版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/shankezh/article/details/78731765
写在前面:
文中的基本公式都是我从网上截图的,公式编辑器使用的实在是太烂了,推导过程我使用的是手写,程序中所使用的数据,也是从网上下的,代码是自己写的。
简单介绍:
逻辑回归主要用于二分类问题,即将答案分为两类,回答你是或者不是,数学表示为{0,1},能很好的表现这一特性的,就是使用logistics函数,Logistic函数图像很像一个“S”型,所以该函数又叫 sigmoid 函数,这个算法主要是通过已有的数据,进行反推,然后推导出权重参数,并通过优化方法,减少误差,从而找到一个相对的最优的参数,生成一个分类模型。
算法特点:
逻辑回归属于有监督学习的一种。
逻辑回归也可以做多分类问题,处理方法是将需要确认的数据变成一类,其它数据共同当做一类,分完这类后,再去按照第一次分类的方法去分类剩下的数据,周而复始,有N个类别,那么就必须至少计算N-1个回合(回合是指每一次分类,不是指分类时候调优的迭代次数)。
逻辑回归的参数方程选择比较麻烦,因为要依据数据的分布特性,选择最优的参数方程。
原始特征的数据大小,直接影响到迭代次数。
学习逻辑回归的基本流程:
1、了解基础知识
2、推导公式
3、完成基础代码,并可以看到基础效果
4、正则化
基本方程及概念(学习逻辑回归,我们至少要熟悉以下的数学知识):
a)逻辑回归方程:
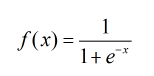
其中,x 等于:
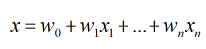
wT = (w0,w1,w2...,wn)表示一个一维的权重参数矩阵,很多人也喜欢用Theta(符号:θ )表示,他们是一个意思。x = (x1,x2,...,xn),因变量,也就是我们的特征值,也是一维矩阵。
b)最大似然估计概念:
极大似然估计又称最大概似估计或最大似然估计。
它是建立在极大似然原理的基础上的一个统计方法,极大似然原理的直观想法是,一个随机试验如有若干个可能的结果A,B,C,... ,若在一次试验中,结果A出现了,那么可以认为实验条件对A的出现有利,也即出现的概率P(A)较大。极大似然原理的直观想法我们用下面例子说明。设甲箱中有99个白球,1个黑球;乙箱中有1个白球.99个黑球。现随机取出一箱,再从抽取的一箱中随机取出一球,结果是黑球,这一黑球从乙箱抽取的概率比从甲箱抽取的概率大得多,这时我们自然更多地相信这个黑球是取自乙箱的。一般说来,事件A发生的概率与某一未知参数 有关, 取值不同,则事件A发生的概率 也不同,当我们在一次试验中事件A发生了,则认为此时的 值应是t的一切可能取值中使 达到最大的那一个,极大似然估计法就是要选取这样的t值作为参数t的估计值,使所选取的样本在被选的总体中出现的可能性为最大。
极大似然估计,只是一种概率论在统计学的应用,它是参数估计的方法之一。说的是已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若干次试验,观察其结果,利用结果推出参数的大概值。极大似然估计是建立在这样的思想上:已知某个参数能使这个样本出现的概率最大,我们当然不会再去选择其他小概率的样本,所以干脆就把这个参数作为估计的真实值。
当然极大似然估计只是一种粗略的数学期望,要知道它的误差大小还要做区间估计。
c)常见的损失函数
1.0-1损失函数 (0-1 loss function)
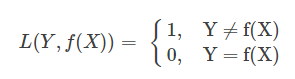
2.平方损失函数(quadratic loss function)
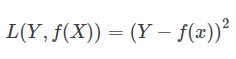
3.绝对值损失函数(absolute loss function)
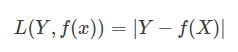
4.对数损失函数(logarithmic loss function) 或对数似然损失函数(log-likehood loss function)
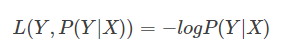
逻辑回归中,采用的则是对数损失函数。如果损失函数越小,表示模型越好。
d)后验概率
后验概率是指在得到“结果”的信息后重新修正的概率,是“执果寻因”问题中的"果"。先验概率与后验概率有不可分割的联系,后验概率的计算要以先验概率为基础 。
事情还没有发生,要求这件事情发生的可能性的大小,是先验概率。事情已经发生,要求这件事情发生的原因是由某个因素引起的可能性的大小,是后验概率。
e)梯度下降公式
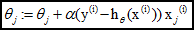
Q&A:
Q:根据现有的公式,如何体现出预测或者是分类?
A:举出一个例子,假设我们预测一个人会不会还贷款,我们从多个角度分析(也可以是业内从业者的经验分析),认为还不还款的影响因素,取决于以下几个因素(1、个人房子的价值(x1);2、银行存款多少(x2);3、车子价值多少(x3);4、是否结婚(x4)、5、银行信用卡是否存在违约记录(x5)),以上是我假设的,不是业内人士的分析;
那么,我们给出一个计算公式: w0+ w1*x1 + w2*x2 + w3*x3 + w4*x4 + w5*x5 = g(x) , 然后再将结果g(x)代入逻辑回归方程,f( g(x) ) = 1/( 1 + e^g(x) ) ,f(g(x)) >= 0.5,我们认为
会还款,f( g(x) )< 0.5,我们认为
不会还款 ,那么在这里,x1,x2,x3,x4,x5这些特征值也就是因变量,通过代入超平面参数方程g(x)中,再代入归一化函数f(x)中,就可以预测结果。
Q:但也发现了,虽然预测原理很简单,但是在参数方程中,w0,w1,w2,w3,w4,w5这几个参数我们并不知道,那么如何建立这个基本的参数模型?
A:利用现有数据,就是说我们手上有多个用户的过往数据,其中详细记载着他们过去是否还款,以及他们各自的特征数值,通过这些数据,进行反推。即已知f(g(x)) 和 x,推其中的权重参数wT。
Q:为什么网上及书籍中很多公式中的log函数没有写底数?
