逻辑回归
第一步先选择函数集
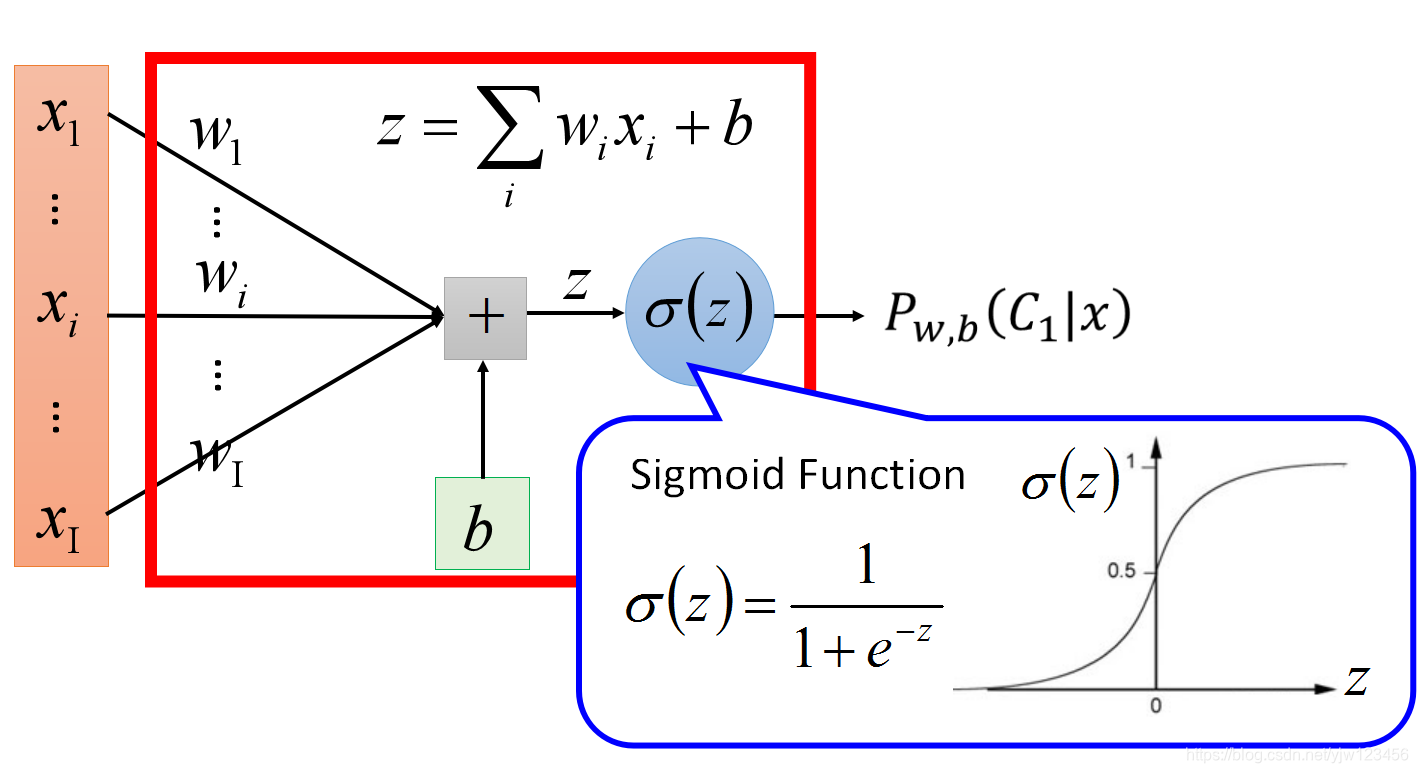
步骤一:函数集
接上一篇,我们知道,给定一个x,它属于类别
C1的概率为
Pw,b(C1∣x),
如果
Pw,b(C1∣x)≥0.5则属于
C1;否则属于
C2
最后我们得到
Pw,b(C1∣x)=σ(z),σ(z)=1+exp(−z)1
z=w⋅x+b=i∑wixi+b
所以我们的函数集是
fw,b(x)=Pw,b(C1∣x),包含所有不同的
w和
b。
图形化表示如下:
这个就是逻辑回归,我们与线性回归做一个比较。

因为Sigmoid函数的取值范围是0到1,因此逻辑回归的输出也是0到1;而线性回归的输出可以是任何值。
接下来判断函数的好坏
步骤2: 函数有多好
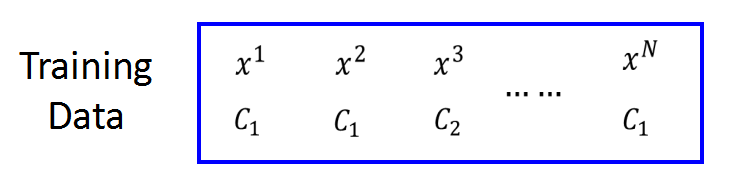
假设我们有N个训练数据,每个训练数据都标明了属于哪个类别(
C1或
C2)
并且假设这些数据是从
fw,b(x)=Pw,b(C1∣x)所产生的。
那么给定一组
w和
b,那如何计算某一组
w和
b产生这些数据的概率:
L(w,b)=fw,b(x1)fw,b(x2)(1−fw,b(x3))⋯fw,b(xN)
其中
x3是属于
C2,因此它的计算方法有点不同。
最好的
w和
b会产生产生最大的
L(w,b)
w∗,b∗=argw,bmaxL(w,b)
做个数学上的转换,将上式右边取对数,并加上负号,变成计算最小的:
w∗,b∗=argw,bmin−lnL(w,b)
取对数的好处是使得相乘变成相加:
−lnL(w,b)=−lnfw,b(x1)−lnfw,b(x2)−ln(1−fw,b(x3))⋯
