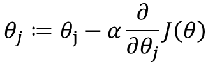文章目录
1 要点知识回顾
-
集合的划分
训练集(训练集,验证集(交叉验证)/开发集),测试集 -
机器学习的分类
- 有监督的机器学习:线性回归(提供了y值)
- 无监督的机器学习: KNN算法(没有提供y值)
-
线性回归
- 线性回归: y = ax +b
- 多元线性回归: y = w0x0 + w1x1 + … + wnwn
- 多项式回归: y = w0x0 + w1x1 + w2x0
**2 + w3x1**2
2 逻辑回归
2.1 什么是逻辑回归?
逻辑回归(Logistic Regression)是一种用于解决二分类(0 or 1)问题的机器学习方法,用于估计某种事物的可能性。比如某用户购买某商品的可能性,某病人患有某种疾病的可能性,以及某广告被用户点击的可能性等。
2.2 逻辑回归解决什么问题?
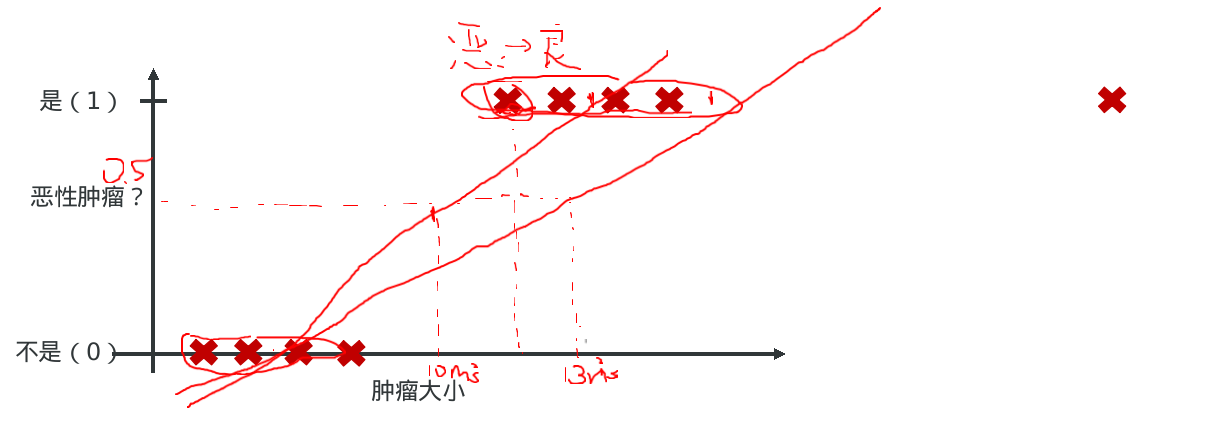
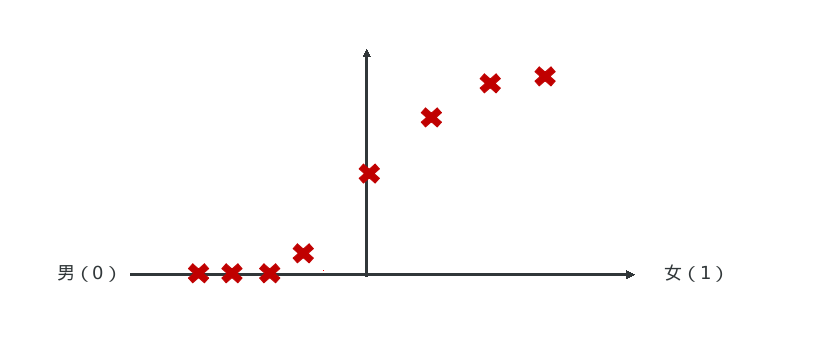
- 需求: 根据肿瘤大小预测是良性肿瘤还是恶性肿瘤?
有家医院希望我们能开发出一款分类器,可以通过数据分析出一块肿瘤到底是良性的,还是恶性的?- 0: 负例 “Negative Class” (良性肿瘤)
- 1: 正例 “Positive Class” (恶性肿瘤)

- 分析:
- 如果只有前8个点, 则通过第一条直线拟合数据模型, 也就是当肿瘤大小小于10平方毫米时,则认为是良性肿瘤;
- 如果有9个点, 则通过第二条直线拟合数据模型, 也就是当肿瘤大小小于13平方毫米时,则认为是良性肿瘤;但真实的数据显示11平方毫米已经是恶性肿瘤了, 因此传统的线性回归并不能成功的拟合数据模型.