A:没有写底数就意味着表示log = ln,底数为e。
推导公式:
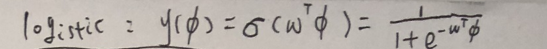

上两张图中φ和xT是相等的,表示的是特征矩阵,tn表示结果集,结果集中只有0和1
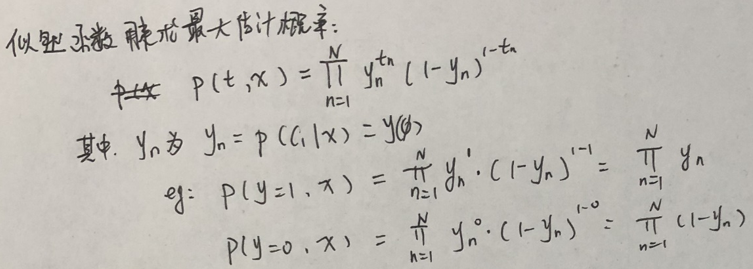
我们把问题转换成一个概率事件,原因是我们想知道,
发生这件事情的概率有多大,其中eg的两个例子,分别表示发生结果为1的事件的概率和发生结果为0事件的概率。
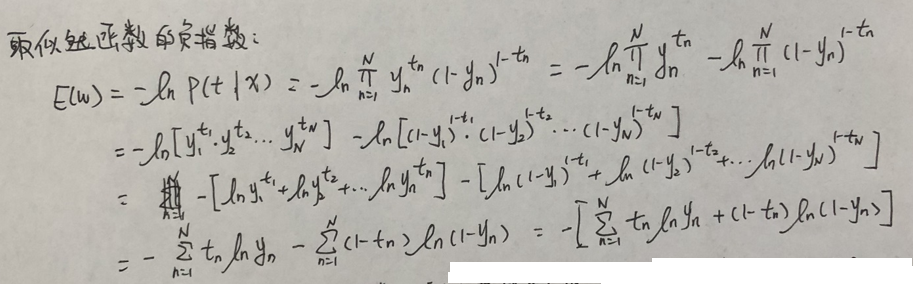
其实就是使用对数损失函数,其中,推出来的最后的结果,应该在网上和书上特别常见。
所以,既然是损失函数,那肯定是损失最小才是我们最想要的结果,那么,也就是说,我们把它转换成了一个求极值问题,如何求极值呢?当然是求导。
另外,这里用的是负指数,所以求最小值,如果用的是正指数,那么则应该是求最大值。
因为已知结果y和特征x,所以求得应该是权重系数w,那么对w求导即可:

右下角提示了如何对复合函数求导,复习一下。
接上式:

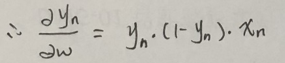
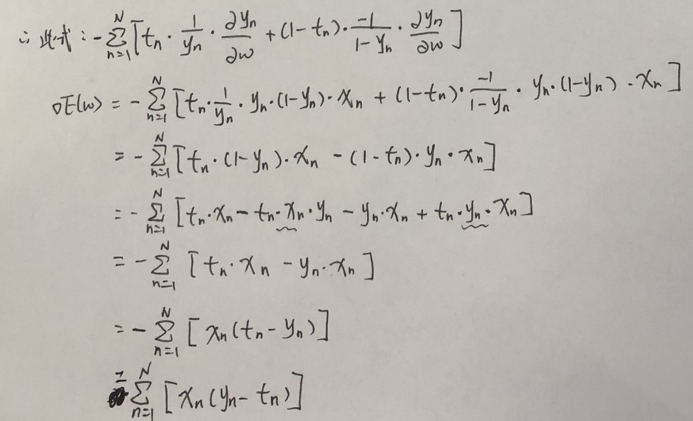
ok,推导完成, 这个结果,是不是对应了网上大量出现的公式,就那个让很多人不明白,为什么会得出这个结果的公式(下图我贴出网上的公式):
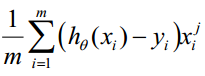
推导完成了,接下来我们就开始写基础代码了。
代码分为以下几步:
1、数据的获取和处理(这里使用从网上找的数据)
1.5、建立公式
2、配置参数
3、梯度下降
4、训练结果评估
5、画图看效果
首先,看一下我们用到的python库以及全局变量定义:
import cmath
import numpy as np
from matplotlib import pyplot as plt
#数据集坐标(特征),结果
D_Features =[]
D_Result = []
#设定梯度下降的学习速率
alpha = 0.01
#正则化λ参数
reg_lambda = 1
#参数w
weights = []
#损失
loss = []
其实,cmath用不用都无所谓,因为最开始,求解多项式的时候,cmath.log()可以求得
复数,而math.log()不行,后来直接使用numpy库中的求根函数直接获得答案了。
贴出以下代码用到的数据集,需要使用请保存成logistic_d1_s.txt文件即可:
-0.017612 14.053064 0
-1.395634 4.662541 1
-0.752157 6.538620 0
-1.322371 7.152853 0
0.423363 11.054677 0
0.406704 7.067335 1
0.667394 12.741452 0
-2.460150 6.866805 1
0.569411 9.548755 0
-0.026632 10.427743 0
0.850433 6.920334 1
1.347183 13.175500 0
1.176813 3.167020 1
-1.781871 9.097953 0
-0.566606 5.749003 1
0.931635 1.589505 1
-0.024205 6.151823 1
-0.036453 2.690988 1
-0.196949 0.444165 1
1.014459 5.754399 1
1.985298 3.230619 1
-1.693453 -0.557540 1
-0.576525 11.778922 0
-0.346811 -1.678730 1
-2.124484 2.672471 1
1.217916 9.597015 0
-0.733928 9.098687 0
-3.642001 -1.618087 1
0.315985 3.523953 1
1.416614 9.619232 0
-0.386323 3.989286 1
0.556921 8.294984 1
1.224863 11.587360 0
-1.347803 -2.406051 1
1.196604 4.951851 1
0.275221 9.543647 0
0.470575 9.332488 0
-1.889567 9.542662 0
-1.527893 12.150579 0
-1.185247 11.309318 0
-0.445678 3.297303 1
1.042222 6.105155 1
-0.618787 10.320986 0
1.152083 0.548467 1
0.828534 2.676045 1
-1.237728 10.549033 0
-0.683565 -2.166125 1
0.229456 5.921938 1
-0.959885 11.555336 0
0.492911 10.993324 0
0.184992 8.721488 0
-0.355715 10.325976 0
-0.397822 8.058397 0
0.824839 13.730343 0
1.507278 5.027866 1
0.099671 6.835839 1
-0.344008 10.717485 0
1.785928 7.718645 1
-0.918801 11.560217 0
-0.364009 4.747300 1
-0.841722 4.119083 1
0.490426 1.960539 1
-0.007194 9.075792 0
0.356107 12.447863 0
0.342578 12.281162 0
-0.810823 -1.466018 1
2.530777 6.476801 1
1.296683 11.607559 0
0.475487 12.040035 0
-0.783277 11.009725 0
0.074798 11.023650 0
-1.337472 0.468339 1
-0.102781 13.763651 0
-0.147324 2.874846 1
0.518389 9.887035 0
1.015399 7.571882 0
-1.658086 -0.027255 1
1.319944 2.171228 1
2.056216 5.019981 1
-0.851633 4.375691 1
-1.510047 6.061992 0
-1.076637 -3.181888 1
1.821096 10.283990 0
3.010150 8.401766 1
-1.099458 1.688274 1
-0.834872 -1.733869 1
-0.846637 3.849075 1
1.400102 12.628781 0
1.752842 5.468166 1
0.078557 0.059736 1
0.089392 -0.715300 1
1.825662 12.693808 0
0.197445 9.744638 0
0.126117 0.922311 1
-0.679797 1.220530 1
0.677983 2.556666 1
0.761349 10.693862 0
-2.168791 0.143632 1
1.388610 9.341997 0
0.317029 14.739025 0
第一步,获取数据:
def get_1st_data():
global D_Features,D_Result
train_x = []
train_y = []
fileIn = open('logistic_d1_s.txt')
# print(fileIn.readline().strip().split(' | | | |\r\n'))
for line in fileIn.readlines():
linearr = line.strip().split()
train_x.append([1.0, float(linearr[0]), float(linearr[1])])
train_y.append(float(linearr[2]))
D_Features = np.array(train_x)
D_Result = np.mat(train_y).T
第一点五步,建立数学公式:
#sigmoid函数,也叫作logistic函数
def sigmoid_func(x):
return ( 1.0/(1.0 + np.exp(-1.0 * x) ))
#设置各参数
def set_params():
global weights,loss
m,n = np.shape(D_Features)
print(n)
