() #绘制3D散点图 fig=plt.figure() ax=Axes3D(fig) x=df.rating_num y=df.rating_star z=df.comments ax.scatter(x,y,z) ax.set_xlabel('x') ax.set_ylabel('y') ax.set_zlabel('z') #由于评价人数过多,所以数据比较贴近 plt.show() #绘制折线图 x = df.title[:6] y = df.comments[:6] #探究前几影片评价人数的关系 plt.scatter(x,y) plt.xlabel("title") plt.ylabel("comments") plt.plot(x,y,'y-*') plt.title('影片与评价人数折线图') plt.show() #绘制盒图 x = df.rating_num y = df.comments sns.boxplot(x='rating_num',y='comments',data=df) #绘制直方图 sns.distplot(df['rating_num']) #绘制单变量小提琴图 sns.violinplot(df['rating_num']) #绘制热力图 data=df.pivot('comments','rating_num','rating_star') sns.heatmap(data) df= pd.read_excel('D:\python\\豆瓣电影TOP250.xlsx',encoding='gbk') df.drop('title',axis=1,inplace=True) #由于title里的文字无法进行数据分析,所以进行删除 X=df.drop("rating_num",axis=1) predict_model=LinearRegression() predict_model.fit(X,df['rating_num'])#训练模型 print("回归系数为:",predict_model.coef_)#判断相关性 #呈现回归图 sns.regplot(df.comments ,df.rating_num)
四、结论
1.结论:经过这次的作业,我知晓了电影行业评价好的,基本热议度高,但也有一些不一定。我学习到了,每次输出结果报错,可以上网搜一下它错的原因,这样就会对自己的代码错误有了更清晰的认识。不要怕有错误,及时修改就好。
2.小结:对于这次的作业,作为一个纯纯的新手来说,真的不容易。我也花了不少时间去研究它,慢慢的学习,发现python也挺不简单的。不过,我也收获不少,希望以后的学习中可以有所进步。