多变量线性回归
(LinearRegression with Multiple Variables)
1. 多维特征
(Multiple Features)
目前为止,我们探讨了 单变量/特征 的回归模型,现在我们对 房价模型 增加更多的特征,例如房屋楼层等,构成一个含有多个变量的模型,对于每一个训练实例,其特征为
,如下图为
时:
 定义以下符号:
定义以下符号:
- :特征数量
- :第 个 训练实例,是一个向量(vector),例如上图的
- :第 个训练实例的第 个特征,例如上图的
假设函数
表示为:
进一步简化公式,引入
,则公式可以化为:
模型中的参数组合是一个
维的向量,任何一个训练实例的特征也是
维的向量。
注意:
这里的
是针对单个训练实例而言,并不是整个训练集,对整个训练集进行向量化得到特征矩阵,见下一篇 线性回归向量化及正规方程
2. 多变量梯度下降
(Gradient Descent for Multiple Variables)
与单变量线性回归类似,在多变量线性回归中我们也构建一个代价函数,等于所有建模误差的平方和,即:
其中
和单变量线性回归问题一样,我们的目标就是找出使得代价函数取得最小值的一个参数组合,其批量梯度下降算法为:
 求导后得到:
求导后得到:
 可以验证一下:
可以验证一下:
 与单变量线性回归一样,多变量线性回归中批量梯度下降算法的思想就是在开始时随机选择一个参数组合,根据计算所有预测结果及其代价函数,然后再给所有参数更新赋值,如此循环直到收敛为止。
与单变量线性回归一样,多变量线性回归中批量梯度下降算法的思想就是在开始时随机选择一个参数组合,根据计算所有预测结果及其代价函数,然后再给所有参数更新赋值,如此循环直到收敛为止。
除了用梯度下降法不断迭代来求解代价函数最小值,还有一种称为 正规方程(normal equations)的方法可以直接求解,见下一篇(4)线性回归模型向量化及正规方程
3. 梯度下降法实践
(Gradient Descent in Practice)
3.1 特征缩放
(Feature Scaling)
在面对多维特征问题的时候,要保证这些特征都具有相近的尺度,这将帮助梯度下降算法更快地收敛。
以房价问题为例,假设我们使用两个特征,房屋的面积 和 房间的数量,面积的值为 0-2000平方英尺,而房间数量的值则是0-5,以两个参数
和
分别为横纵坐标,绘制 代价函数 的等高线图,能看出图像会显得很扁,梯度下降算法需要非常多次的迭代才能收敛。

注1:上图呈竖直椭圆状的原因为:特征
相较于
大很多,则对应的
有较小波动时,就会导致代价函数产生较大的波动,即等高图中横轴方向的等高线比纵轴密集(看不懂等高图的可以参考这个链接:3D讲解等高线地形图)
注2:梯度下降时来回的波动称为震荡现象
解决的方法是尝试将所有特征的尺度都尽量缩放到-1到1之间。如图:

常用以下两种方法进行特征缩放:
-
均值归一化 Mean normalization
也称为 Z-score标准化 ,给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1。转化函数为: 其中 为所有样本数据的平均值, 为所有样本数据的标准差。量化后的特征将大部分都分布在[-1,1]之间。 -
Min-Max标准化(Min-Max Normalization)
也称为离差标准化,是对原始数据的线性变换,使结果值映射到[0 , 1]之间。转换函数如下: 其中max为样本数据的最大值,min为样本数据的最小值。这种方法有个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
3.2 学习率
(Learning Rate)
梯度下降算法收敛所需要的迭代次数根据模型的不同而不同,我们不能提前预知,但可以绘制迭代次数和代价函数的图表来观测算法在何时趋于收敛。如下图所示,
应该随着迭代次数增加而逐渐减小至趋于0。
 也有一些自动测试是否收敛的方法,例如将代价函数的变化值与某个阀值(例如0.001)进行比较,但通常看上面这样的图表更好。
也有一些自动测试是否收敛的方法,例如将代价函数的变化值与某个阀值(例如0.001)进行比较,但通常看上面这样的图表更好。
- 梯度下降算法的每次迭代受到学习率的影响,如果学习率过小,则达到收敛所需的迭代次数会非常高;
- 如果学习率过大,每次迭代可能不会减小代价函数,可能会越过局部最小值导致无法收敛。
通常可以考虑尝试些学习率:
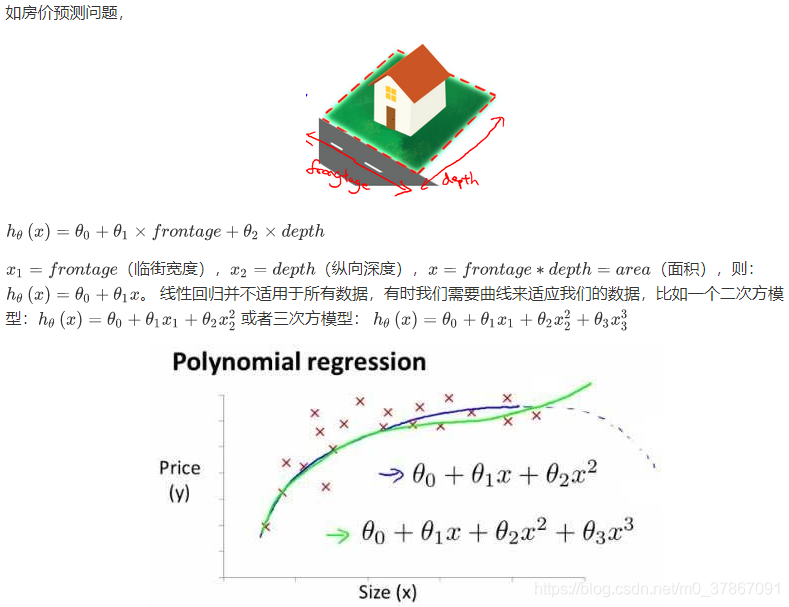
3.3 特征和多项式回归
(Features and Polynomial Regression)