weights = np.zeros((n,1)) #初始矩阵(m x 1)
def grad_descent(cycle_num):
global weights,alpha,loss
mebSize = np.size(D_Result)
for i in range(cycle_num):
Es_val = sigmoid_func(np.dot(D_Features,weights)) #求出估计值 (100 x 3 -- 3 * 1) = ( 100 * 1 )
error = Es_val - D_Result # 求出真实值和预测值之间的误差
delta_W = (1.0 / mebSize) * np.dot( np.transpose(D_Features), error ) #求解最大似然函数 ( 3 x 100 -- 100 x 1 ) = ( 3 x 1 )
# weights = np.add(weights,-(alpha * error))
weights =weights - (alpha * delta_W) # 更新权重矩阵,梯度下降
loss_sum = cost_func(es_val=Es_val, real_val=D_Result)
if 0 == i :
print('第一次误差和:' + str( loss_sum))
loss.append(loss_sum)
print("最后一次误差和:" + str( loss[-1]))
print('迭代完成,权重参数为:\n'+ str( weights))
#求取代价函数
def cost_func(es_val,real_val):
mebSize = np.size(real_val)
return np.sum( (-1.0/mebSize) * ( np.dot(np.log(es_val).T,real_val ) + np.dot(np.log((1 - es_val)).T,(1 - real_val))))
第四步,训练结果评估
#训练结果评价
def train_result_evaluate():
p_es_val = sigmoid_func(np.dot(D_Features,weights))
mebSize = np.size(p_es_val) #获取矩阵中元素的个数
#对矩阵中的估计值,做0-1化处理,>=0.5 为1,<0.5为0
for i in range(mebSize):
if p_es_val[i,0] >= 0.5:
p_es_val[i,0] = 1
else:
p_es_val[i,0] = 0
#正确个数,正确率
correctNum = 0
accuracy = 0.0
for i in range(mebSize):
if p_es_val[i,0] == D_Result[i,0]:
correctNum = correctNum + 1
accuracy = correctNum / mebSize
print('总数为:'+ str(mebSize) +'个,预测正确个数为:'+ str( correctNum ) ,'预测正确率为:' + str (accuracy * 100) + r'%' )
第五步,画图看效果
def show_pic():
#第一张图
plt.figure(1)
#绘制数据集
for i in range(len(D_Features)):
if D_Result[i] :
plt.plot(D_Features[i,1], D_Features[i,2], color='red', marker='*')
else:
plt.plot(D_Features[i,1], D_Features[i,2],color='cornflowerblue',marker='D')
#找到坐标轴x1中的最大值和最小值,步长
max_radio_x = int( max(D_Features[:, 1]))
min_radio_x = int( min(D_Features[:, 1]))
num_radio_point = (abs(max_radio_x) + abs(min_radio_x)) / (len(D_Features[:])*2)
# print(num_radio_point)
line_x = np.mat( [np.arange(min_radio_x,max_radio_x,num_radio_point)]).tolist()
# print((weights[2]))
line_y = ((-weights[0] - weights[1]*line_x) / weights[2]).tolist() #(F:b,x,y x * )
# line_y = (-weights[0] - weights[1]*line_x).tolist()
# print(D_Features)
plt.plot(line_x[0], line_y[0],color='black')
#第二张图
plt.figure(2)
for i in range(len(loss)):
if str( loss[i]) == 'nan':
loss[i] = 0
plt.plot(loss)
# print(loss)
plt.show()
#多项式结果是复数形式,其中虚数不为0的部分,是无法正确映射到二维平面中的,因为二维平面中的坐标系全部是实数系,那么正确的做法是,将所有虚数为0的复数,取出来,绘制图形即可。
def show_d():
# 第一张图
plt.figure(1)
# 绘制数据集
for i in range(len(D_Features)):
if D_Result[i]:
plt.plot(D_Features[i, 1], D_Features[i, 2], color='red', marker='*')
else:
plt.plot(D_Features[i, 1], D_Features[i, 2], color='cornflowerblue', marker='D')
# 找到坐标轴x1中的最大值和最小值,步长
max_radio_x = max(D_Features[:, 1])
min_radio_x = min(D_Features[:, 1])
num_radio_point = (abs(max_radio_x) + abs(min_radio_x)) / (len(D_Features[:]))
# print(num_radio_point)
line_x = np.mat([np.arange(min_radio_x, max_radio_x, num_radio_point)]).T
# print(line_x)
line_y = []
for i in range(np.size(line_x)):
# print('asdasd')
# print(line_x[i,0])
a = np.array([weights[4,0],weights[2,0],(weights[0,0] + weights[1,0]* line_x[i,0] + weights[3,0]*line_x[i,0]*line_x[i,0])])
# print(a)
p = np.poly1d(a)
line_y.append(np.roots(p))
t = np.mat(line_y)
m1,m2 = np.shape(t)
line_yn1 = []
line_yn2 = []
line_yx1 = []
line_yx2 = []
for i in range(m1):
if 0.0 == line_y[i][0].imag:
line_yn1.append(line_y[i][0].real)
line_yx1.append(i)
if 0.0 == line_y[i][1].imag:
line_yn2.append(line_y[i][1].real)
line_yx2.append(i)
line_xx = []
for i in range(np.size(line_x)):
line_xx.append( line_x[i,0])
linexxx1 = []
lineyyy1 = []
linexxx2 = []
lineyyy2 = []
for i in range(len(line_yx1)):
# plt.plot(line_xx[line_yx1[i]],line_yn1[i],color='black',marker='.')
linexxx1.append(line_xx[line_yx1[i]])
lineyyy1.append(line_yn1[i])
for i in range(len(line_yx2)):
