C++实现梯度下降法
“linear_regression.h”
//多变量线性回归模型
struct elem_var2
{
double y;
double* x; //用数组传入自变量数据(x[0]=1,便于之后的计算)
};
class var2_lin_reg
{
public:
var2_lin_reg(int xnum, elem_var2* p, int size, double rate); //初始化
~var2_lin_reg(); //析构
void scaling(); //特征缩放器(将所有特征值统一缩放至1--10)
void scalback(); //特征还原(参数缩放)
double cost_fuction(); //返回当前预测方程对应代价函数的值
void update(); //同时更新方程参数
void find(); //最小化代价函数,找到收敛点时对应的方程参数
double* get_par(int &par_num); //获得当前方程的参数
double est_val(double* x); //使用拟合后的回归方程进行预测
private:
int x_num; //自变量个数
elem_var2* tran_set; //训练集(读入时将x【0】赋值为1)
int setsize; //训练集数据量
double* par; //参数数组(大小为实际x_num+1):h(x)=par0*x0(赋值为1)+par1*x1+par2+x^2+...+par(x_num)*x^x_num
double learn_rate; //学习速率
double* x_scal; //特征缩放率
};
“linear_regression.cpp”
//多变量线性回归
var2_lin_reg::var2_lin_reg(int xnum, elem_var2* p, int size, double rate)
{//参数列表:自变量数目,训练集地址,训练集容量,学习速率
x_num = xnum+1; //设置自变量数目
setsize = size; //获取训练集大小
tran_set = p; //指针指向训练集数组
learn_rate = rate; //设置学习速率
par = new double[xnum + 1]; //系数初始化为0
memset(par, 0, sizeof(double)*(xnum + 1));
x_scal = new double[xnum + 1]; //特征缩放率初始化为1
for (int i = 0;i < x_num;i++)
x_scal[i] = 1;
}
var2_lin_reg::~var2_lin_reg()
{
tran_set = NULL;
