一、多变量线性回归
1、一些符号
所谓多变量指的就是一个样本有多个特征,这多个特征组成了一个特征向量。例如,我们描述一件事物需要描述其多个特征才能确定该事物,例如房子面积、房间数、层数等特征,为方便运算,我们使用向量来表示。如下所示。
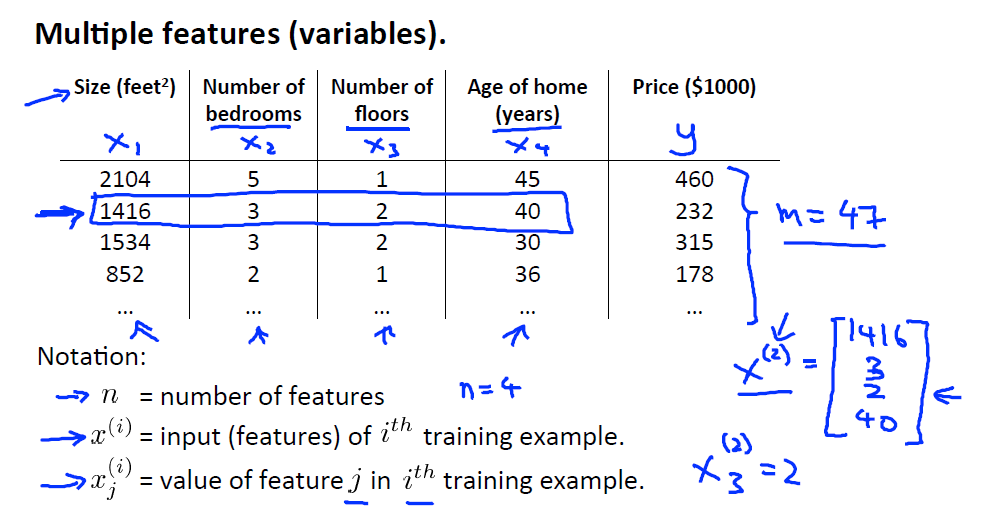
上图表格中每一行是一个特征向量。由于特征增多,需要增加一些符号。
n:特征数量。例如房子有面积、房间数、层数这三个特征。
x(i):表示第i个样本(特征向量)。
x(i)j:第i个样本的第j个特征。
2、假设函数
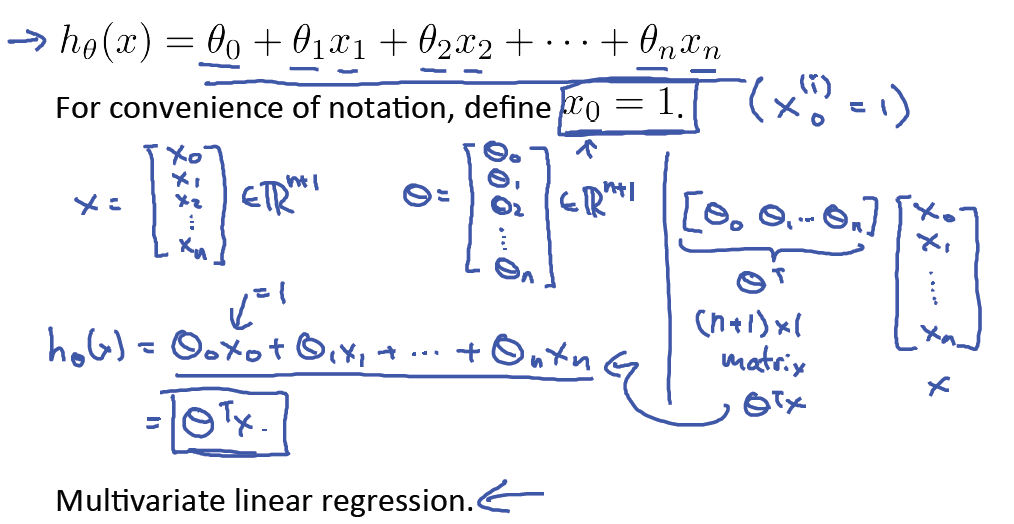
特征增加之后,我们的假设函数也变得复杂。我们依旧假设函数是线性的,hθ(x) = θ0 + θ1x1 + θ2x2 + ... + θnxn。为方便表示,我们需要将其表示为两个向量的相乘。设置x0 = 1,得到假设函数的向量表示,其中θ和x均为列向量。这样,假设函数便可表示为hθ(x) = θTx。由于增加了x0 = 1,所以对应的θ向量也为n+1维。
3、损失函数与梯度下降
与单变量线性回归一样,我们依旧使用欧氏距离表示预测值与实际值的差,得到损失函数J(θ)
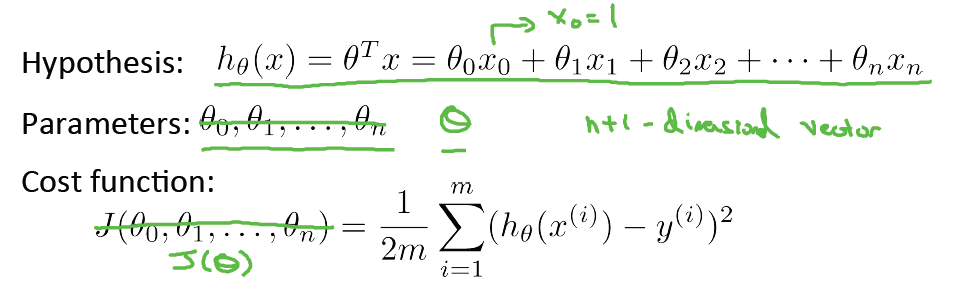
同理,我们运用梯度下降算法来得到极小值点。注意到下图中只剩下一条式子,这是因为加入了x0 = 1,故不用特别表示出来了。