# plt.plot(line_xx[line_yx1[i]],line_yn2[i],color='black',marker='.')
linexxx2.append(line_xx[line_yx2[i]])
lineyyy2.append(line_yn2[i])
plt.plot(linexxx1, lineyyy1, color='black')
plt.plot(linexxx2, lineyyy2, color='black')
plt.show()
#只显示误差的图
def show_loss_pic():
#第二张图
plt.figure(2)
for i in range(len(loss)):
if str( loss[i]) == 'nan':
loss[i] = 0
plt.plot(loss)
# print(loss)
plt.show()
画图必要掌握的知识:
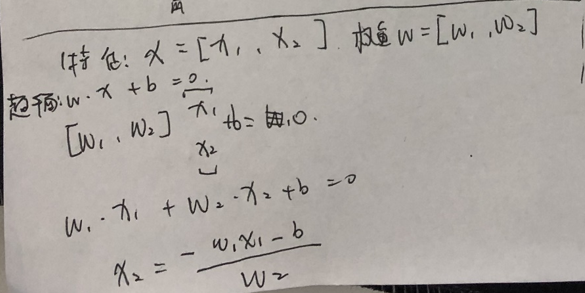
#使用数据1
def use_data_b(circle_num):
get_1st_data()
set_params()
grad_descent(circle_num)
train_result_evaluate()
show_pic()
#使用数据3,多项式
def use_data_d2(circle_num):
get_3rd_datas()
set_params()
show_datas()
grad_descent(circle_num)
train_result_evaluate()
show_d()
show_loss_pic()
if __name__ == "__main__":
#不使用科学计数法显示结果
np.set_printoptions(suppress=True)
use_data_b(8000)
运行看结果:
首先,看一下数据结果:

回归效果,直线是我们找出的参数方程:
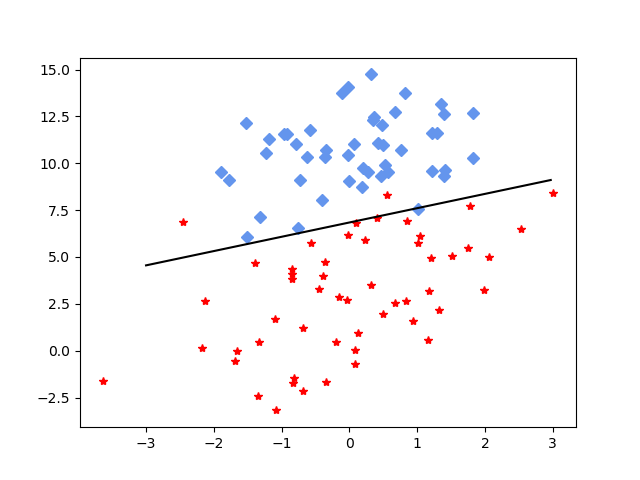
误差收敛效果:
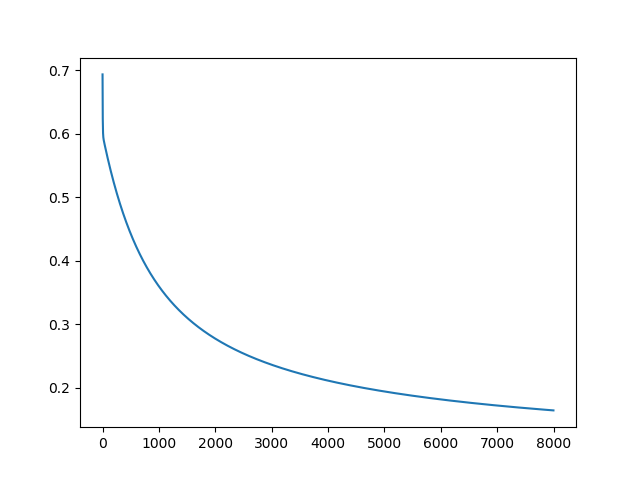
结论,我们此次选择迭代8000次,然后误差逐渐减小,基本上符合了我们的预期。
特征数据较大的处理
那么,这个时候,来解决我之前提到的,当特征数据本身较大时,迭代次数较多的验证,我们是用以下这些数据(也是我从网上搞的,使用时,请保存成logistic_d1_b.txt即可):
34.62365962451697,78.0246928153624,0
30.28671076822607,43.89499752400101,0
35.84740876993872,72.90219802708364,0
60.18259938620976,86.30855209546826,1
79.0327360507101,75.3443764369103,1
45.08327747668339,56.3163717815305,0
61.10666453684766,96.51142588489624,1
75.02474556738889,46.55401354116538,1
76.09878670226257,87.42056971926803,1
84.43281996120035,43.53339331072109,1
95.86155507093572,38.22527805795094,0
75.01365838958247,30.60326323428011,0
82.30705337399482,76.48196330235604,1
69.36458875970939,97.71869196188608,1
39.53833914367223,76.03681085115882,0
53.9710521485623,89.20735013750205,1
69.07014406283025,52.74046973016765,1
67.94685547711617,46.67857410673128,0
70.66150955499435,92.92713789364831,1
76.97878372747498,47.57596364975532,1
67.37202754570876,42.83843832029179,0
89.67677575072079,65.79936592745237,1
50.534788289883,48.85581152764205,0
34.21206097786789,44.20952859866288,0
77.9240914545704,68.9723599933059,1
62.27101367004632,69.95445795447587,1
80.1901807509566,44.82162893218353,1
93.114388797442,38.80067033713209,0
61.83020602312595,50.25610789244621,0
38.78580379679423,64.99568095539578,0
61.379289447425,72.80788731317097,1
85.40451939411645,57.05198397627122,1
52.10797973193984,63.12762376881715,0
52.04540476831827,69.43286012045222,1
40.23689373545111,71.16774802184875,0