setsize = 0;
delete[]par;
par = NULL;
delete[]x_scal;
x_scal = NULL;
}
void var2_lin_reg::scaling()
{//特征缩放器
for (int j = 0;j < x_num;j++)
{//以第一组数据确定缩放率
while (tran_set[0].x[j] > 10 || tran_set[0].x[j] < 1)
{
if (tran_set[0].x[j] > 10)
{
tran_set[0].x[j] /= 10.0;
x_scal[j] *= 10.0;
}
else
{
tran_set[0].x[j] *= 10.0;
x_scal[j] /= 10.0;
}
}
}
for (int i = 1;i < setsize;i++)
{//对剩余数据进行缩放
for (int j = 0;j < x_num;j++)
{
tran_set[i].x[j] /= x_scal[j];
}
}
}
void var2_lin_reg::scalback()
{//特征还原,参数缩放
for (int i = 0;i < x_num;i++)
par[i] /= x_scal[i];
}
double var2_lin_reg::cost_fuction()
{ //返回当前预测方程对应代价函数的值
double hx, sum = 0;
for (int i = 0;i < setsize;i++)
{
hx = 0;
for (int j = 0;j < x_num;j++)
{
hx += par[j] * tran_set[i].x[j];
}
sum += (hx - tran_set[i].y)*(hx - tran_set[i].y);
}
return (sum / 2.0 / setsize);
}
void var2_lin_reg::update()
{//同时更新方程参数
double hx;
double* sum = new double[x_num];
for (int j = 0;j < x_num;j++)
{
sum[j] = 0;
for (int i = 0;i < setsize;i++)
{
hx = 0;
for (int t = 0;t < x_num;t++)
{
hx += par[t] * tran_set[i].x[t];
}
sum[j] += (hx - tran_set[i].y)*tran_set[i].x[j];
}
}
for (int i = 0;i < x_num;i++)
par[i] -= learn_rate * sum[i] / (double)setsize;
delete[]sum;
}