但是这个式子不好写个SUM的形式,因此需要做符号转换

如果
y^n=1则说明它属于类别
C1;若等于0,说明属于类别
C2,那么就有
−lnfw,b(x1)⟹−[y^1lnf(x1)+(1−y^1)ln(1−f(x1))]−lnfw,b(x2)⟹−[y^2lnf(x2)+(1−y^2)ln(1−f(x2))]−ln(1−fw,b(x3))⟹−[y^3lnf(x3)+(1−y^3)ln(1−f(x3))]⋯
这样,就能得到一个函数:
因为
y^n取0或1,因此
y^nlnf(xn)+(1−y^n)ln(1−f(xn))中+号左右两边总有一个式子等于0。
L(w,b)−lnL(w,b)=fw,b(x1)fw,b(x2)(1−fw,b(x3))⋯fw,b(xN)=−(lnfw,b(x1)+lnfw,b(x2)+ln(1−lnfw,b(x3))⋯=n∑−[y^nlnfw,b(xn)+(1−y^n)ln(1−fw,b(xn))]
−[y^nlnfw,b(xn)+(1−y^n)ln(1−fw,b(xn))]其实就是两个伯努利分布的交叉熵,交叉熵主要用于衡量两个分布有多接近,如果一模一样的话,那么就是0。

所以在逻辑回归中,定义一个函数的好坏就通过两个类别分布的交叉熵之和:

我们需要最小化这个交叉熵,也就是希望函数的输出和目标函数的输出越接近越好。
步骤3:找到最好的函数
−lnL(w,b)=n∑−[y^nlnfw,b(xn)+(1−y^n)ln(1−fw,b(xn))]
找到最好的函数需要找到一组
w和
b使得上式的结果最小。
计算该式对w中某个特征的微分。