54.63510555424817,52.21388588061123,0
33.91550010906887,98.86943574220611,0
64.17698887494485,80.90806058670817,1
74.78925295941542,41.57341522824434,0
34.1836400264419,75.2377203360134,0
83.90239366249155,56.30804621605327,1
51.54772026906181,46.85629026349976,0
94.44336776917852,65.56892160559052,1
82.36875375713919,40.61825515970618,0
51.04775177128865,45.82270145776001,0
62.22267576120188,52.06099194836679,0
77.19303492601364,70.45820000180959,1
97.77159928000232,86.7278223300282,1
62.07306379667647,96.76882412413983,1
91.56497449807442,88.69629254546599,1
79.94481794066932,74.16311935043758,1
99.2725269292572,60.99903099844988,1
90.54671411399852,43.39060180650027,1
34.52451385320009,60.39634245837173,0
50.2864961189907,49.80453881323059,0
49.58667721632031,59.80895099453265,0
97.64563396007767,68.86157272420604,1
32.57720016809309,95.59854761387875,0
74.24869136721598,69.82457122657193,1
71.79646205863379,78.45356224515052,1
75.3956114656803,85.75993667331619,1
35.28611281526193,47.02051394723416,0
56.25381749711624,39.26147251058019,0
30.05882244669796,49.59297386723685,0
44.66826172480893,66.45008614558913,0
66.56089447242954,41.09209807936973,0
40.45755098375164,97.53518548909936,1
49.07256321908844,51.88321182073966,0
80.27957401466998,92.11606081344084,1
66.74671856944039,60.99139402740988,1
32.72283304060323,43.30717306430063,0
64.0393204150601,78.03168802018232,1
72.34649422579923,96.22759296761404,1
60.45788573918959,73.09499809758037,1
58.84095621726802,75.85844831279042,1
99.82785779692128,72.36925193383885,1
47.26426910848174,88.47586499559782,1
50.45815980285988,75.80985952982456,1
60.45555629271532,42.50840943572217,0
82.22666157785568,42.71987853716458,0
88.9138964166533,69.80378889835472,1
94.83450672430196,45.69430680250754,1
67.31925746917527,66.58935317747915,1
57.23870631569862,59.51428198012956,1
80.36675600171273,90.96014789746954,1
68.46852178591112,85.59430710452014,1
42.0754545384731,78.84478600148043,0
75.47770200533905,90.42453899753964,1
78.63542434898018,96.64742716885644,1
52.34800398794107,60.76950525602592,0
94.09433112516793,77.15910509073893,1
90.44855097096364,87.50879176484702,1
55.48216114069585,35.57070347228866,0
74.49269241843041,84.84513684930135,1
89.84580670720979,45.35828361091658,1
83.48916274498238,48.38028579728175,1
42.2617008099817,87.10385094025457,1
99.31500880510394,68.77540947206617,1