void var2_lin_reg::find()
{//最小化代价函数,找到收敛点时对应的方程参数
scaling(); //数据放缩
double cost_pre, cost_last;
cost_pre = cost_fuction();
update(); //更新参数
cost_last = cost_fuction();
while (cost_pre != cost_last)
{//寻找收敛点
/*
cout << cost_pre << " " << cost_last << endl; //用来选择学习率
*/
cost_pre = cost_last;
update();
cost_last = cost_fuction();
}
//获得假设函数最优拟合时的参数
scalback();
//特征还原,参数缩放
}
double* var2_lin_reg::get_par(int &par_num)
{//获得当前方程的参数
par_num = x_num;
return par;
}
double var2_lin_reg::est_val(double* x)
{//使用拟合后的回归方程进行预测
double hx = 0;
for (int i = 0;i < x_num;i++)
{
hx += par[i] * x[i];
}
return hx;
}
主函数部分:
int main()
{//多变量线性回归测试
int size, xnum;
cout << "请输入训练集容量:";
cin >> size;
cout << "请输入变量个数: ";
cin >> xnum;
elem_var2 transet[200];
for (int i = 0;i < size;i++)
{
transet[i].y = 0;
transet[i].x = new double[xnum + 1];
memset(transet[i].x, 0, sizeof(double)*(xnum + 1));
}
cout << "请输入训练集数据:" << endl;
for (int i = 0;i < size;i++)
{
transet[i].x[0] = 1;
for (int j = 1;j <= xnum;j++)
cin >> transet[i].x[j];
cin >> transet[i].y;
}
var2_lin_reg obj(xnum, transet, size, 0.042);
obj.find();
double*par = NULL;
int parnum;
par=obj.get_par(parnum);
cout << "h(x)=" << par[0];
for (int i = 1;i < parnum;i++)