- 总结
当我们要做二分类的时候,我们一般只希望得到两个值 y = 0 或 1。但是, 线性回归得到的值是在一个范围内的连续值,而且可能远 > 1 或远 < 0。这样会给分类带来困难。 我们希望的值域:

2.3 如何解决问题? —更新模型
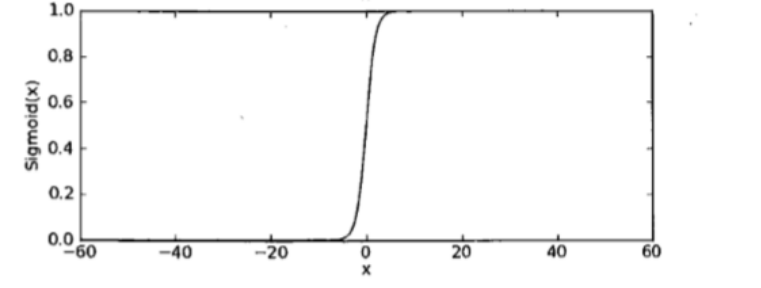
如果想要模型的y值坐落在[0,1]的区间上那么就需要使用sigmoid函数:
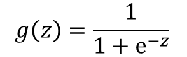
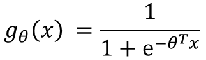
- g(x)的意义就是当输入x后,预测y=1的可能性有多高?
图形显示如下:
3 逻辑回归的引入-人脸识别

4 Sigmoid函数
4.1 什么是Sigmoid函数?
- 数学上,是根据广义线性回归的模型推导所得的结果
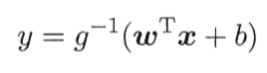
- 直观上
- 输出范围有限,数据在传递中不容易发散
- 抑制两头,对中间细微变化敏感,对分类有利
- 性质优秀,方便使用(Sigmoid函数是平滑的,而且任意阶可到,一阶二阶导数可以直接由函数得到不用求导,这在做梯度下降的时候很实用)

4.2 逻辑回归的决策边界
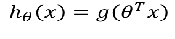
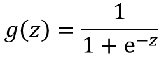


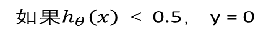
4.2.1 线性决策边界
-
已知:
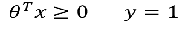
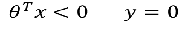
-
公式:
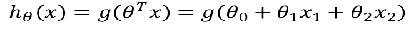
-
推测决策边界
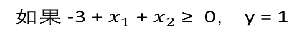
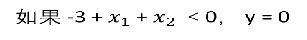
-
图形显示
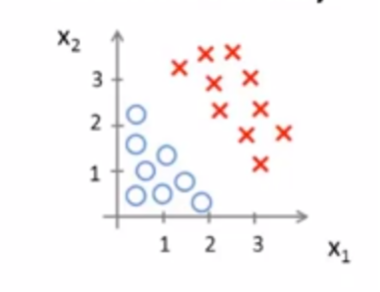
4.2.2 非线性的决策边界
-
已知:
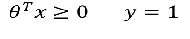

-
公式:
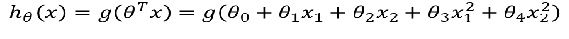
-
推测决策边界
根据公式可以发现是个圆, 圆里面是y=0,圆外面是y=1;
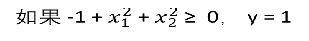
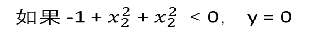
-
图形显示
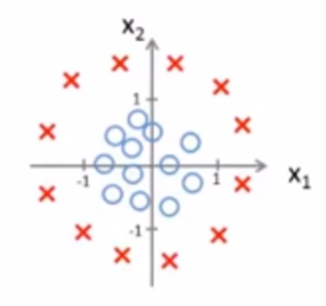
-
总结: 当然还有更复杂的决策边界,上面只描述了一次,二次。当三次,四次以及更高次图像就不好绘制,页九更不容易寻找决策边界.
5 逻辑回归的损失函数
5.1 逻辑回归汇总
-
训练集:

-
样本
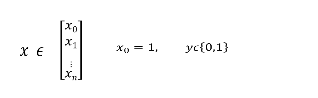
-
逻辑回归公式
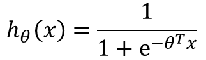
-
问题:
如何去选择theta? -
参考线性回归的做法是:损失函数