∂wi−lnL(w,b)=n∑−[y^n∂wi∂lnfw,b(xn)+(1−y^n)∂wi∂ln(1−fw,b(xn))]
其中
fw,b(x)=σ(z)=1+exp(−z)1 ,
z=w⋅x+b=∑iwixi+b
一项一项来求,左项可以写成
∂wi∂lnfw,b(x)=∂z∂lnfw,b(x)∂wi∂z
由
z的表达式知
∂wi∂z=xi
∂z∂lnfw,b(x)=∂z∂lnσ(z)=σ(z)1∂z∂σ(z)=σ(z)1σ(z)(1−σ(z))=(1−σ(z))
其中
∂z∂σ(z)=σ(z)(1−σ(z)) 证明如下:
σ′(z)=(1+e−z1)′=(1+e−z)20−(−e−z)=(1+e−z)21+e−z−1=(1+e−z)1(1−(1+e−z)1)=σ(z)(1−σ(z))
而右项
∂wi∂ln(1−fw,b(x))=∂σ(z)∂ln(1−fw,b(x))∂wi∂z∂wi∂z=xi
也就是
∂σ(z)∂ln(1−σ(z))=−1−σ(z)1σ(z)∂z=−1−σ(z)1σ(z)(1−σ(z))=−σ(z)
所以
∂wi−lnL(w,b)=n∑−[y^n∂wi∂lnfw,b(xn)+(1−y^n)∂wi∂ln(1−fw,b(xn))]=n∑−[y^n(1−fw,b(xn))xin−(1−y^n)fw,b(xn)xin]=n∑−[y^n−y^nfw,b(xn)
−fw,b(xn)+y^nfw,b(xn)
]xin=n∑−(y^n−fw,b(xn))xin
得到的式子很简单。如果用梯度下降算法来更新它的话,可以写成:
wi←wi−ηn∑−(y^n−fw,b(xn))xin
y^n−fw,b(xn)表示理想的目标与模型的输出的差距,如果差距越大,
