论文:https://arxiv.org/pdf/2003.14247.pdf
源代码:https://github.com/megvii-research/DPGN
目录
Distribution Similarities(分布相似度)
核心内容
本文提出了一种基于双图神经网络的小样本学习算法。基于传统的实例级关系(instance-level relation),本文引入了分布级关系(distribution-level relation)来进行深入的研究。为将两种关系合理地结合起来,本文构建了涵盖了点图(PG,Point Graph)和分布图(DG, Distribution Graph)的双图神经网络,基本框架如图2(Figure 2)所示。并通过PG与DG互相影响的循环结构来进行迭代从而收敛,进而得到预测结果。
分布级关系
分布级关系是本文的关键点。本文对于分布级关系的描述可如图1(Figure 1)所示。首先将所有的支持集(support set)和查询集(query set)一起带入到基于实例特征(instance feature)的实例级相似性(instance similarity)的计算中,并且基于相似性结果构建了分布级关系表达(distribution-level representation),即图中的柱状图所示,每个柱状代表着每个sample与整个set之间的相似性。在进行预测的时候则将query set中的sample与 support set的分布级关系进行比较,根据差异结果来进行相应的预测,差异越小则表示属于该类别的可能性越大。

DPGN网络结构及实现算法
DPGN网络结构分析

首先通过一层convolutional backbone来提取all samples(support+query)的instance-level feature,作为节点的特征,并计算instance similarities来作为边的特征,之后利用这些边特征通过P2D算法来构成DG,其中节点特征(of DG)由PG的位置顺序累计边特征(of PG)初始化,边特征(of DG)则表示节点特征相似性(of DG)表示,最终,得到的边特征(of DG)通过D2P算法被传回GP去更新节点特征(of GP),并重复上述流程。图中的箭头表示(edge to node 和node to edge的转换)
Instance Similarities(实例相似度)
Point(instance) similarity(edge in PG):PG中每条边的特征表示所连两节点的相似性,计算公式如下。

0表示此为初始值,i,j 为node,是将实例相似性(Instance Similarities)转换为一定规模大小的编码网络。具体而言该网络包含了两个Conv-BN-ReLU阶段,以及输出层采用sigmoid。
在非初始阶段,

l表示为generation次数,而且为合理融合全局信息,会在全局Instance Similarities计算之后进行一次normalization.
Distribution Similarities(分布相似度)
Distribution Similarity与Instance Similarities十分类似,用DG中的edge feature来表示 distribution features of different samples,公式以及网络处理层,以及最后的normalization均与之前类似。计算公式如下,不再重复叙述。


P2D和D2P

P2D主要的目的是将PG中边特征(Instance Similarities)传递到DG中边计算相应的节点特征。初始值计算和迭代计算公式如下;
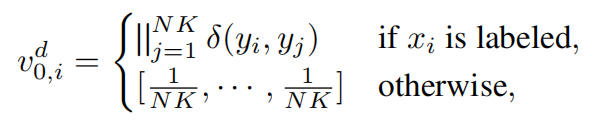

连接运算符用 ‘||’表示。它可以把列与列、列与字符连接在一起,从而起到合成自定义新列的作用。其中y表示相应的标签。在初始计算,直接得到NK维度的计算结果。在迭代计算中,利用PG中NK个边特征(Instance Similarities)与上一次迭代的NK维度的DG的节点特征,通过P2D(由全连接层和ReLU组成)将两个NK维度向量连接成NK维度的向量。
D2P与P2D的目的以及实现过程也十分类似。其主要将DG中的边特征(Distribution Similarities)传递到PG从而更新PG中节点特征。计算公式如下,D2P网络也是由全连接层和ReLU组成。
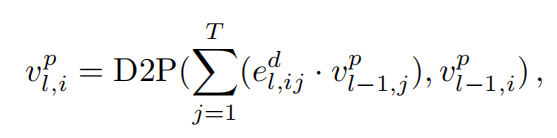
输出层

当经历l次迭代后,根据最后一次的PG的边特征(Instance Similarities)结合one-hot,通过softmax来输出预测结果。
损失函数
这部分比较简单就不再细述了。
Point loss
![]()
![]()
Distribution loss

