多变量线性回归
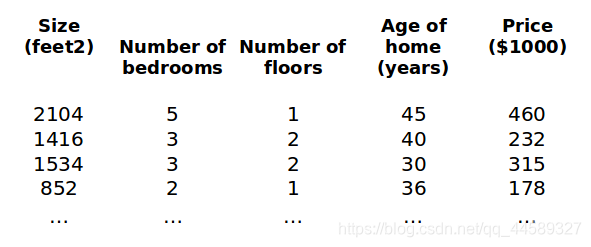
模型的特征为
(x1,x2,...,xn)
符号说明
n表示特征的数量
x(i)代表第
i个实例,即特征矩阵中第
i行
因此多变量的假设
h为:
hθ(x)=θ0x0+θ1x1+θ2x2+...+θnxn
其中
x0=1
此时特征矩阵$X$维度是
m∗(n+1),上述公式简化为:
hθ(x)=θTX
多变量梯度下降
在多变量线性回归中,我们也构建一个代价函数,则这个代价函数是所有建模误差的平方和,即:
J(θ0,θ1...θn)=2m1i=1∑m(hθ(x(i))−y(i))2
针对多变量梯度下降与单变量机理一样,挨个对每个
θ求导
计算代价函数
J(θ)=2m1i=1∑m(hθ(x(i))−y(i))2
其中:
hθ(x)=θTX=θ0x0+θ1x1+θ2x2+...+θnxn
引入
x0=1,得到通用的公式如下:
θj:=θj−αm1i=1∑m((hθ(x(i))−y(i))⋅xj(i))
特征缩放
最简单的方法:
xn=snxn−un
原始每个值减均值除标准差
学习率
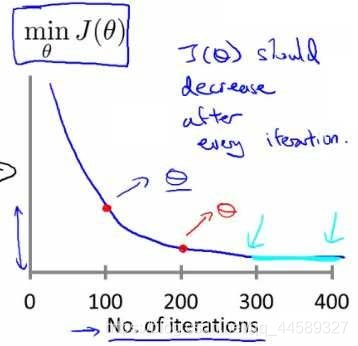
梯度下降算法的每次迭代受到学习率的影响,如果学习率
a过小,则达到收敛所需的迭代次数会非常高;如果学习率
a过大,每次迭代可能不会减小代价函数,可能会越过局部最小值导致无法收敛。
通常可以考虑尝试些学习率:
α=0.01,0.03,0.1,0.3,1,3,10
分别扩大三倍
正规方程
正规方程是通过求解下面的方程来找出使得代价函数最小的参数的:
∂θj∂J(θj)=0
假设我们的训练集特征矩阵为
X(包含了
x0=1)并且我们的训练集结果为向量
y,则利用正规方程解出向量
θ=(XTX)−1XTy
上标T代表矩阵转置,上标-1 代表矩阵的逆。
设矩阵
A=XTX,则:
(XTX)−1=A−1
梯度下降与正规方程的比较:
| 梯度下降 |
正规方程 |
| 需要选择学习率
α |
不需要 |
| 需要多次迭代 |
一次运算得出 |
| 当特征数量
n大时也能较好适用 |
需要计算
(XTX)−1 如果特征数量n较大则运算代价大,因为矩阵逆的计算时间复杂度为
O(n3),通常来说当
n小于10000 时还是可以接受的 |
| 适用于各种类型的模型 |
只适用于线性模型,不适合逻辑回归模型等其他模型 |
总结一下,只要特征变量的数目并不大,标准方程是一个很好的计算参数$\theta $的替代方法。具体地说,只要特征变量数量小于一万,我通常使用标准方程法,而不使用梯度下降法。
正规方程不可逆性及公式推导
θ=(XTX)−1XTy
如果
(XTX)不存在逆矩阵,及它是一个奇异矩阵,那么我们要用到伪逆
导致不可逆的原因:
在你想用大量的特征值,尝试实践你的学习算法的时候,可能会导致矩阵
X′X的结果是不可逆的。 具体地说,在
m小于或等于n的时候,例如,有
m等于10个的训练样本也有
n等于100的特征数量。要找到适合的
(n+1) 维参数矢量
θ,这将会变成一个101维的矢量,尝试从10个训练样本中找到满足101个参数的值,这工作可能会让你花上一阵子时间,但这并不总是一个好主意。因为,正如我们所看到你只有10个样本,以适应这100或101个参数,数据还是有些少
推导过程:
J(θ)=2m1i=1∑m(hθ(x(i))−y(i))2
其中:
hθ(x)=θTX=θ0x0+θ1x1+θ2x2+...+θnxn
X维度是
m∗n
θ是
n∗1
y是
m∗1
将向量形式转为矩阵形式如下:
J(θ)=21(Xθ−y)T(Xθ−y)=21(θTXT−yT)(Xθ−y)=21(θTXTXθ−θTXTy−yTXθ−yTyy)
接下来对
J(θ)偏导,需要用到以下几个矩阵的求导法则:
dBdAB=AT
dXdXTAX=2AX
dXdXTA=A
有如下:
dθd(θTXTXθ)=2XTXθ
dθd(θTXTy)=XTy
因此
∂θ∂J(θ)=21(2XTXθ−XTy−(yTX)T−0)=21(2XTXθ−XTy−XTy−0)=XTXθ−XTy
令
∂θ∂J(θ)=0
则有
θ=(XTX)−1XTy