二、一些技巧
1、特征缩放(Feature Scaling)
- 问题:一个样本中不同特征的数值相差很大。例如,x1的范围为0~2000,而x2的范围为1~5,这样造成的问题就是J(θ)的图像会很扁平,并且在使用梯度下降算法求解θ1时会使得θ1稍微变化就使得J(θ)变化很大,造成震荡现象。
- 解决:特征缩放。
- 具体做法:除我们添加的x0,其他特征除以该特征绝对值的最大值,这样就使得全部特征都在-1~1之内。
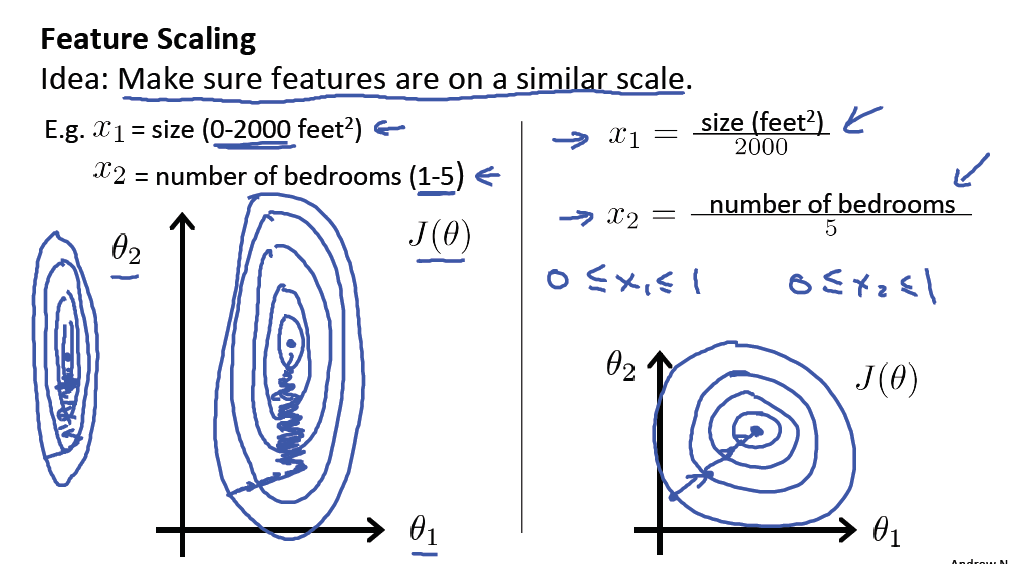
特征缩放不仅能解决震荡问题,还能加快梯度下降算法的收敛速度。值得注意的是,我们不需要严格使得所有特征均在-1~1范围内,只要不同特征的范围接近即可。例如,x1的范围是0~500,我们将其缩小到0~1,而x2的范围是-3~3,这是没问题的,不需要对x2特征缩放。记住,仅有一个原则,就是使得J(θ)在图像上尽可能地圆,不要太扁即可。

2、均值归一化(Mean Normalization)
另一种方法就是均值归一化。具体做法是:求解每个特征的平均值和标准差(或最大值与最小值的差),然后所有样本的的特征减去对应特征的平均值再除以对于特征的标准差。

三、诊断(Debugging)
1、诊断算法是否正常工作
可以画出损失函数J(θ)随着迭代次数的变化的曲线。由于我们的假设函数越来越拟合数据,所以每次迭代后J(θ)应该减小。我们可以自己观察,若J(θ)在某个迭代次数(例如迭代400次)之后变化不大,那么可以认为算法正常收敛了。也可以使用自动测试的办法,若J(θ)与前一次迭代的值相差小于等于10-3,那么也可以认为算法收敛了,但是这个阈值其实不好确定,故实际中还是自己观察为主。