Total loss

![]()
论文亮点
1.率先引入了distribution propagation
2.Dual Complete Graph Network
3.achieve a significant improvemwnt .
采用DPGN可以使弱监督小样本学习更加简单,尤其当支持集含有labeled and unlabeled samples for each class.或者说DPGN为labeled 和unlabeled smaples通过分布相似性的形式搭建了联系的桥梁,这位弱监督小样本学习制造了更好的标签预测。
代码分析
运行代码前的准备工作
(1)数据集
源代码默认使用的是MiniImagenet数据集,但与官方提供的有所不同,作者对其进行了一定的处理分类,所以最好使用作者提供的数据集,否则会带来一定的麻烦。同时作者还用了其它3种数据集,下载网址如下。
[Mini-ImageNet](https://drive.google.com/open?id=15WuREBvhEbSWo4fTr1r-vMY0C_6QWv4w)
[Tiered-ImageNet](https://drive.google.com/file/d/1nVGCTd9ttULRXFezh4xILQ9lUkg0WZCG)
[CIFAR-FS](https://drive.google.com/file/d/1GjGMI0q3bgcpcB_CjI40fX54WgLPuTpS)
[CUB-200-2011](https://github.com/wyharveychen/CloserLookFewShot/tree/master/filelists/CUB)
(2)运行环境
如果在本地运行的话,首先得把数据集下载下来,但由于数据集过大,且在google drive,就算翻墙也很难成功的下载下来,得配合IDM进行下载。
如果使用google的colab的话,则仅需将google drive的上的数据集保存到自己的google drive上,再在代码上修改相应的路径即可,会省去许多的麻烦。
(3)一个代码的小问题
![]()
可以参考这篇博客,https://blog.csdn.net/jsk_learner/article/details/103833034
修改后的代码为:

Backbone
本文的代码大致分为5部分:main,dataloader ,dpgn,backbone,utils,本文主要介绍dpgn和backbine。而backbone主要用来进行最开始的instance features的extract network。在该部分主要设计了基本的ResNet12网络结构以及Conv4网络。
Resnet12的网络设计也无太大的改动,基本上为先设计基本的残差网络模块(包含3层卷积网络+残差输出结构),再设计基本的输入层和输出层即可。
Conv4的输出层和隐藏层也为基本的卷积网络结构,只是在最后的输出层有所不同,最后的输出结构为第三层卷积网络输出结果分别经历第四层卷积网络和最大池化层的两种结构的连接结合体。
import torch.nn as nn
class ResNet12Block(nn.Module):
"""
ResNet Block
"""
def __init__(self, inplanes, planes):
super(ResNet12Block, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes)
self.relu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
self.conv = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn = nn.BatchNorm2d(planes)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
def forward(self, x):
residual = x
residual = self.conv(residual)
residual = self.bn(residual)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += residual
out = self.relu(out)
out = self.maxpool(out)
return out
class ResNet12(nn.Module):
"""
ResNet12 Backbone
"""
def __init__(self, emb_size, block=ResNet12Block, cifar_flag=False):
super(ResNet12, self).__init__()
cfg = [64, 128, 256, 512]
# layers = [1, 1, 1, 1]
iChannels = int(cfg[0])
self.conv1 = nn.Conv2d(3, iChannels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(iChannels)
self.relu = nn.LeakyReLU()
self.emb_size = emb_size
self.layer1 = self._make_layer(block, cfg[0], cfg[0])
self.layer2 = self._make_layer(block, cfg[0], cfg[1])
self.layer3 = self._make_layer(block, cfg[1], cfg[2])
self.layer4 = self._make_layer(block, cfg[2], cfg[3])
self.avgpool = nn.AvgPool2d(7)
self.maxpool = nn.MaxPool2d(kernel_size=2)
layer_second_in_feat = cfg[2] * 5 * 5 if not cifar_flag else cfg[2] * 2 * 2
self.layer_second = nn.Sequential(nn.Linear(in_features=layer_second_in_feat,
out_features=self.emb_size,
bias=True),
nn.BatchNorm1d(self.emb_size))
self.layer_last = nn.Sequential(nn.Linear(in_features=cfg[3],
out_features=self.emb_size,
bias=True),
nn.BatchNorm1d(self.emb_size))
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='leaky_relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def _make_layer(self, block, inplanes, planes):
layers = []
layers.append(block(inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
# 3 -> 64
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
# 64 -> 64
x = self.layer1(x)
# 64 -> 128
x = self.layer2(x)
# 128 -> 256
inter = self.layer3(x)
# 256 -> 512
x = self.layer4(inter)
AdaptiveAvgPool2d = nn.AdaptiveAvgPool2d((1,1))
x = AdaptiveAvgPool2d(x)
#x = self.avgpool(x)
x = x.view(x.size(0), -1)
# 512 -> 128
x = self.layer_last(x)
inter = self.maxpool(inter)
# 256 * 5 * 5
inter = inter.view(inter.size(0), -1)
# 256 * 5 * 5 -> 128
inter = self.layer_second(inter)
out = []
out.append(x)
out.append(inter)
# no FC here
return out
class ConvNet(nn.Module):
"""
Conv4 Backbone
"""
def __init__(self, emb_size, cifar_flag=False):
super(ConvNet, self).__init__()
# set size
self.hidden = 128
self.last_hidden = self.hidden * 25 if not cifar_flag else self.hidden
self.emb_size = emb_size
# set layers
self.conv_1 = nn.Sequential(nn.Conv2d(in_channels=3,
out_channels=self.hidden,
kernel_size=3,
padding=1,
bias=False),
nn.BatchNorm2d(num_features=self.hidden),
nn.MaxPool2d(kernel_size=2),
nn.LeakyReLU(negative_slope=0.2, inplace=True))
self.conv_2 = nn.Sequential(nn.Conv2d(in_channels=self.hidden,
out_channels=int(self.hidden*1.5),
kernel_size=3,
bias=False),
nn.BatchNorm2d(num_features=int(self.hidden*1.5)),
nn.MaxPool2d(kernel_size=2),
nn.LeakyReLU(negative_slope=0.2, inplace=True))
self.conv_3 = nn.Sequential(nn.Conv2d(in_channels=int(self.hidden*1.5),
out_channels=self.hidden*2,
kernel_size=3,
padding=1,
bias=False),
nn.BatchNorm2d(num_features=self.hidden * 2),
nn.MaxPool2d(kernel_size=2),
nn.LeakyReLU(negative_slope=0.2, inplace=True),
nn.Dropout2d(0.4))
self.max = nn.MaxPool2d(kernel_size=2)
self.layer_second = nn.Sequential(nn.Linear(in_features=self.last_hidden * 2,
out_features=self.emb_size, bias=True),
nn.BatchNorm1d(self.emb_size))
self.conv_4 = nn.Sequential(nn.Conv2d(in_channels=self.hidden*2,
out_channels=self.hidden*4,
kernel_size=3,
padding=1,
bias=False),
nn.BatchNorm2d(num_features=self.hidden * 4),
nn.MaxPool2d(kernel_size=2),
nn.LeakyReLU(negative_slope=0.2, inplace=True),
nn.Dropout2d(0.5))
self.layer_last = nn.Sequential(nn.Linear(in_features=self.last_hidden * 4,
out_features=self.emb_size, bias=True),
nn.BatchNorm1d(self.emb_size))
def forward(self, input_data):
out_1 = self.conv_1(input_data)
out_2 = self.conv_2(out_1)
out_3 = self.conv_3(out_2)
output_data = self.conv_4(out_3)
output_data0 = self.max(out_3)
out = []
out.append(self.layer_last(output_data.view(output_data.size(0), -1)))
out.append(self.layer_second(output_data0.view(output_data0.size(0), -1)))
return out
运行结果
在colab上测试了miniimage数据集,第5000个step和第9000个step的结果如下,准确率并没有太大的提升,可能是训练次数不够或者是batchsize的原因(此环境下train的batch_size为10).