55.34001756003703,64.9319380069486,1
74.77589300092767,89.52981289513276,1
定义下数据获取格式:
def get_2nd_datas():
global D_Features,D_Result
data = np.loadtxt('logistic_d1_b.txt', delimiter=',')
D_Features = data[:,(0,1)]
# D_Features = data[:,(0,1)]/10
dl,d2l = np.shape(D_Features)
D_addFeature = np.ones((dl,1))
D_Features = np.concatenate((D_addFeature,D_Features),axis=1) #组成新的特征向量,原因是必须第一列为1,表示方程的常量,比如两个特征x1,x2 需要三个参数,w1 + w2 * x1 + w3*x2
D_Result = np.mat(data[:,2]).T
我们运行8000次看效果:
结果如下:
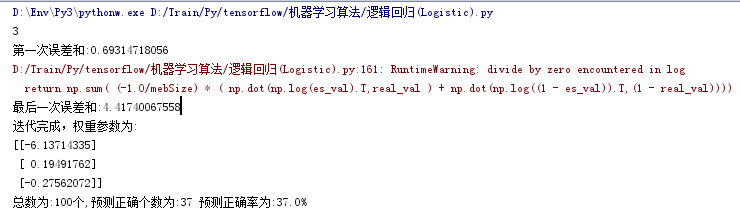
正确率只有37%。
其中。警告是因为,log0的存在,无法计算,数据中会变成 nan ,处理方式是将其视为一个不收敛值即可,我代码中在show_pic函数里,将其处理成了0。
结果绘图:
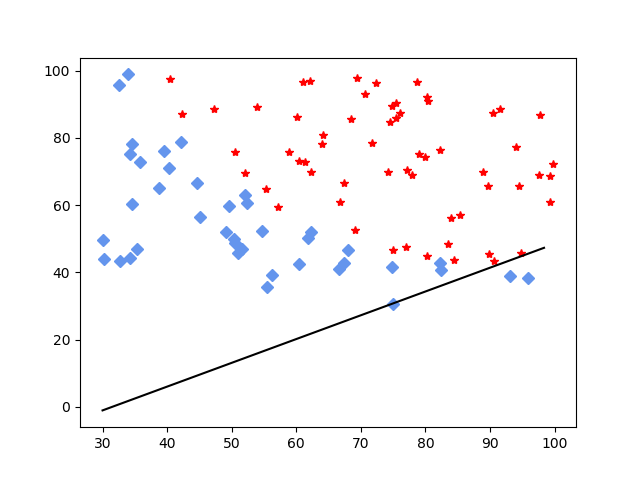
损失震荡十分严重:
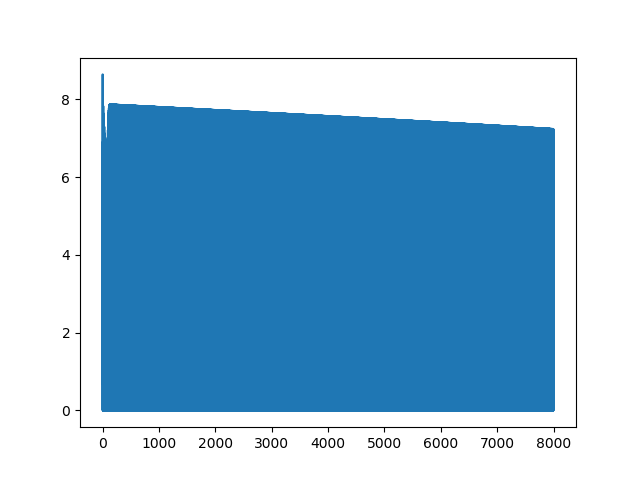
接下来,我迭代80000次:
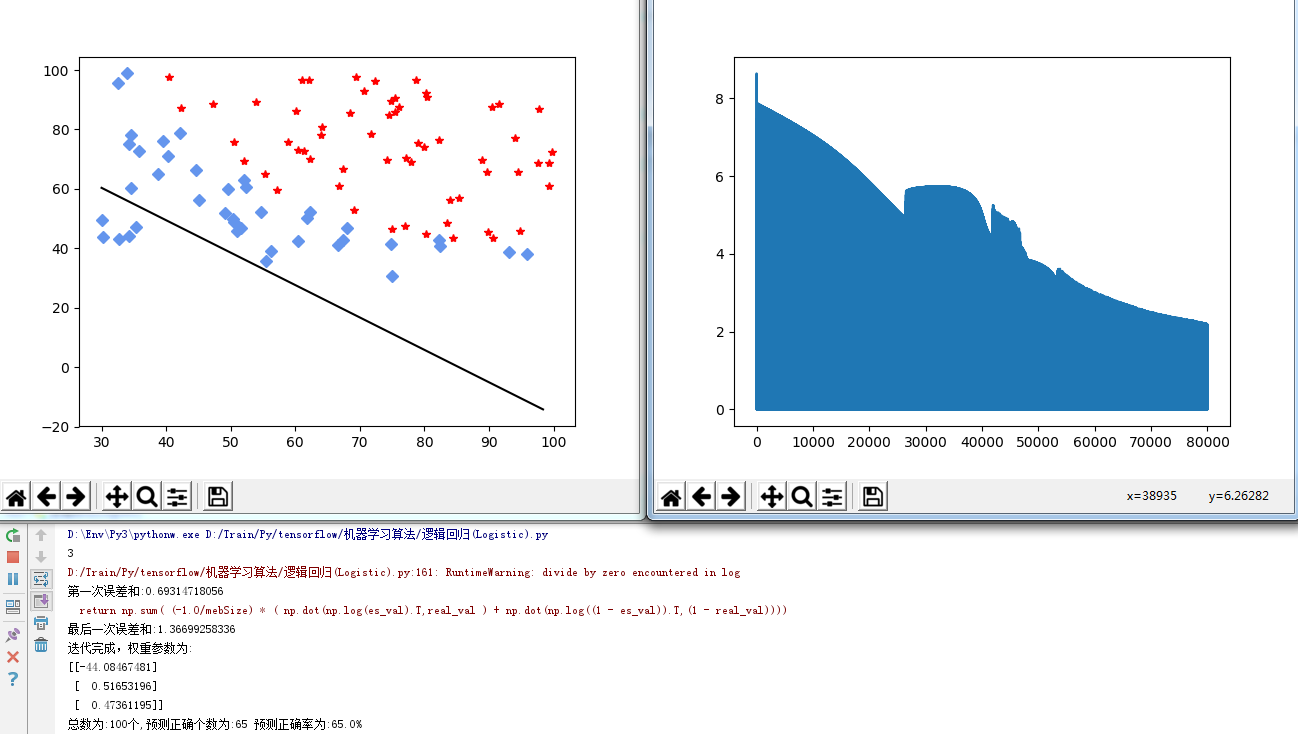
正确率上升到65%。
迭代200000次:
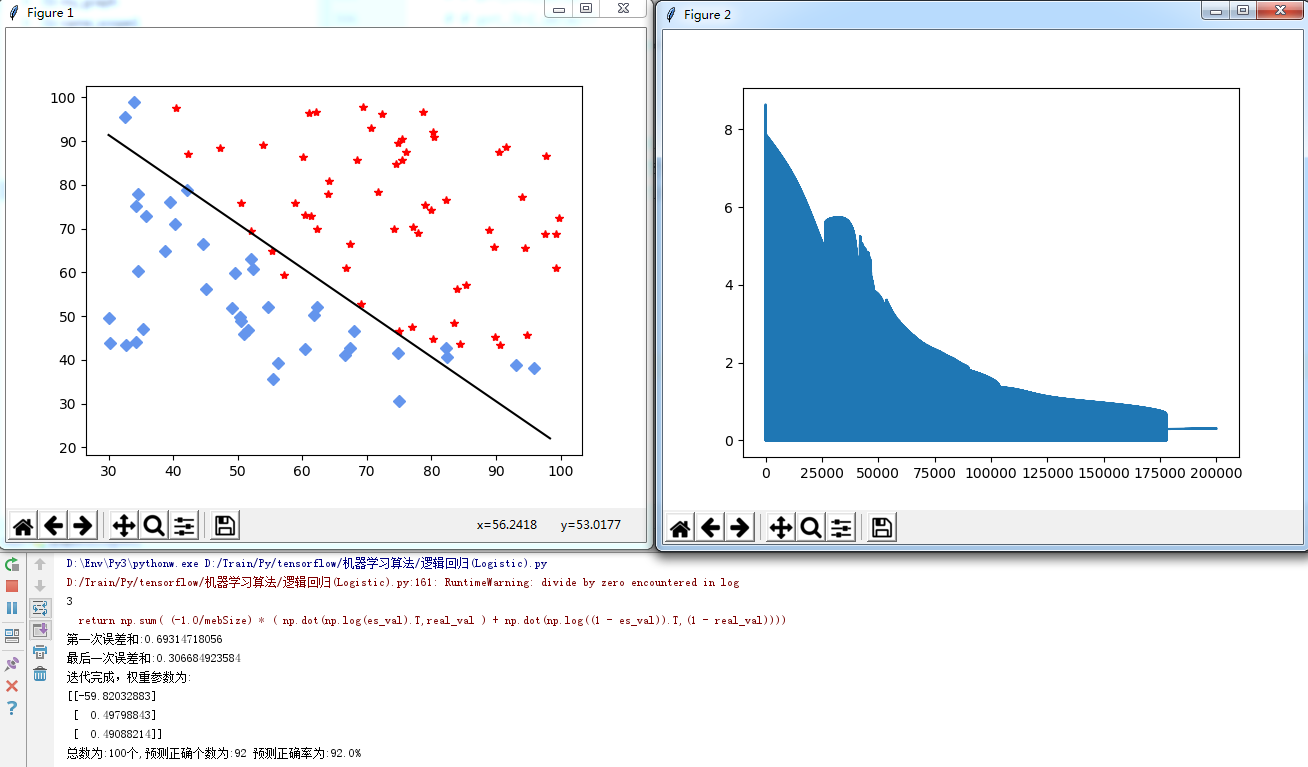
这个时候达到了92%,误差也开始收敛。
原因大家去看看公式,反推一下,就知道,为什么了,因为当初始权重参数给的极小时,而特征却十分大,但是由于S函数的缘故,基本求出的结果都是在两端话集中,所以才需要更多的次数迭代,使权重不断更新。
有没有减少迭代次数的解决方法?
有呀,比如说,处理特征值,将他们全部等值变小,看到我数据2处理代码中,那个被注释的了吗,这是一种,另外就是增大权重初始或者梯度下降的学习速率。我演示一下我的方法。
数据全部/10
def get_2nd_datas():
global D_Features,D_Result
data = np.loadtxt('logistic_d1_b.txt', delimiter=',')
# D_Features = data[:,(0,1)]
D_Features = data[:,(0,1)]/10
dl,d2l = np.shape(D_Features)
D_addFeature = np.ones((dl,1))
D_Features = np.concatenate((D_addFeature,D_Features),axis=1) #组成新的特征向量,原因是必须第一列为1,表示方程的常量,比如两个特征x1,x2 需要三个参数,w1 + w2 * x1 + w3*x2
D_Result = np.mat(data[:,2]).T
迭代8000次:
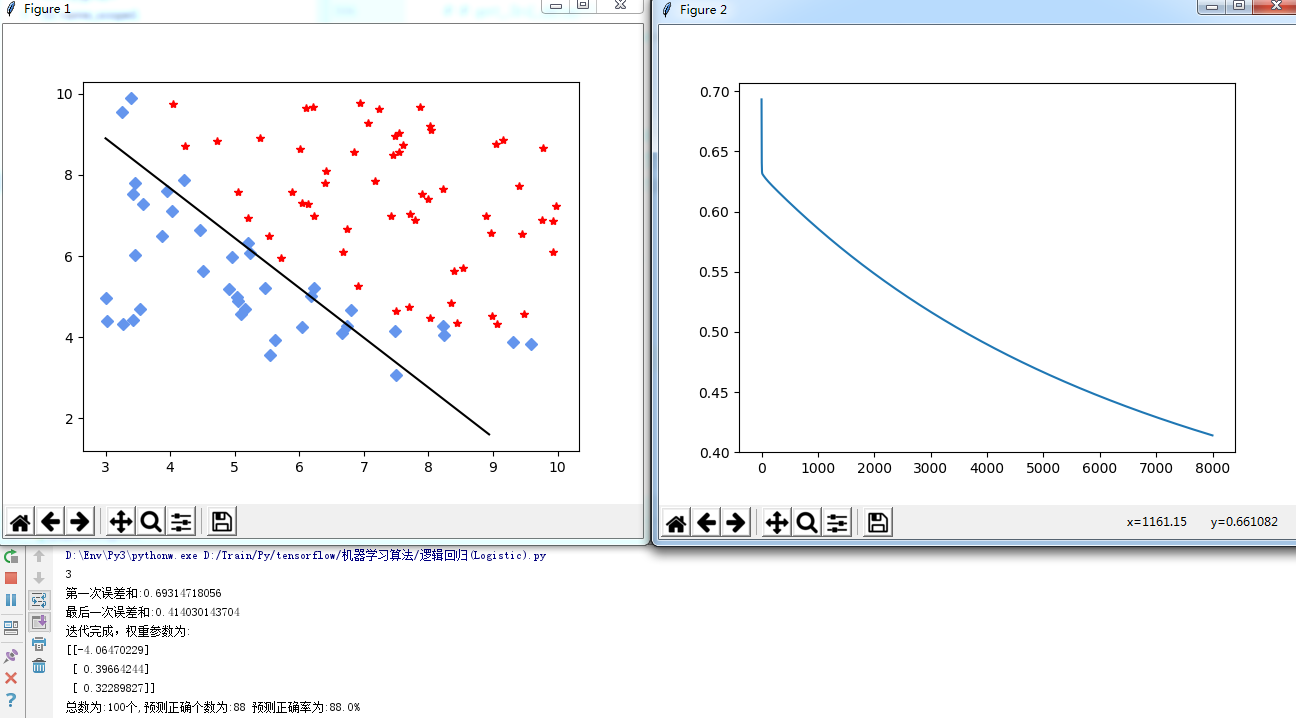
结束。
多项式
参数方程就可以是直线,也可以是曲线,接下来我们看一组数据(使用时,请保存成logistic_d2.txt即可):
0.051267,0.69956,1
-0.092742,0.68494,1
-0.21371,0.69225,1
-0.375,0.50219,1
-0.51325,0.46564,1
-0.52477,0.2098,1
-0.39804,0.034357,1
-0.30588,-0.19225,1
0.016705,-0.40424,1
0.13191,-0.51389,1
0.38537,-0.56506,1
0.52938,-0.5212,1
0.63882,-0.24342,1
0.73675,-0.18494,1
0.54666,0.48757,1
0.322,0.5826,1
0.16647,0.53874,1
-0.046659,0.81652,1
-0.17339,0.69956,1
-0.47869,0.63377,1
-0.60541,0.59722,1
-0.62846,0.33406,1
-0.59389,0.005117,1
-0.42108,-0.27266,1
-0.11578,-0.39693,1
0.20104,-0.60161,1
0.46601,-0.53582,1
0.67339,-0.53582,1
-0.13882,0.54605,1
-0.29435,0.77997,1
-0.26555,0.96272,1
-0.16187,0.8019,1
-0.17339,0.64839,1
-0.28283,0.47295,1
-0.36348,0.31213,1
-0.30012,0.027047,1
-0.23675,-0.21418,1
-0.06394,-0.18494,1
0.062788,-0.16301,1
0.22984,-0.41155,1
0.2932,-0.2288,1
0.48329,-0.18494,1
0.64459,-0.14108,1
0.46025,0.012427,1