2、学习率α
若J(θ)如下图①中那样变化,原因是α太大,导致θ越过最小值点,使得J(θ)一直增大;若如图②那样变化,原因也是α太大,导致J(θ)反复震荡。这两种情况的解决方法都是尝试减小α,找到合适的α。

总的来说,若α太大就可能出现上述情况,导致J(θ)收敛得很慢,甚至无法收敛;但如果α太小,则会导致算法收敛的很慢,需要更多次迭代才能收敛到最小值点。
关于α的选择,需要在选好的几个α中尝试并画出J(θ)的曲线,观察选出最优的α。例如选择0.01,0.03, 0.1,0.3等数值。

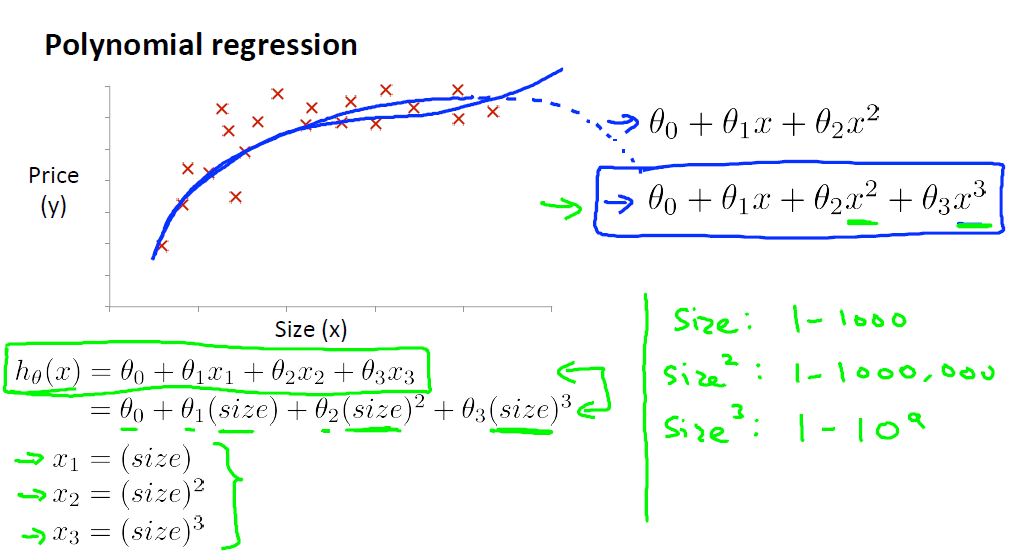
四、多项式回归(Polynomial Regression)
若样本呈现的规律不是直线,而是曲线的话,就需要使用多项式来拟合数据。若需要拟合的曲线是hθ(x) = θ0 + θ1x + θ2x2 + θ3x3,我们可以转化为多变量线性回归问题,令x1 = x, x2 = x2, x3 = x3,这样,假设函数就变成hθ(x) = θ0 + θ1x1 + θ2x2 + θ3x3,这就变成我们熟悉的多变量线性回归问题了。
五、正规方程(Normal Equation)
1、正规方程求解过程
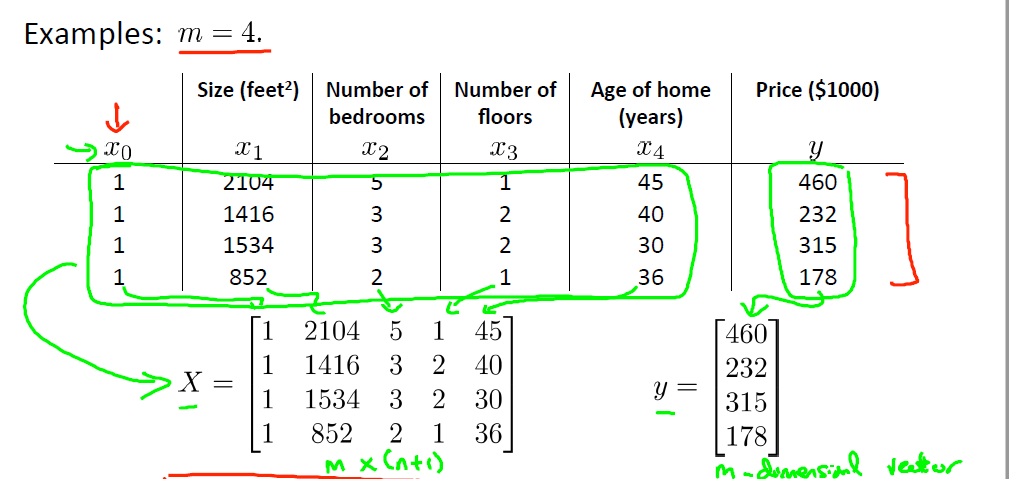
换个角度看问题,我们之前是使用损失函数J(θ),用欧氏距离来度量预测值与实际值的差距,并通过梯度下降算法来逐渐求得θ。所以我们的目的就是使得预测值与实际值尽可能接近。这样,对于某一样本,我们可以令θTx(i) = y(i),解出该方程即可求得使得hθ(x)最符合实际值y(i)的θ了,同时也使得损失函数J(θ)最小(因为拟合了y(i)了)。按照这种思路,我们对每一个样本建立方程,得到方程组。故问题变为求解这个方程组得出θ。有如下符号,X表示所有样本,y表示实际值,X表示为矩阵,y表示为向量。