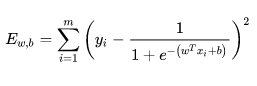
而逻辑回归不使用梯度下降中的最小二乘法求解损失函数的原因是: 目标函数是非凸的,不容易求解,只会得到局部最优。 如下图所示:
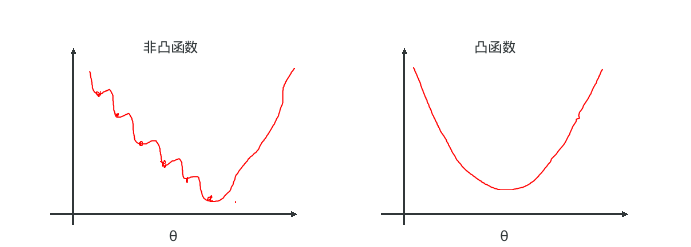
5.2 逻辑回归的梯度下降
既然最小二乘法并不能求解最优的theta, 那么逻辑回归如何实现梯度下降呢?
5.2.1 熵的引入
熵的意义:
-
1.热力学上的定义:
熵是一种测量分子不稳定性的指标,分子运动越不稳定,熵就越大 -
2.信息论(香农)
熵是一种测量信息量的单位,信息熵,包含的信息越多,熵就越大 -
3.机器学习
熵是一种测量不确定性的单位,不确定性越大,概率越小,熵就越大
5.2.2 熵的案例
信息量:
- 事件A:德国队进入了2018世界杯决赛圈
- 事件B:中国队进入了2018世界杯决赛圈
越不可能的事件发生了,我们获取到的信息量就越大.
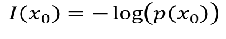
绘制图形如下, 发现信息量越大,熵就越大, 事件发生的概率就越小。
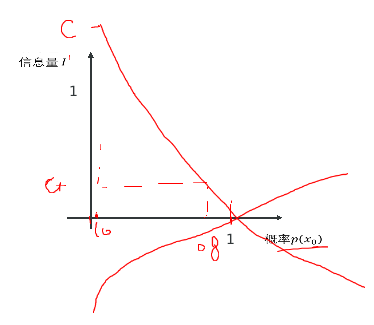
5.2.2 熵的计算
- 熵:表示所有信息量的期望
- 公式:
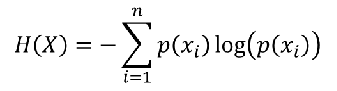
- 数据
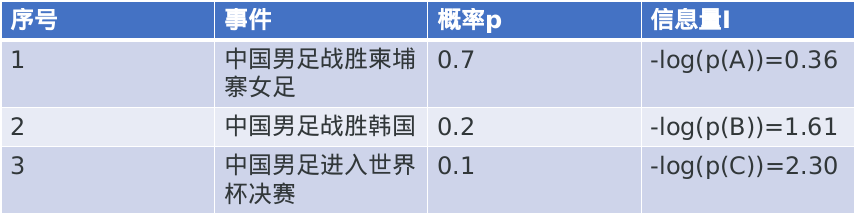
- 计算熵
H(x) = -[P(A)log(P(A)) + P(B)log(P(B)) + P(C)log(P(C))]
= -[0.7*(-0.36) + 0.2 * (-1.61) + 0.1 * (-2.30)]
= 0.804
5.3 交叉熵(Cross-Entropy)
交叉熵(Cross - Entropy):用来衡量两个样本分布差异的,也可以说是用来衡量两个样本的相似性。
- 在机器学习中,P往往用来表示样本的真实分布,Q用来表示模型所预测的分布、
- 公式:
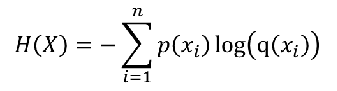
5.3.1 交叉熵的计算
问题: 图像预测,预测某个图像是否为兔子?

- 预测信息

- 计算
Entropy = -(0.6×log(0.6) + 0.4×log(0.4))
= 0.29
Cross Entropy 1 = -(0.6×log(0.5) + 0.4×log(0.5))
= 0.3
Cross Entropy 2 = -(0.6×log(0.2) + 0.4×log(0.8))
= 0.52
5.3.2 逻辑回归的损失函数 – 交叉熵
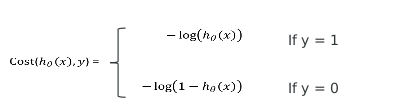
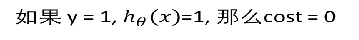
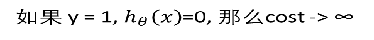
- 公式合并
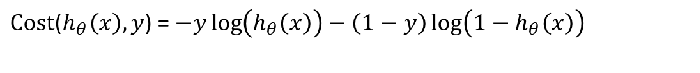
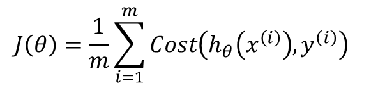
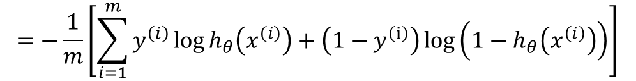
-
寻找合适的参数θ,使得最小化, 然后把θ带入公式
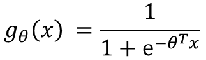
-
重复直到收敛, 并同步更新所有的theta1