那么更新的量应该要越大。
接下来比较下逻辑回归和线性回归更新时的式子:
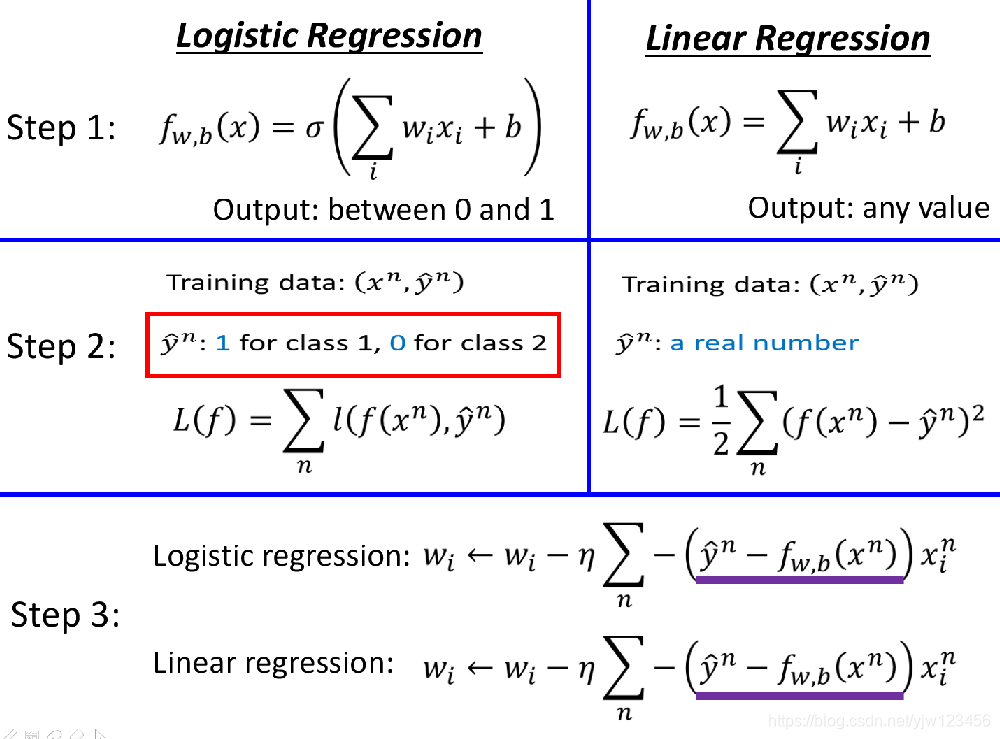
会发现表达式是一模一样的。唯一不同的是逻辑回归的
y^n取0或1,f是0~1之间的数值;而线性回归的
y^n是任意实数,输出也可以是任何实数。
生成模型VS判别模型
我们上面讨论的逻辑回归是判别模型(Discriminative),用高斯分布描述的概率分布模型是生成模型(Generative)。
它们的函数集是一样的
P(C1∣x)=σ(w⋅x+b)
用逻辑回归能直接找出
w和
b;如果是生成模型,那么需要找到
μ1,μ2,Σ−1,进而求出
wT和
b
根据同一组训练数据,同样的函数集,上面两种模型会得到不同的函数。
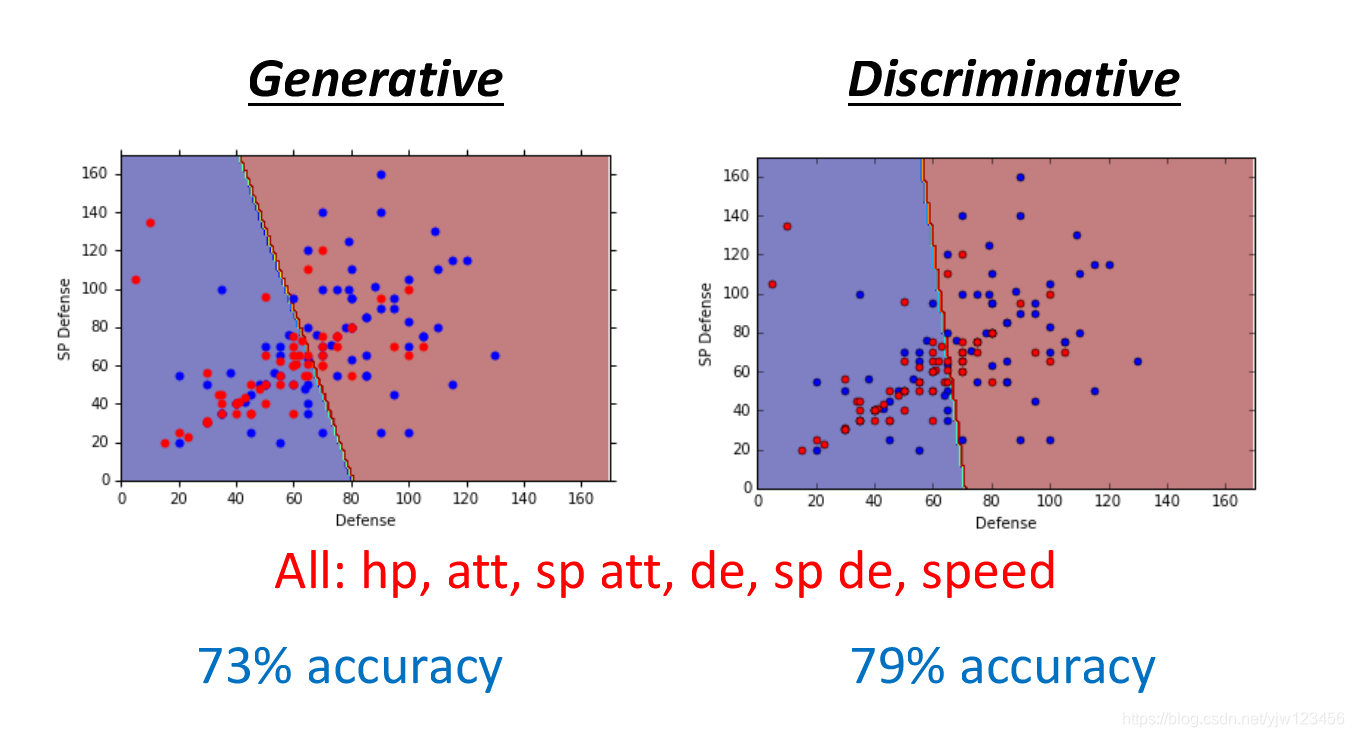
如果用上所有的特征,判别模型的准确率更好。
假设有一个非常简单的二元分类问题,每个数据都有两个特征。
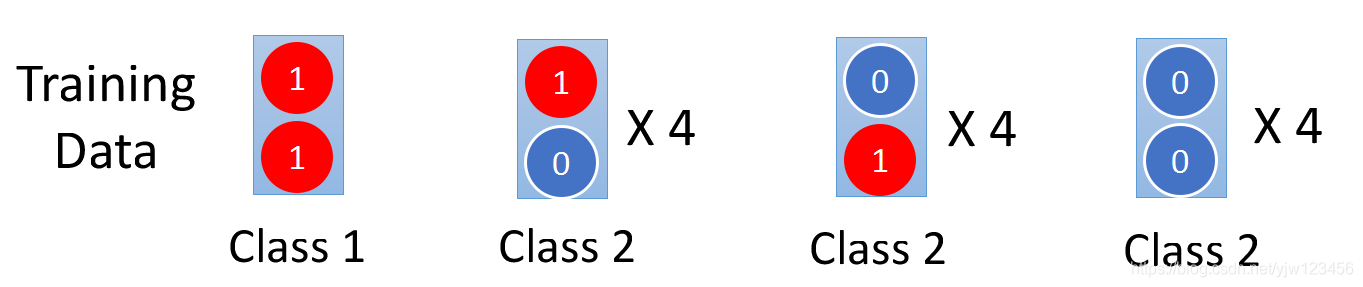
Class1我们只有一份数据,它的两个特征都是1;Class2有12份数据,如上。
如果给一份测试数据,它的两个特征都是1:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3Zwkz3lK-1575170875866)(_v_images/20191128222330408_20997.png)]](https://img-blog.csdnimg.cn/20191201113955799.png)
那么它属于哪个类别的概率大呢?
