前言
本文提出了用于few-shot learning的原型网络(prototypical network),它的基本思想是,在一个embedding空间中,每个类都有一个原型表示(prototypical representation),每个类的点都聚集在这个原型表示周围。具体来说就是,通过一个非线性映射将输入映射到一个embedding空间中,提取每个类别中样本的均值(mean)作为该类在embedding空间中的原型(prototype),那么对于一个embedded point来说,分类就是找到离它最近的类原型。使用属于Bregman divergence的欧几里得距离作为度量距离,在训练时,让测试样本到自己所属的类的原型的距离越近越好,到其它的类原型越远越好;测试时,对测试样本到各个类原型的距离做softmax,预测测试样本的类别标签。
原型网络
在few-shot分类中,给定一个支持集 ,其中有 个带标签的样本,即 ,每个 是一个样本的 维的特征向量, 是其对应的类别标签, 表示类别为 的支持集。
原型网络通过一个嵌入函数
为每个类计算一个
维的原型
,即将维度为
的数据映射到
维的embedding空间中,每个类的原型
是支持集中样本的embedding的均值向量:
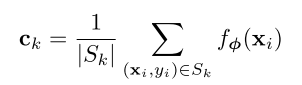
给定一个距离函数
计算query point
和各个类原型之间的距离,原型网络通过将softmax作用在这些距离上,得到
的类别概率分布:
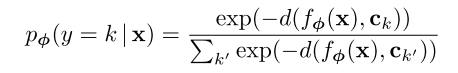
训练过程就是通过SGD最小化目标函数
,其中
是训练样本的真实标签。训练时的episode为:从训练集中随机选择一个类子集,在每个类中选择一些样本作为支持集,从剩余的样本中再选出一些作为query point,伪代码如下:

在这个算法中,
是训练集中样本的数量,
是训练集中类别的数量,
是每个episode中被选择的类别的数量,
是每个类的支持集中的样本数量,
是每个类的query样本的数量,
表示从
中随机选出
个元素。
- 输入是训练集 , 表示该数据集中所有样本的类别都为
- 最后要得到的是一个训练episode的损失
- 首先从 个类中随机选出 个类
- 然后对于 个类中的每一个类,选择 个样本作为支持集,再从剩下的样本中选出 个作为query样本,最后计算每个支持集的类原型
- 将损失
初始化为0,对于每个query样本计算损失
为:
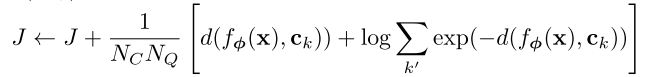
关于原型网络的两种解释
1. 将原型网络看作混合密度估计
原型网络中对于距离的度量属于Bregman散度,其中就包括平方欧氏距离和马氏距离,本文使用的就是平方欧氏距离。本文对于原型的计算可以看作是在支持集上的hard clustering,每个类都有一个簇,支持集中的每个样本都被分配到其对应的类簇。对于Bregman散度来说,如果一个cluster representative到该聚类中所有点的距离最小,那么它就是该聚类的平均(mean),因此原型的计算就是使用Bregman散度在支持集中计算出最佳的cluster representative,即找到最优的聚类中心。
2. 将原型网络解释为线性模型
当使用欧氏距离时,原型网络模型中的softmax相当于有特定参数的线性模型,代入
并展开得到:
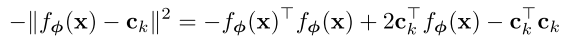
第一项对类别
来说是常量,不会对softmax概率造成影响,将后两项写成线性模型为:
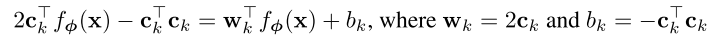
本文的结果证明,尽管可以等同于线性模型,但欧氏距离依然是一个有效的选择,作者猜想这是由于在嵌入函数中已经学到了所需的非线性元素,因此使用欧氏距离使得方法更加简单有效。
与Matching Networks的比较
原型网络和MatchingNet在few-shot方面是不同的,但两者在one-shot上是相同的。MatchingNet在给定支持集的情况下产生了一个加权最近邻分类器,而原型网络使用平方欧氏距离产生了一个线性分类器。在MatchingNet中,提出了一系列对网络结构的扩展,包括解耦支持样本和query样本的嵌入函数、使用FCE等,这些或许可以和原型网络结合起来,但会增加参数,并且FCE使用双向LSTM对支持集进行任意排序,这些都使网络结构变得更复杂。本文证明使用简单的设计也能达到同样的性能。
在one-shot方面,当每个类的支持集中只有一个样本时, ,即原型就是那个样本,此时原型网络和MatchingNet是可以等同的。
还有一个问题就是,在每个类的支持集中设置多个原型会不会更有用。如果每个类的原型的个数是固定的并且大于1,那么需要一种划分机制来进一步对属于一个类的样本点进行聚类,这就需要另一个单独的划分阶段,这个阶段和权重的更新是分开的,而本文的方法,即只设置一个原型,只需要用简单的梯度下降方法去学习。
一些其他的设计思路
1. 距离度量
MatchingNet中使用的是余弦距离,虽然说原型网络和MatchingNet使用任何距离度量都是可行的,但作者发现,使用平方欧氏距离能使两种网络都得到提高。作者认为这是由于余弦距离并不属于Bregman散度,因此网络也并不能等同于混合密度估计。
2. episode的设置
以往的实验发现,在训练和测试是保持相同的episode设置往往会获得较好的结果,比如在测试时使用5-way 1-shot的方式,那么训练时的episode就应该设置为 , ,其中 是从数据集中选择的类别的个数, 是每个类中被选为支持集样本的个数。然而本文发现,使用比测试时更高的 (way)对模型更有益,在实验中,根据保留的验证集对 进行调整。不过对于 来说,在训练和测试时shot的设置最好保持一致。
原型网络对于zero-shot所做的一些改动
zero-shot和few-shot还是有些不同的,few-shot为每个类生成一个支持集,而在zero-shot中,为每个类设置一个元数据向量 , 是根据每个类的属性描述、原始数据等生成的,也即每个类的原型是一个事先知道的元数据向量 ,也可以通过学习来得到。也可以简单的修改原型网络使其能够处理zero-shot learning:简单的定义 ,为元数据向量的embedding。由于元数据向量和query point来自不同的输入域,作者发现可以固定原型embedding的长度为单位长度,而对query embedding不设限制。