{
if (par[i] > 0)
cout << '+' << par[i] << "*x" << i;
else
{
if (par[i] < 0)
cout << par[i] << "*x" << i;
}
}
cout << endl;
/*
double*x = new double[xnum + 1];
memset(x, 0, sizeof(double)*(xnum + 1));
double flag;
while (cin >> flag)
{//预测部分
if (flag == 0)
break;
x[0] = 1;
for (int i = 1;i <= xnum;i++)
cin >> x[i];
flag = obj.est_val(x);
cout << flag << endl;
}
delete[]x;
*/
for (int i = 0;i < size;i++)
{
delete[]transet[i].x;
}
return 0;
}
关于一些操作细节:
以吴恩达老师的训练集为例。
1.学习率选择:
find函数中有一行用于选择学习率的代码:
cout << cost_pre << " " << cost_last << endl;
下面来实际操作一下:
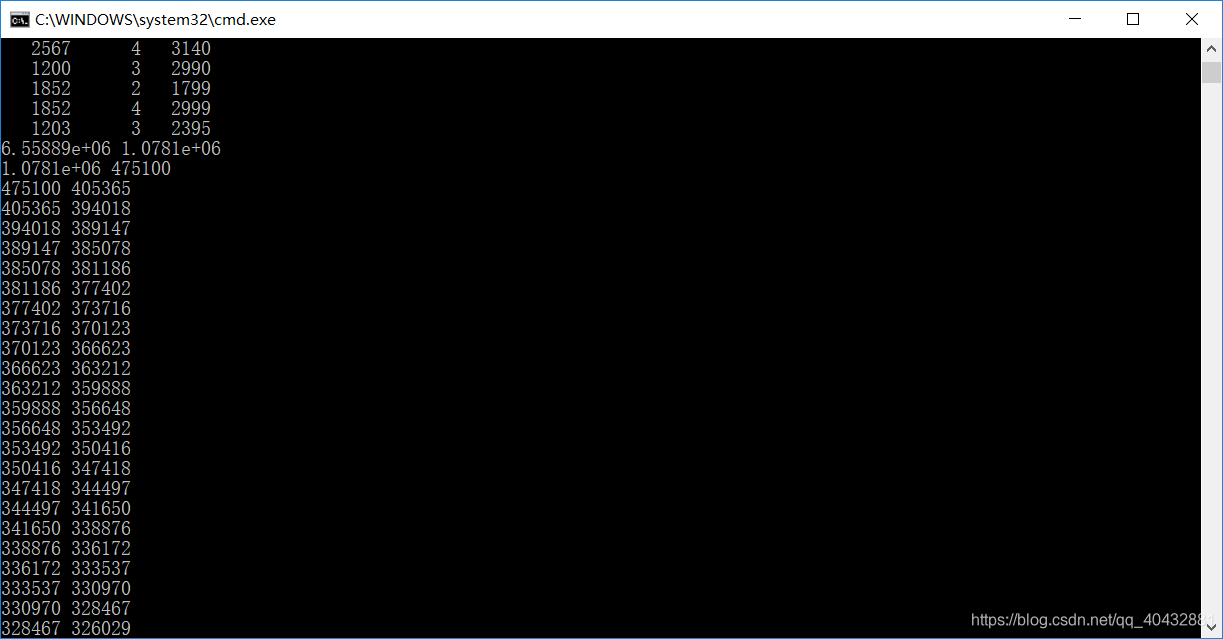
主函数学习率设为:0.042是通过测试得出的。
如果将学习率设置较大,输出的代价函数值结果如下:
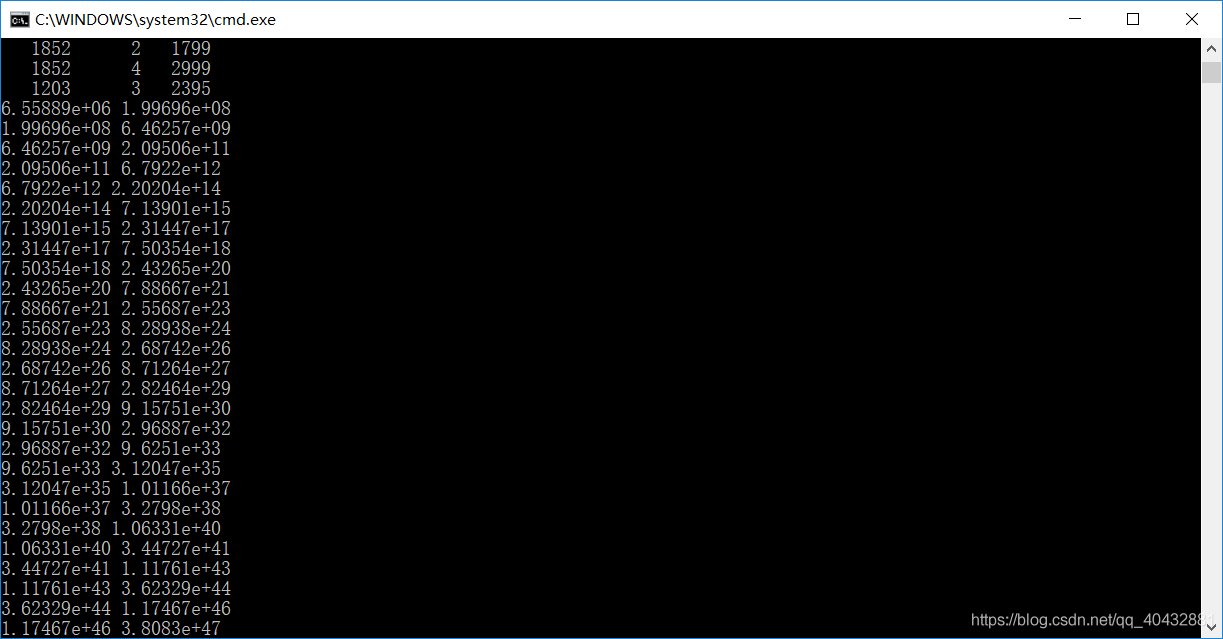
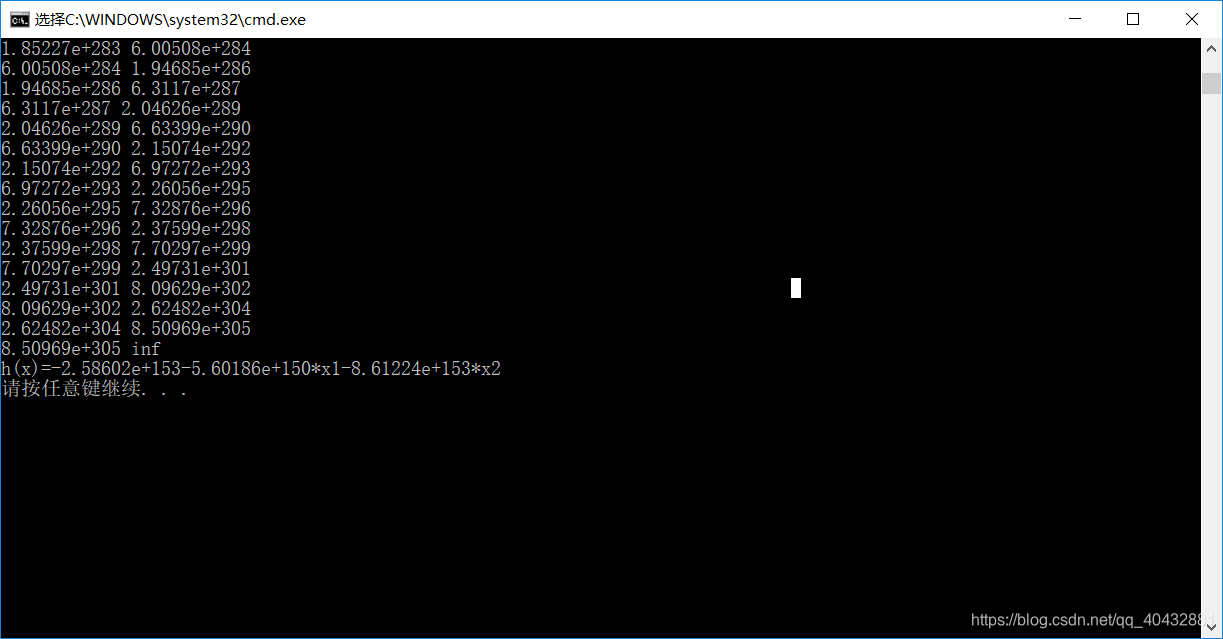
所以,可将学习率适当减小,通过不断测试得出一下结果:
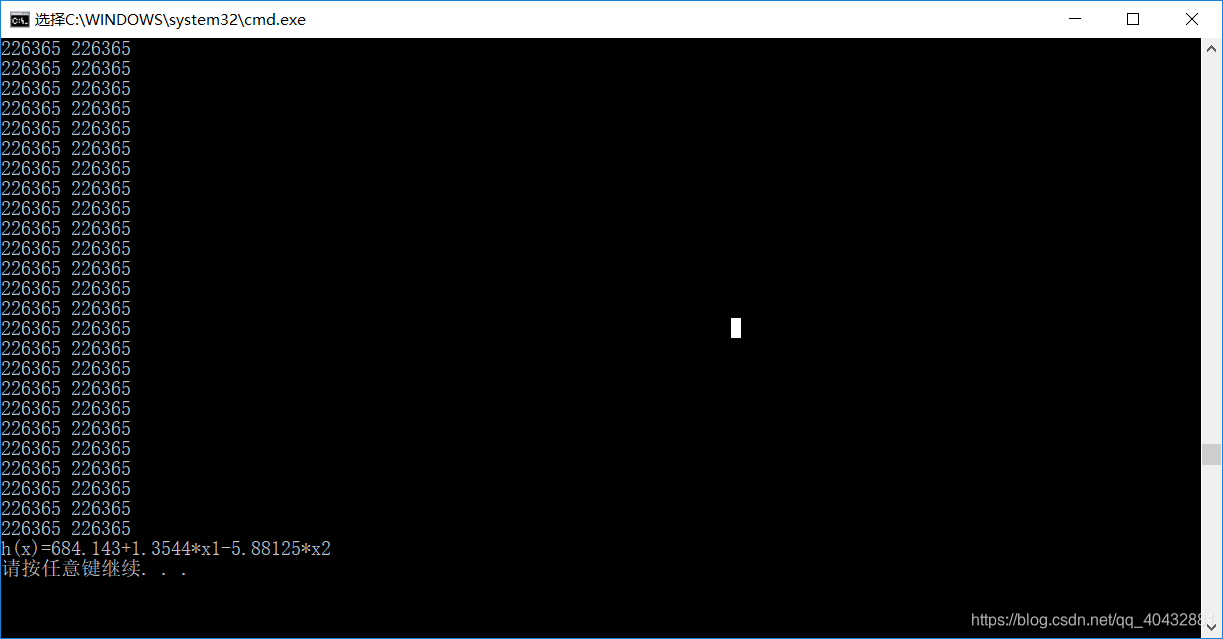
2.特征缩放:将所有特征缩放至【1–10】
特征缩放和特征还原:
void scaling(); //特征缩放器(将所有特征值统一缩放至1–10)
void scalback(); //特征还原(参数缩放)
在find函数中先进行特征缩放,将数据集内的特征值缩放,最后得出的对应参数便放缩(反向),之后再进行特征还原(例如特征值缩小,最后得出的参数便增大,需要将对应参数再进行缩小(缩小比例与特征值缩小比例一致))
Octave实现正规方程法
>> A=load('space(x1)_bedroom(x2).txt');
>> B=load('price(y).txt');
>> t=ones(47,1);
>> X=[t A];
>>Y=B;
>>par=pinv(X'*X)*X'*Y
par =
684.1446
1.3544
-5.8816
获得的参数向量与上面的梯度下降法得出的结果近似。