0.6273,0.15863,1
0.57546,0.26827,1
0.72523,0.44371,1
0.22408,0.52412,1
0.44297,0.67032,1
0.322,0.69225,1
0.13767,0.57529,1
-0.0063364,0.39985,1
-0.092742,0.55336,1
-0.20795,0.35599,1
-0.20795,0.17325,1
-0.43836,0.21711,1
-0.21947,-0.016813,1
-0.13882,-0.27266,1
0.18376,0.93348,0
0.22408,0.77997,0
0.29896,0.61915,0
0.50634,0.75804,0
0.61578,0.7288,0
0.60426,0.59722,0
0.76555,0.50219,0
0.92684,0.3633,0
0.82316,0.27558,0
0.96141,0.085526,0
0.93836,0.012427,0
0.86348,-0.082602,0
0.89804,-0.20687,0
0.85196,-0.36769,0
0.82892,-0.5212,0
0.79435,-0.55775,0
0.59274,-0.7405,0
0.51786,-0.5943,0
0.46601,-0.41886,0
0.35081,-0.57968,0
0.28744,-0.76974,0
0.085829,-0.75512,0
0.14919,-0.57968,0
-0.13306,-0.4481,0
-0.40956,-0.41155,0
-0.39228,-0.25804,0
-0.74366,-0.25804,0
-0.69758,0.041667,0
-0.75518,0.2902,0
-0.69758,0.68494,0
-0.4038,0.70687,0
-0.38076,0.91886,0
-0.50749,0.90424,0
-0.54781,0.70687,0
0.10311,0.77997,0
0.057028,0.91886,0
-0.10426,0.99196,0
-0.081221,1.1089,0
0.28744,1.087,0
0.39689,0.82383,0
0.63882,0.88962,0
0.82316,0.66301,0
0.67339,0.64108,0
1.0709,0.10015,0
-0.046659,-0.57968,0
-0.23675,-0.63816,0
-0.15035,-0.36769,0
-0.49021,-0.3019,0
-0.46717,-0.13377,0
-0.28859,-0.060673,0
-0.61118,-0.067982,0
-0.66302,-0.21418,0
-0.59965,-0.41886,0
-0.72638,-0.082602,0
-0.83007,0.31213,0
-0.72062,0.53874,0
-0.59389,0.49488,0
-0.48445,0.99927,0
-0.0063364,0.99927,0
0.63265,-0.030612,0
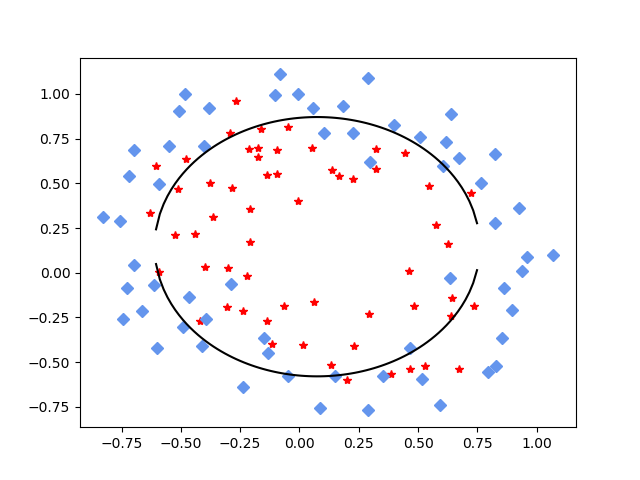
看一下图中效果:
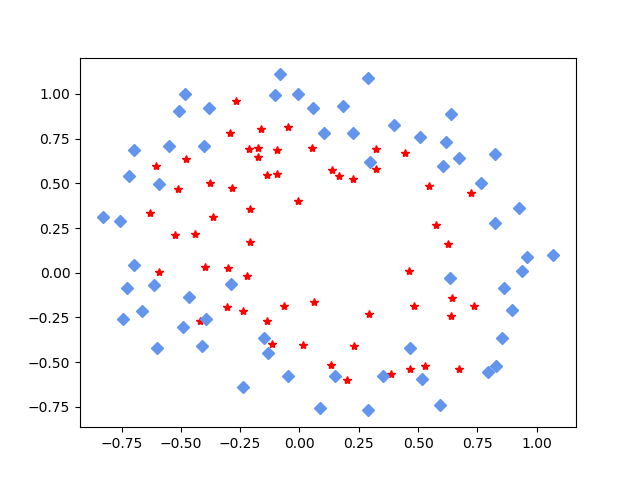
很明显可以看出来,这没法用一条直线求出最佳拟合效果,它更像是被一个不规则的圆所切割,所以我们要使用多项式,至于多项式的选择,这个依赖特征进行不同的选择。
获取数据:
#使用多项式,特征方程对应 w0 + w1 * x1 + w2 * x2 + w3 * x1^2 + w4 * x4^4
def get_3rd_datas():
global D_Features,D_Result
data = np.loadtxt('logistic_d2.txt', delimiter=',')
D_Features = data[:, (0, 1)]
# D_Features = data[:,(0,1)]/10
dl, d2l = np.shape(D_Features)
D_addFeature = np.ones((dl, 1))
D_Features = np.concatenate((D_addFeature, D_Features),
axis=1)
print(np.shape(D_Features))
df3 = data[:,0]**2
df3 = np.mat(df3).T
# print(df3)
df4 = data[:,1]**2
df4 = np.mat(df4).T
D_Features = np.concatenate((D_Features,df3),axis=1)
D_Features = np.concatenate((D_Features,df4),axis=1)
# print(D_addFeature)
# print(np.shape(D_Features))
print(np.shape(D_Features))
# print(D_Features.dtype)
D_Result = np.mat(data[:, 2]).T
迭代8000次,看一下结果:

看一看到,将特征增加圆的方程特征,正确率在8000次的时候,到达了77%
补充8000次的效果图:
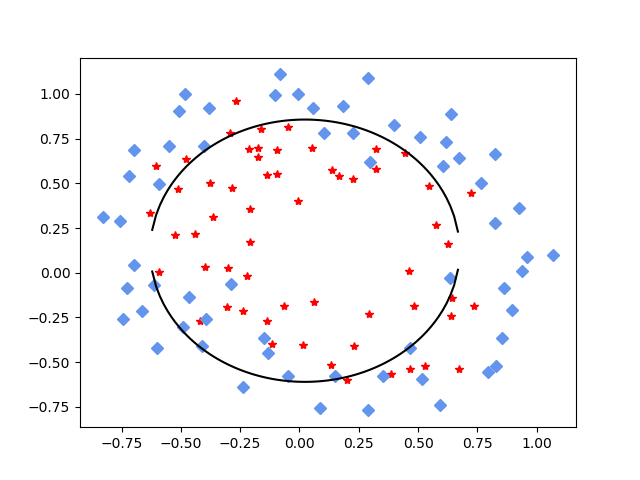
