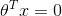一.特征函数
对应分类问题,我们先针对二分类问题进行讨论,对应计算机而言,分类即将数据按其特征值不同分为不同的集合,仅对应二分类问题,我们只需考虑分为:正类和负类,为此我们引入特征函数。
-
y=1 — 代表二分类中的正类
-
y=0 — 代表二分类中的反类
这是特殊函数在集合意义上的理解,如果换成概率角度上的理解呢?
对应二分类问题(监督学习),我们如果设置一个标准值,按照NG的说法设置为1(正类),那么特征函数可以这样理解: -
y=1 — 代表二分类中的正类出现的概率为100%(必然事件)
-
y=1 — 代表二分类中的正类出现的概率为0(不可能事件)
注意:这里的y是指训练集中的数据,是给定值并非模型预测值
二.逻辑回归函数(sigmoid函数)
特征函数的引入是对于训练集内数据分类的描述标准,那么,对于模型预测值我们又应该以什么样的标准来衡量呢?
为此,我们引入sigmoid函数:

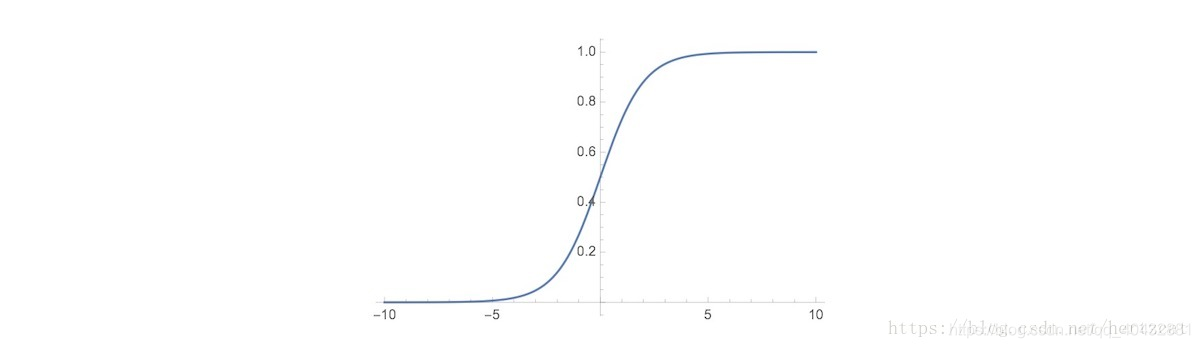
接下来我们来分析这个函数的作用:
这个函数是将g(z)的范围压缩至【0,1】区间内,我们知道,在线性回归算法中,假设函数被定义为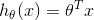 此时假设函数的取值范围可以为
此时假设函数的取值范围可以为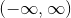 在二分类中,输出 y 的取值只能为 0 或者 1,
在二分类中,输出 y 的取值只能为 0 或者 1,
在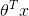 之外包裹一层 Sigmoid 函数,使之取值范围属于 (0,1)
之外包裹一层 Sigmoid 函数,使之取值范围属于 (0,1)
这样我们就能从概率的角度来衡量得出的模型预测值h(x)了,其意义便是通过以训练好的模型预测出此组数据为正类的概率:
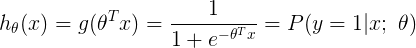
对应得到此组数据为负类的概率P(y=0|x;θ) = 1-h(x)
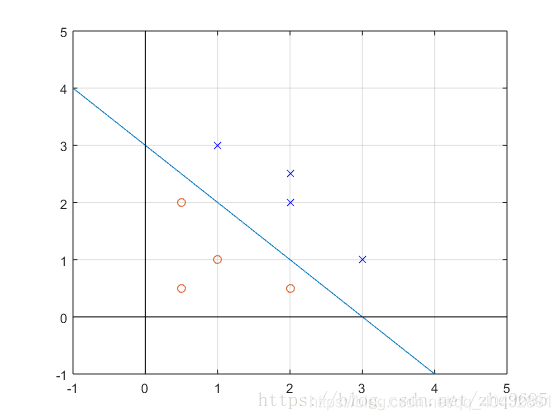
三. 决策边界(Decision Boundary)
根据以上假设函数表示概率,我们可以推得:
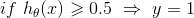 θ’x>=0
θ’x>=0
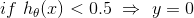 θ’x<0
θ’x<0
由此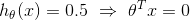 可得出决策边界
可得出决策边界