小文 | 公众号 小文的数据之旅
上一期介绍了回归模型中最简单的线性回归模型的理论知识以及分别从最小二乘法、批量梯度下降法、随机梯度下降法和小批量梯度下降法求得线性回归的最优解,今天将介绍分类模型中最简单的逻辑回归模型。逻辑回归模型听起来像是回归模型,那么它是怎么成为分类模型的呢?
首先还是从回归模型说起,现在假设一个函数g(x)且 的一个连续值 ,x有n个特征,得到:
;那么怎么利用g(x)来解决分类任务呢?往往我们会取一个阈值,当大于这个阈值时为正类,小于阈值时为负类。这个阈值的选取往往会取值域的中间值,也就是0.5,即:当g(x) > 0.5时为正类,当g(x) < 0.5时为负类,g(x) = 0.5时任意判断,也就构成了单位跃界函数。
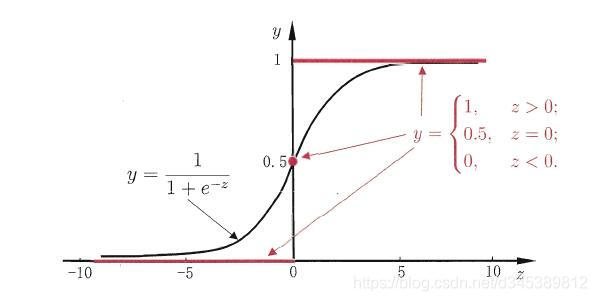
单位跃界函数可以作为二分类的一个模型,但是模型并不是连续可导模型,对于求优解并不友好,于是往往会使用更为友好的sigmoid函数替代。
Sigmoid函数:
sigmoid函数有一个非常好的性质,即当z趋于正无穷时, y趋于1,当z趋于负无穷时,y趋于0,非常适合分类概率模型。它还有一个很好的导数性质, ,在求解过程会用到。sigmoid函数表达式为:
;那么令g(x) = z,得到:
那么,
即
至此,逻辑回归的一般表达式已经推导出来了,那么该怎么理解这个表达式呢?
y为正类样本数量,也就是正类发生的概率;1-y为负类样本数量,也就是负类发生的概率;那么 就是正负样本数量之比,也就是正负样本发生的概率比,所以正负样本发生的概率比的对数与数据集X成线性相关。
理想状态下,正负样本数量相等,也就是正负样本发生概率相等,即 ,也就是
,这跟我们一开始将g(x)的分类阈值设为0.5相符合。
根据逻辑回归的表达式,如果知道数据集X以及相对应的系数k,就可以求得正负样本发生的概率,那么怎么通过X数据集求解对应的k值呢?往往通过对损失函数求最优解就可以。
线性回归是连续的,所以可以使用模型误差的的平方和来定义损失函数。但是逻辑回归不是连续的,自然线性回归损失函数定义的经验就用不上了。不过我们可以用似然函数来推导出我们的损失函数。
设 ,则
那么似然函数就可以写成 ,然后求解L(k)的极大值就ok了。
求解过程如下:
又因为 ,
所以
用sigmoid函数的一个导数性质, 可以更快得到相同的结果!不信?!可以验证一下!然后把
代入
中,可得:
因为要求 的极大值,那么用梯度上升法求解参数k:
,其中
即
至此求得最优解k。
— end —
小文的数据之旅
戳右上角「+关注」获取最新share
如果喜欢,请分享or点赞