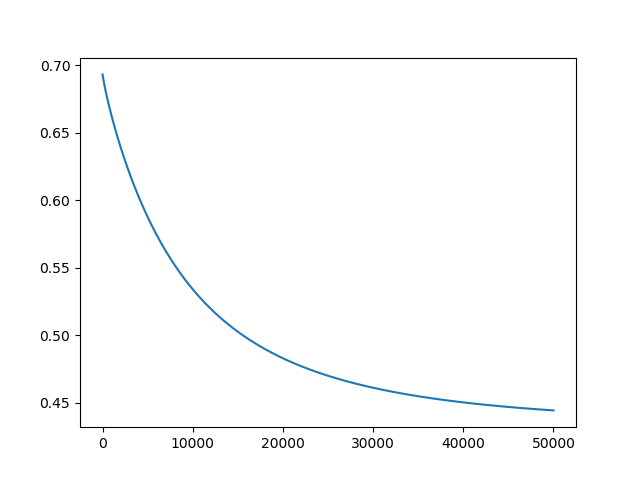
迭代50000次,正确率:

5w次,正确率80%
补充5w次效果图:
5w次损失曲线:
这里我存有一个疑问,就是效果图我画不出来,原因是因为,这里的参数方程为 w0 + w1 * x1 + w2 * x2 + w3 * x1^2 + w4 * x2^2 = 0 ,求解x2的时候,x2会出现复数的情况,我没法画出图来,十分郁闷,如果有懂这块的朋友,希望可以指教一下。(我看网上有人用等高线画的,也想不明白)
更新一下,画出来了,思路如下,忽然想通了,二维坐标系是实数系,而复数是实部加虚部,一旦虚部不为0,那么其在二维平面的映射后,注定不会正确表示,那么只要将虚部为0的复数全部提取出来,绘制即可。
正则化
正则化大家看一下这个课件吧:
点击打开链接
接下来我们看一下,正则化加入后的公式:
代价函数:
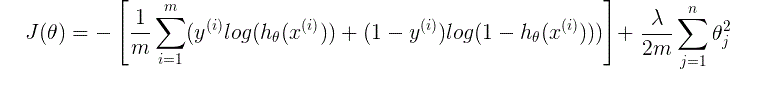
梯度下降:
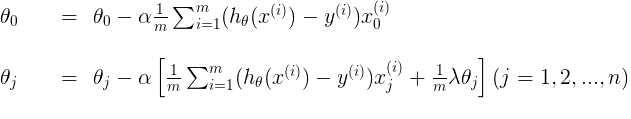
讲得不错了,我这里就放上我写的代码,实际看一下效果:
def grad_descent_reg(cycle_num):
global weights,alpha,loss
mebSize = np.size(D_Result)
for i in range(cycle_num):
Es_val = sigmoid_func(np.dot(D_Features,weights)) #求出估计值 (100 x 3 -- 3 * 1) = ( 100 * 1 )
# weights1 = weights.copy()
# weights1[0,0] = 0
error = Es_val - D_Result # 求出真实值和预测值之间的误差
delta_W = (1.0 / mebSize) * np.dot( np.transpose(D_Features), error ) #求解最大似然函数 ( 3 x 100 -- 100 x 1 ) = ( 3 x 1 )
if 0 == i :
weights = weights - (alpha * delta_W)
else:
weights =weights - (alpha * delta_W) - alpha * (reg_lambda/mebSize) * weights # 更新权重矩阵,梯度下降
loss_sum = cost_func_reg(es_val=Es_val, real_val=D_Result)
if 0 == i :
print('第一次误差和:' + str( loss_sum ))
loss.append(loss_sum)
print("最后一次误差和:" + str( loss[-1]))
print(r'迭代完成,权重参数为:\n'+ str( weights))
#求取代价函数,正则化
def cost_func_reg(es_val,real_val):
mebSize = np.size(real_val)
len_w = len(weights)
reg_sum = 0
for i in range(len_w - 1):
reg_sum = reg_sum + reg_lambda/(2*mebSize)*weights[(i+1),0]
return (np.sum( (-1.0/mebSize) * ( np.dot(np.log(es_val).T,real_val ) + np.dot(np.log((1 - es_val)).T,(1 - real_val)))) + reg_sum)
简单解释一下吧,说白了,我们这里使用的是梯度下降,一旦你迭代次数过了头,它就跳过了极值点,找到了非最优解,我这里演示一下,第一项数据迭代8w次效果,可以和上面做数据一的那张迭代8000次的作对比:

迭代8w次,正确率为95%,而迭代8000次则为97%
加入正则后,迭代8w次,结果如下:
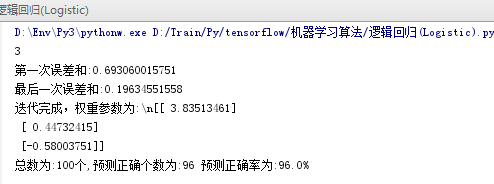
好一点点,96%。
其实这个例子举的并不好,因为直线拟合其实修正的意义不太大,但如果上升到多项式中,就会有很大意义了,因为有监督学习中,如果追求100%拟合数据,那么就会可能出现预测效果差的情况,因为我们都知道,预测通常是对过往已经发生的做经验式的总结从而做出的新的参考,而如果一定要将特例加入其中,那么我们将无法确定预测的准确率是否下降,因为我们无法确认这是否是个例现象而不是普例现象。
再补充单体预测代码:
#大于0.5为1,小于0.5为0,问题归一化后的体现
def predict(x):
p_es_val = sigmoid_func(np.dot(x,weights))
mebSize = np.size(p_es_val)
p_reg = []
for i in range(mebSize):
if p_es_val[i,0] >= 0.5:
p_reg.append([1,p_es_val[i,0]])
else:
p_reg.append([0,p_es_val[i,0]])
print('预测结果为:'+ str( p_reg) + '预测系数'+ str(p_es_val))
给出一组系数:
我们使用data1中的一组:
-1.337472 0.468339 1use_data_b(8000)
yd1 = [[1,-1.337472,0.468339]]
predict(yd1)

完成。