我们先来看下生成模型,选用朴素贝叶斯模型,朴素说的是每个特征都是独立的。
P(x∣Ci)=P(x1∣Ci)P(x2∣Ci)
P(C1)=131 给定类别
C1,第一个特征是1的几率
P(x1=1∣C1)=1,第二个特征是1的几率
P(x2=1∣C1)=1,也是1。
P(C2)=1312 ,给定类别
C2,第一个特征是1的几率
P(x1=1∣C1)=31,第二个特征是1的几率
P(x2=1∣C1)=31
接下来计算这个测试数据属于类别1的几率
P(C1∣x)=p(x∣C1)P(C1)+p(x∣C2)P(C2)p(x∣C1)P(C1)
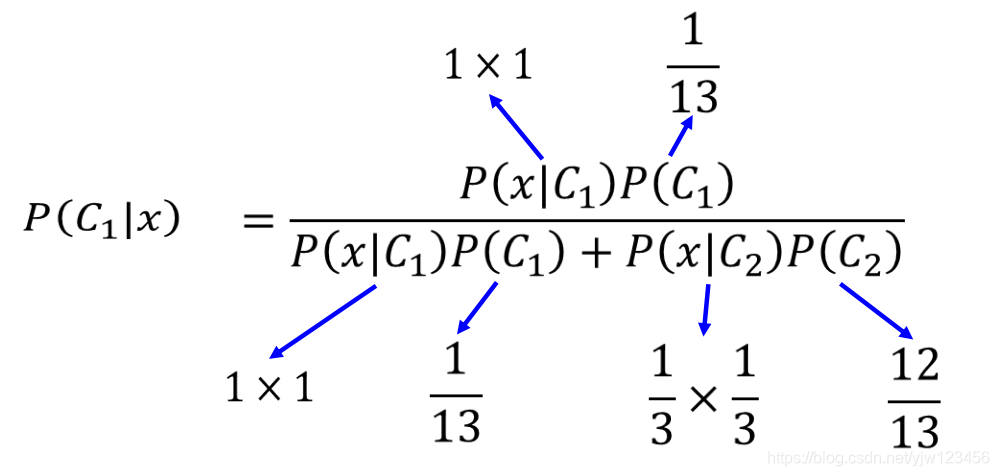
计算得
P(C1∣x)<0.5 ,因此判断它属于类别2;而用逻辑回归判断它属于类别1。
多分类问题
多分类问题是指类别超过2个的分类问题。
假设有3个类别,每个类别都有两组参数,我们怎么计算某个样本属于这三个类别的几率分别是多少。
我们计算
z1,z2,z3
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NdygqjrG-1576922710102)(_v_images/20191221151028052_18544.png)]](https://img-blog.csdnimg.cn/20191221180604208.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lqdzEyMzQ1Ng==,size_16,color_FFFFFF,t_70)
假设有个函数Softmax,它的输入就是
z1,z2,z3,输出
y1,y2,y3
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AVDZnhqb-1576922710103)(_v_images/20191221151319828_11014.png)]](https://img-blog.csdnimg.cn/20191221180615154.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lqdzEyMzQ1Ng==,size_16,color_FFFFFF,t_70)
假设输入是3,1,-3
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eDW3R771-1576922710103)(_v_images/20191221151455807_14751.png)]](https://img-blog.csdnimg.cn/20191221180624936.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lqdzEyMzQ1Ng==,size_16,color_FFFFFF,t_70)
首先取e的指数,得到20,2.7,0.05 再把这些数加起来得到22.75,输出就是根据e的指数除以这个加起来的总数。
可以把这些输出当成概率,它们的和刚好是1。
yi=P(Ci∣x)
我们把
z1,z2,z3经过Softmax函数后,得到
y1,y2,y3,我们要计算这些输出和对应的target(实际类别)的交叉熵。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NygYxVu4-1576922710103)(_v_images/20191221151957297_29237.png)]](https://img-blog.csdnimg.cn/20191221180632459.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lqdzEyMzQ1Ng==,size_16,color_FFFFFF,t_70)
y^的表示如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-siQ9zDEW-1576922710104)(_v_images/20191221172401045_27026.png)]](https://img-blog.csdnimg.cn/20191221180638809.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lqdzEyMzQ1Ng==,size_16,color_FFFFFF,t_70)
