小样本学习
来源:我们人类是具有快速从少量(单)样本中快速学习能力的,其实在我们学习的过程中,人类的大脑将对象和类别组成有用的信息将之分类。
首先需要声明的是,小样本学习属于迁移学习。接着,举个例子详细阐述。
人类从未见到过“澳大利亚的鸭嘴兽”,给我们一张鸭嘴兽的照片后,人类就认识了!
有的朋友可能会想,为什么我们人类总是能快速的学习到未知的事物?简单的说,是因为人类生活中各种知识的积累以及人类天生的思考能力(如:类比能力)。知识的积累意味着我们是存在各种知识的先验的,天生的思考能力意味着我们拥有强大的类比能力、强大的大脑算力。
以“人类从未见到过“澳大利亚的鸭嘴兽”,给我们一张鸭嘴兽的照片后,人类就认识了!”这句话为例。鸭嘴兽就代表未知的事物(new class),而我们生活中已经见到过的鸭子、狸猫、鱼等动物就代表知识的先验,我们把这种知识的先验称为 元知识(Meta Knowledge),我们大脑的能快速的把从未见过的鸭嘴兽与这些元知识快速的类比(可能还存在一些其他脑力活动,如视觉提取物体的特征),得出结论:这个长得像鸭子嘴,还能像鱼一样游泳、身形扁扁的新动物就是鸭嘴兽。
这里有的朋友可能会疑问了,如果你是一个刚学会走路的孩子,什么都没见过,是否还存在这种快速的样本学习能力呢?可以这么想,人生来都是初始化的,装备全靠打,IQ 高的元知识积累的就快,IQ 低的元知识积累的就慢。
机器学习目前都是类比人类的智能来做的,那么对应我们的机器模型,few-shot learning 又是怎么样的呢?
对应我们的机器模型,few-shot learning 的核心任务可以当成 识别新的类。 例如:我们已经通过些许动物(狗除外)的样本训练出来了模型,我们想让模型识别新的类-----狗。显然,这就是要把源知识(source)迁移到包含狗的知识领域来(target)。显然这正是 迁移学习 的范畴。这时候我们需要识别新的类------狗,比较简单的解决方案是什么呢?绝大部分同学会想到,把源模型当做预训练模型,修改全连接层,进行 fine-tune。需要注意的是:- 源模型是需要大量带 label 的样本训练的,一般的如 Imagenet上预训练模型
- fine-tune 也是需要样本量的支持的,不然 retrain 全连接层时很容易过拟合。
fine-tune 本质还是依赖深度学习 big data 喂餐的策略,仿佛与我们的小样本学习背道而驰。
我们来看看真正的 few shot 吧~
为了完成识别新类(狗)的问题,于是需要新来一张标好 label 的样本(如 :有 label,样本是田园土狗, 称作 sample set 或 support set)用来泛化模型,那么再来 test 样本时候(如:无 label,样本是哈士奇,称作 query set 或者 test set),我们就可以把这个 哈士奇的样本 label 标出来,达到分类的目的。这种学习叫做 one-shot learning,即单样本学习。
