论文:《DPGN: Distribution Propagation Graph Network for Few-shot Learning》,CVPR2020
代码:https://github.com/megvii-research/DPGN

一、概述
在给定少量标注数据(support集)的情况下,Few-shot learning旨在对未标注数据(query 集)进行预测。
有很多方法可以用于Few-shot learning任务,比如:
- 微调(Fine-tuning)方法,但容易过拟合
- 元学习(Meta-Learning)方法,但通常隐式利用样本全局关系
- 图网络(Graph Networks)方法,但只考虑了样本对关系,忽略了重要的分布关系
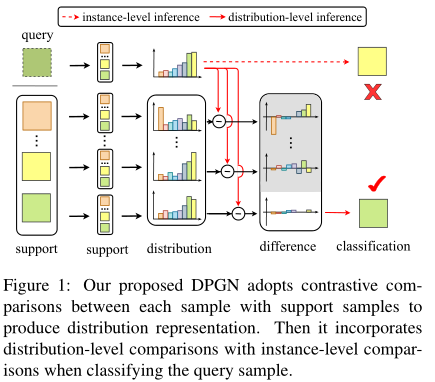
如上图所示,该论文提出了DPGN(Distribution Propagation Graph Network)模型,通过未标注数据和已标注数据之间的相似度分布,引导标签信息在图中更好地传播。该模型包含点图(Point Graph, PG)和分布图(Distribution Graph, DP)两个完全图,分别用于建模每个样本的实例级别表示和分布级别表示。具体的含义可以看方法部分。
总的来说,论文的创新点有三点:
- DPGN是第一个显式利用分布进行标签传播的图网络Few-shot learning方法。
- 提出了双完全图架构,结合了实例级别和分布级别的关系。
- 在四个Few-shot learning数据集上进行了实验,在分类任务上提升了5%12%的性能,并在半监督任务中提升了7%13%的性能。
二、方法
首先介绍Few-shot learning的问题定义,然后详细介绍DPGN模型的细节。
1 问题定义
每个Few-shot learning任务都有一个support集\(\mathcal{S}\)和一个query集\(\mathcal{Q}\),二者都属于训练集\(\mathbb{D}^{train}\)。\(\mathcal{S}=\{(x_1,y_1),\dots,(x_{N\times K},y_{N\times K})\}\)含有\(N\)个类别,每个类别有\(K\)个样本(也就是\(N\)-way \(K\)-shot),\(\mathcal{Q}=\{(x_{N\times K + 1},y_{N\times K + 1}) \dots, (x_{N\times K + \bar{T}},y_{N\times K + \bar{T}})\}\)含有\(\bar{T}\)个样本。在训练阶段,support集和query集的标签都是已知的。在测试阶段,模型需要根据测试集中的support集预测测试集中query集的标签。
2 DPGN

上图展示了DPGN模型的主要过程,该模型包含\(l\)层,每层包含一个点图(PG) \(G_l^p=(V_l^p, E_l^p)\)和一个分布图(DG) \(G_l^d=(V_l^d, E_l^d)\)。每一层的表示计算顺序基本构成一个环,即\(E_l^p \rightarrow V_l^d \rightarrow E_l^d \rightarrow V_l^p \rightarrow E_{l+1}^p\)。
为了进一步说明,节点集合\(V_l^p, V_l^d\)分别表示为\(V_l^p=\{v_{l,i}^p\}\),\(V_l^d=\{v_{l,i}^d\}\),边集合\(E_l^p, E_l^d\)分别表示为\(E_l^p=\{e_{l,ij}^p\}\),\(E_l^d=\{e_{l,ij}^d\}\),其中\(i,j=1,\cdots,T\),\(T=N\times K + \bar{T}\)。