这样得到方程组 Xθ = y,两边左乘XT(乘以转置矩阵主要是为了得到方阵XTX),便于求逆矩阵),再左乘以(XTX)-1,便可得到
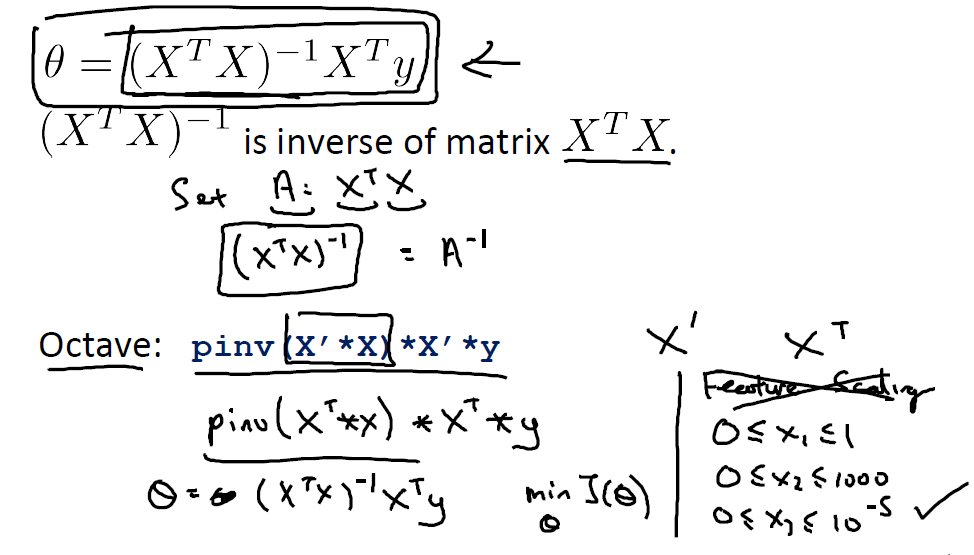
在octave(用matlab也行)使用pinv函数求逆矩阵,使用X'求转置矩阵。在octave中只需上图中蓝色字体那一行代码便可求得θ。
2、梯度下降与正规方程对比
正规方程求解十分便利,看起来似乎不需要梯度下降算法求解θ了。其实他们各有优缺点,下表列出梯度下降与正规方程的对比。
| 梯度下降 | 正规方程 |
| 需要选择学习率α | 不需要选择α |
| 需要多次迭代求解θ | 不需要迭代,直接求出θ |
| 即使特征数量n很大也能很快求解 | 需要计算(XTX)-1,算法复杂度为O(n3),当n很大时算法会比较慢 |
所以若每一个样本的特征数很大(例如大于10000),则应该使用梯度下降算法来求解θ。

3、XTX不可逆怎么办
XTX不可逆时称为奇异矩阵(Singular)或退化矩阵(Degenerate)。
解决方法很简单,在Octave中使用pinv命令时一定能求出逆矩阵(inv命令当矩阵不可逆时无法求出)。
XTX不可逆的原因主要时以下几个原因:
- 存在线性相关的特征。例如x1用平方英尺表示房屋面积,而x2用平方米表示面积,那么x1与x2是线性相关的。解决方法是删除某一个线性相关的某一特征。
- 特征太多,导致样本数m少于特征数n。从线性代数的角度看,此时方程组未知变量比方程多,此时Xθ = y可能无解,也可能有无数解,但是绝不可能只有唯一解。解决方法手动删除某些特征使得m>n,或者使用正则化(XTX正则化之后必定可逆)。