同样的,如果刚才来的是一堆标好 label 的样本(除了田园土狗,可能还有京巴、吉娃娃、泰迪等做 support set),这种学习叫做 few-shot learning,即小样本学习,一般 few 不会大于 20。
经过我上边的介绍,可以对小样本学习做个定义:

自己的话解释一下就是: 模型只有少量的有 label 的训练样本 S ,S 中包括 N 个样本,yi 代表各样本的 label。因为测试样本集中每个样本都有一个正确的类别,我们希望,再来新的待分类的测试样本 x’ 时候,正确预测出 x' 标签是 y'。
注: 把每个类别 yi 的单个样本换成 k个样本就 变成了k-shot learning , few-shot 一般指的是 k 不超过 20。
解决小样本问题的一种模型(孪生网络)
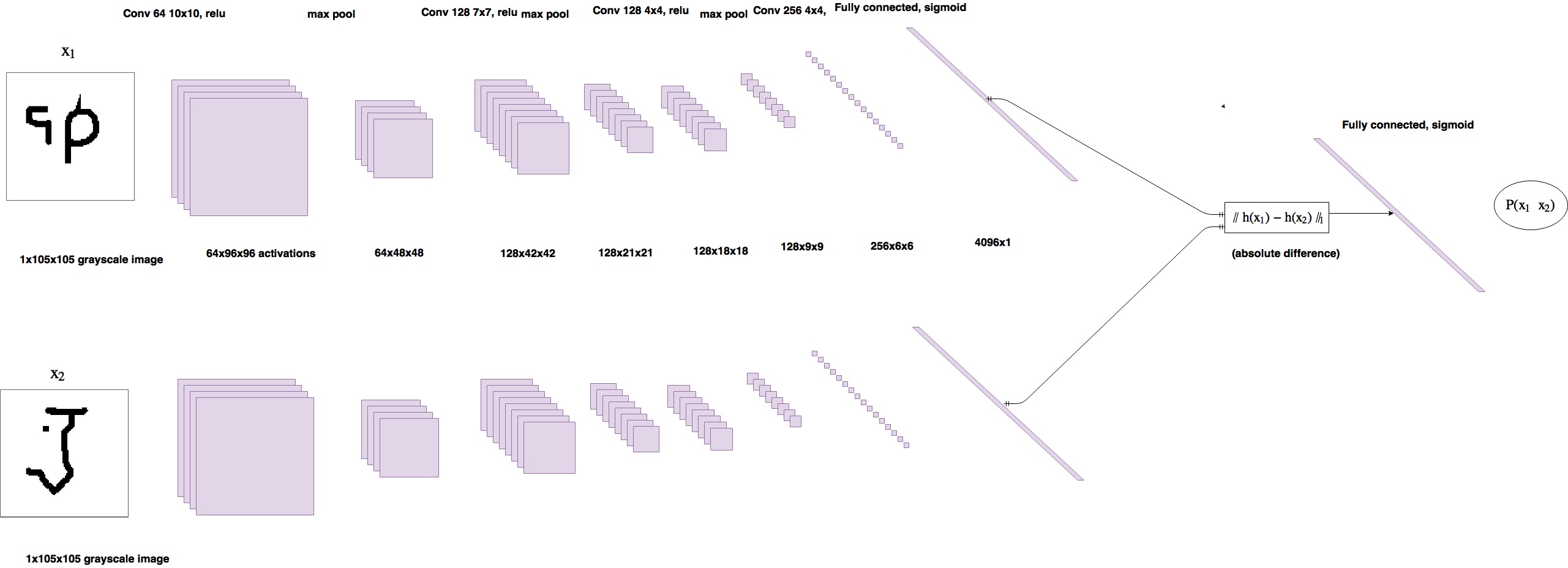
结构意思就是:输入两张图片到两个 CNN, 来比较两种相同类别的概率。具体可查看 https://sorenbouma.github.io/blog/oneshot/
如下图简单理解一下小样本的训练方式:
| Training(训练模型) | Sample Set | Query Set |
| Testing(测试模型) | Support Set | Test Set (无label) |
训练和测试过程是相似的,拿 Omniglot 数据集为例。
- 此数据集可以认为是小样本学习的一个基准数据集。
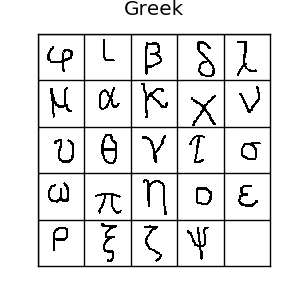
- 它一共包含1623 类手写体,每一类中包含20 个样本。其中这 1623 个手写体类来自 50 个不同地区(或文明)的 alphabets,如:Latin 文明包含 26 个alphabets,Greek 包含 24 个alphabets。
一般用于训练的是 964 类(30个地区的字母),用于测试的是 659 类 (20个地区的字母)。
训练的目的就是,用 964 个类来训练模型,识别 659 个新的类。 - 如下图的 24个 希腊字母,代表 Greek 文明下的 24 个类,每个字母只有 20 个样本。
Training:
- 每次 iteration 从 964 个类中随机的选择 20 个类,从每个类中的 20 个样本采样 5 个作为 support set,5 个 作为 query set。(选择的这个数目可以自行改变)。
以孪生网络为例,就是 query set 中的图片不断的于 support set 的图片成对组合,训练模型,确定模型参数。
Testing:
- 测试过程,对 659 个类中随机选择 m 个类,每个类提供 k 个样本作为 Support Set 来泛化模型。称为 m-way k-shot。
以孪生网络为例,在 m 个类中,若 Support Set 每类都为单样本(即 m 个样本),送进来的 Query Set ( 同样的是 m 个类 )不断的与 Support Set 成对相似度量,若相似,则归于该类。