逻辑回归的限制
逻辑回归其实有很大的限制的,以一个简单的二分类问题来举例。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0If06Xme-1576922710104)(_v_images/20191221172818211_14903.png)]](https://img-blog.csdnimg.cn/20191221180645217.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lqdzEyMzQ1Ng==,size_16,color_FFFFFF,t_70)
它只有两个特征,如果都是0,则属于类别2;如果
x1=0,x2=1则属于类别1。
把这四个样本画到二维坐标上是下面这个样子,蓝色的点是类别2;红色的点是类别1。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H4FXoQMF-1576922710105)(_v_images/20191221172921132_3791.png)]](https://img-blog.csdnimg.cn/20191221180645400.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lqdzEyMzQ1Ng==,size_16,color_FFFFFF,t_70)
假设现在用逻辑回归模型来训练
z=w1x1+w2x2+b
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KLTVyVpS-1576922710105)(_v_images/20191221173059575_23261.png)]](https://img-blog.csdnimg.cn/20191221180658377.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lqdzEyMzQ1Ng==,size_16,color_FFFFFF,t_70)
输入
x1,x2,分别把它们乘以
w1,w2加上
b得到
z,代入Sigmoid函数得到输出
y。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7HuYNrL2-1576922710105)(_v_images/20191221173238516_226.png)]](https://img-blog.csdnimg.cn/2019122118070553.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lqdzEyMzQ1Ng==,size_16,color_FFFFFF,t_70)
对红色的点来说,
z要大于等于0,对蓝色的点来说
z要<0。我们做的到吗?做不到。
z是一条直线,因为逻辑回归能做到的事情是画一条这样的直线其中一边属于类别1,另一边属于类别2。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OKocJ8MJ-1576922710106)(_v_images/20191221173610140_31033.png)]](https://img-blog.csdnimg.cn/20191221180713240.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lqdzEyMzQ1Ng==,size_16,color_FFFFFF,t_70)
不管怎么画,都无法画出满足条件的直线。
那么怎么办呢,还是有办法的,可以做特征转换。把蓝色点和红点转换成一条直线的两边。
比如可以这样,重新定义特征,把原特征
x1和
[0,0]T的距离定义成新特征
x1′,把原特征
x2和
[1,1]T的距离定义成新特征
x2′