\(v_{0,i}^p\)被初始化为特征提取器的输出:
2.1 点到分布聚合
2.1.1 点相似度
PG中的每条边都表示实例(点)之间的相似度,也就是样本之间的相似度。
当\(l=0\)时,PG的边定义为:
其中\(f_{e_0^p}:\mathbb{R}^m \rightarrow \mathbb{R}\)用于将向量映射为标量,论文使用两个Conv-BN-ReLU块实现。
当\(l \gt 0\)时,PG的边更新规则如下:
在实际应用中还要对\(e_{l,ij}^p\)进行归一化。
2.1.2 P2D聚合
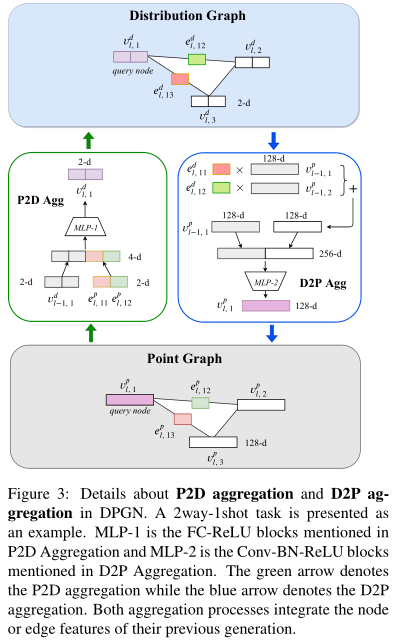
生成了PG中的边后,下一步就是生成DG中的节点表示。方法如上图所示,DG中每个节点都是维度为\(N\times K\)的特征向量,其中第\(j\)维表示该实例\(x_i\)与实例\(x_j\)的关系,\(N\times K\)就是support集大小。
当\(l=0\)时,DP的节点定义为:
其中\(||\)表示连接操作,\(\delta\)输出0或1表示标签\(y_i\)和\(y_j\)是否相等。
当\(l \gt 0\)时,DG的节点更新规则如下:
其中,\(P2D: (\mathbb{R}^{NK}, \mathbb{R}^{NK}) \rightarrow \mathbb{R}^{NK}\)是聚合网络,论文使用全连接层加ReLU层实现。
2.2 分布到点聚合
2.2.1 分布相似度
DG中每条边表示实例分布特征的相似度,也就是样本在分布空间的相似度。
当\(l=0\)时,DG的边定义为:
其中,\(f_{e_0^d}: \mathbb{R}^{NK} \rightarrow \mathbb{R}\)用于将向量映射为标量,论文使用两个Conv-BN-ReLU块实现。
当\(l \gt 0\)时,DG中边更新规则如下:
同样需要对\(e_{l,ij}^d\)进行正则化。
2.2.2 D2P聚合
接下来就是利用DG中的边特征,也就是样本的分布相似度,生成PG中的节点特征:
其中,\(D2P: (\mathbb{R}^m, \mathbb{R}^m) \rightarrow \mathbb{R}^m\),论文使用两个Conv-BN-ReLU块实现。
3 训练
为了进行节点分类,只需要将最后一层的边特征输入softmax函数即可:
其中,\(P(\hat{y_i}|x_i)\)就是样本\(x_i\)的预测概率分布,\(y_j\)是support集中第\(j\)个样本的标签,\(e_{l,ij}^p\)表示DPGN最后一层PG中的边特征。
3.1 点损失
点损失就是对节点进行分类的交叉熵损失:
其中,\(\mathcal{L}_{CE}\)是交叉熵函数,\(y_i\)是\(x_i\)的标签。
3.2 分布损失
分布损失实际上是在DG层面做节点分类:
模型最终的损失函数由每一层的两部分损失得到:
其中\(\hat{l}\)表示DPGN总的层数,\(\lambda_p,\lambda_d\)是权重参数。
三、实验
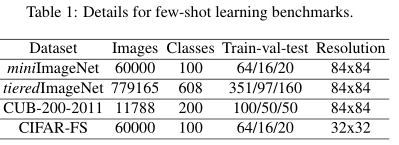
论文使用了四个Few-shot learning数据集
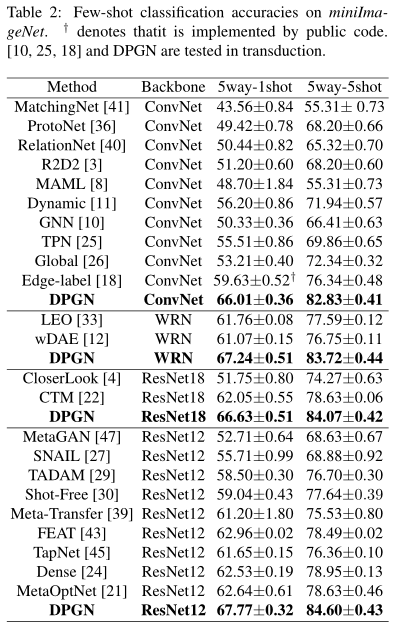
下面展示一个数据集的实验结果,其他数据集结果可以参照原论文