前言
本文提出了一个基于LSTM的meta-learner模型来学习最优化算法,该算法将用于训练另一个learner分类器(神经网络分类器)。meta-learner捕获了任务中的short-term知识,和所有任务中共有的long-term知识,由meta-learner模型优化的另一个learner分类器在每个任务上都能快速收敛。
除此之外,meta-learner模型还学习了适用于其它learner分类器的一般初始化,该初始化捕获了所有任务之间共享的基础知识,从而允许其它learner分类器在训练中能够快速收敛。
本文指出基于梯度的模型不能很好的处理few-shot的原因:
- 基于梯度的优化算法在更新次数有限制的情况下并不能表现得很好。具体来说,当处理非凸优化问题时,合理选择参数并不能使算法保持好的收敛速度,在经过数百万次迭代之后才能收敛到一个很好的程度;
- 对于每个不同的数据集,网络每次都要从一个随机初始化开始,这会损害网络仅需几次更新就可以收敛的能力。虽然迁移学习可以缓解这个问题,即先在标签充足的数据集上预训练一个网络,然后再对该网络进行微调,但如果预训练网络的任务偏离了目标网络的任务,这种方法也并不会特别有效。
一些设置
在机器学习中,数据集 通常被分为训练集 和测试集 ,在 上优化参数 ,在 上检验模型的泛化能力。在meta-learning中,meta-sets 包含多个数据集, 并且每个 都被分为 和
考虑 -shot -class分类任务,也就是说对于每个 , 包含 个类,每个类有 个标记样本,即 包含 个样本,而 包含的是一定数量的样本。
meta-sets被划分为 , 和 :
- :训练一个"学习过程"(即meta-learner模型),该过程使得在输入一个 的情况下,能够产生一个learner分类器,该分类器能在对应的 上获得较高的性能;
- :对meta-learner的超参数进行选择;
- :评估meta-learner的泛化能力。
为了对应few-shot learning,每个 都包含少量的标记样本,本文考虑 和 ,并且之后在对应的 上也能获得很好的性能。
meta-learning的设置如下图所示,上面是
,每个灰色的框中是一个数据集
,被分为
和
,这里考虑的是1-shot 5-class,即在
有5个类,每个类只有一个样本,而
中有两个样本。下面是
,它的
和
的设置和上面的一样,但是
中的
里有一些类是
中从未出现过的。

算法思路
考虑一个单独的数据集,或episode,
,假设需要在
上训练一个参数为
的learner分类器,那么需要用梯度下降的一些变体来训练该网络,更新形式如下:

其中
是learner在
次更新后的参数,
是在时间
时的学习率,
是learner在
时刻更新后优化的损失,
是损失相对于参数
的梯度,
是learner需要更新的参数。
作者观察到,式(1)的那种更新,和LSTM中单元状态(cell state)
的更新是有些类似的:

如果
,
,
,
,那么这两个式子确实差不多。
因此,本文训练了一个基于LSTM的meta-learner,它的目标就是学习LSTM的更新规则,然后将其应用于训练另一个神经网络(learner分类器)上。 将LSTM的单元状态设置为meta-learner的参数,即
,将候选单元状态设置为
,给出梯度信息对优化有多大价值。然后还定义了输入门
和遗忘门
,使meta-learner能够通过更新过程来确定最优值:
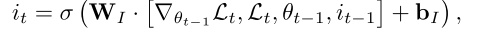
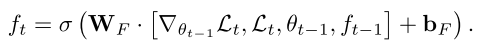
- 对于输入门 ,它的作用相当于学习率 ,它是当前参数 、当前梯度 、当前损失 以及先前学习率 的函数;
- 对于遗忘门 ,它代表着上一轮参数 所占的权重,在式(2)中只是简单的将其固定为1,但在这里1并不是最优值。当meta-learner目前处于一个糟糕的局部最优状态,并且需要大幅更新以逃离当前位置时,缩小meta-learner的参数并且遗忘先前的部分值是合理的。这对应于损失很高但梯度接近于0的情况。因此,与 一样, 也由四项得到。
除此之外,本文还指出可以学习LSTM单元状态的初始值 ,将其作为meta-learner的参数,这对应于learner分类器的初始权值。这样当来一个新任务时,meta-learner能够给它一个较好的初始值,从而能够快速学习。
参数共享
由于meta-learner用于为另一个深度神经网络生成更新,而该神经网络包含成千上万个参数,因此为了避免meta-learner发生"参数爆炸",需要采用某种参数共享策略,即在learner梯度的coordinates上共享参数。这意味着每个coordinate虽然都有自己的单元状态,但它们在LSTM上的参数都是相同的,因此可以用一个紧凑的LSTM模型对每个coordinate使用相同的更新规则。这样,在输入是梯度coordinate的batch,和每个维度 的损失 的情况下,就可以很轻松的实现参数共享。
由于梯度的coordinate和损失有很大的不同,因此本文还对它们做了一个归一化处理:
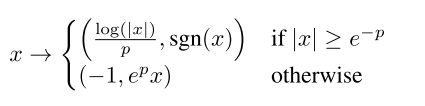
训练
接下来就要对基于LSTM的meta-learner模型进行训练了,并且该模型应该能够很好的处理few-shot learning任务。训练的关键点就是,训练时的场景需要和测试时的场景保持一致。给定训练集
上的一系列梯度和损失,meta-learner需要提供参数以对另一个分类器进行更新,从而使该分类器能够在测试集
上获得良好的性能。过程如下图所示:
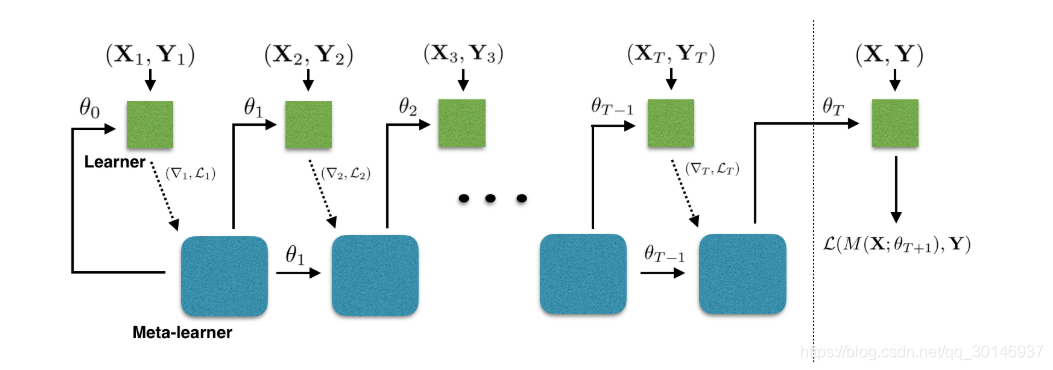
图中虚线左边是
,右边是
,虚线箭头表示为了与测试时的场景相匹配,训练目标是在测试集
上生成的分类器的损失
,当在训练集
上进行迭代时,meta-learner在每一个时间步
从分类器接收
,并提供新的参数集
,这个过程重复
个步骤,然后在
上评估分类器及其最终参数,以产生损失,然后该损失用于训练meta-learner,训练算法如下图所示:

独立梯度假设
注意到分类器的梯度和损失其实取决于meta-learner的参数,因为分类器是根据meta-learner提供的参数集进行更新的,然而这会使meta-learner的梯度计算变得复杂。因此本文做了一个小小的假设,即分类器产生的梯度和损失对meta-learner的梯度计算是没有贡献的,也就是说两部分梯度是独立分开的,因此分类器的那部分梯度对于meta-learner的梯度计算是可以忽略的。这就避免了二次求导,使得meta-learner依然能够很有效率地被训练。
meta-learner的初始化
在训练基于LSTM的meta-learner时,最好用一个较小的权重来对LSTM进行初始化,并且将遗忘门偏差设置的尽可能大,从而使得遗忘门被初始化为接近于1,开启梯度流;而对于输入门偏差来说应将其设置的尽可能小,从而使meta-learner使用的输入门的值在开始时较小,即以一个较小的学习率开始。