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vXF9znkW-1576922710106)(_v_images/20191221174257387_30253.png)]](https://img-blog.csdnimg.cn/20191221180716937.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lqdzEyMzQ1Ng==,size_16,color_FFFFFF,t_70)
比如原特征
[0,0]T和
[0,0]T的距离是0,和
[1,1]T的距离是
2
,就转换成上图左上角蓝色的点。
然后就可以画一条线将红蓝点分开。
但是特征转换并不总是那么的有用,因为这需要领域知识,要知道该怎么转换。
其实特征转换可以看很多个逻辑回归模型叠加的结果。
可以把
x1转换成
x1′以及
x2转换成
x2′看成是两个逻辑回归模型的结果。
也就是说,如下图蓝色的逻辑回归,输入是
x1,x2输出就是
x1′;而绿色的逻辑回归,输入是
x1,x2输出就是
x2′。它们两个做特征转换,而红色的作用就是分类。
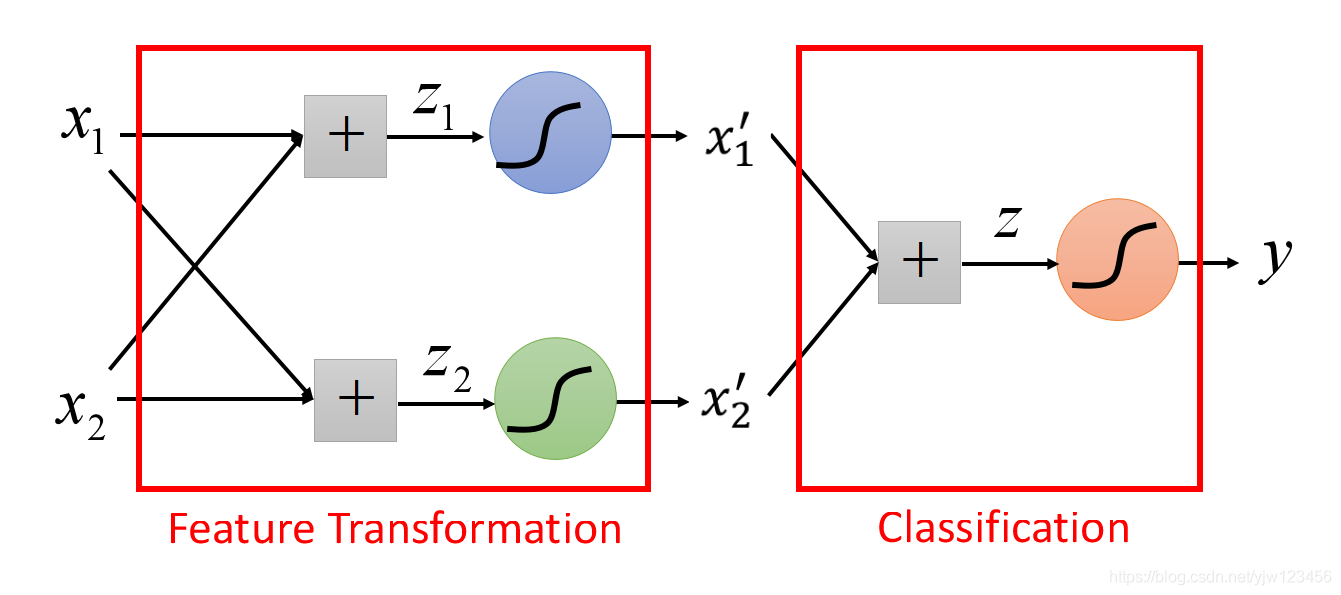
我们继续用刚才讲的例子来说明。
假设蓝色的逻辑回归的参数是-1(
b),-2(
w1),2(
w2),就可以计算出
x1′的值。
z=w1x1+w2x2+b
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xkyfUQbu-1576922710107)(_v_images/20191221175536726_8190.png)]](https://img-blog.csdnimg.cn/20191221180736765.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lqdzEyMzQ1Ng==,size_16,color_FFFFFF,t_70)
也就可以计算出四个点的
x1′,同理可以计算出四个点的
x2′。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GKizfYCs-1576922710107)(_v_images/20191221175704965_25266.png)]](https://img-blog.csdnimg.cn/201912211807445.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lqdzEyMzQ1Ng==,size_16,color_FFFFFF,t_70)
接下来就可以根据这些
x1′,x2′重新画出一个新的图形。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pxoVY3No-1576922710108)(_v_images/20191221175824828_4115.png)]](https://img-blog.csdnimg.cn/20191221180756251.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lqdzEyMzQ1Ng==,size_16,color_FFFFFF,t_70)
而红色的逻辑回归测试的就是
x1′,x2′,也就可以画出一条直线将它们分开。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EAqO35e4-1576922710108)(_v_images/20191221175949128_3366.png)]](https://img-blog.csdnimg.cn/20191221180802783.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lqdzEyMzQ1Ng==,size_16,color_FFFFFF,t_70)
我们可以把逻辑回归串接起来,一部分做特征转换,最后用一个做真正的分类。
那么问题来了,如何找到这些逻辑回归模型的参数呢?
这些逻辑回归的参数可以一起学习到的,只要告诉输入和输出,就可以一次把所有的逻辑回归的参数学习出来。
我们把上面每个逻辑回归模型叫做神经元,每个神经元串接起来后叫做神经网络,这就是深度学习
