Few-Shot Learning(小样本学习)与 Mata-Learning(元学习)
小样本学习问题:学会区分图片之间是相同的还是不同的,模型判断两个图片是否异同

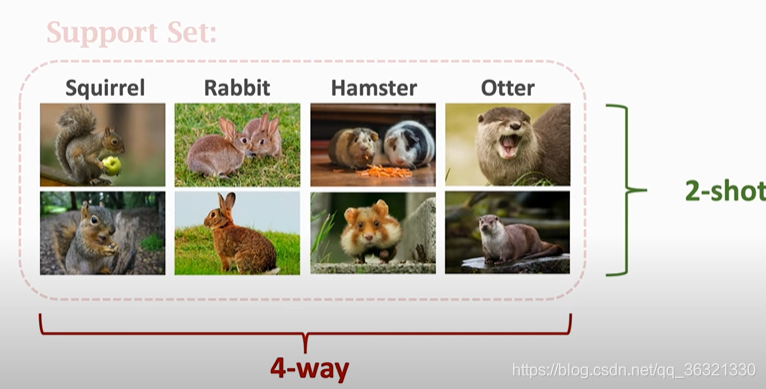
Support Set: 带有标签的图片,(每类有2个图片),在预测的时候提供一些额外的信息

Meta learning: 让模型自己学会学习

6 way 1 shot
way 越大,分类准确率会降低
shot越大,分类准确率会增加
Learn a Similarity Function

1.先从一个大数据集中学习一个相似度函数
2.使用相似度函数做预测(使用Query中的图 与 Support Set中的图进行依次求相似度,得到最相似的类别)
Dataset:

mini-imagenet
Siamese Network (孪生网络)
每次取两个样本,计算相似度
1.从数据集中随机抽样获得正样本和负样本

2. 构建卷积神经网络用于获取特征,获得特征向量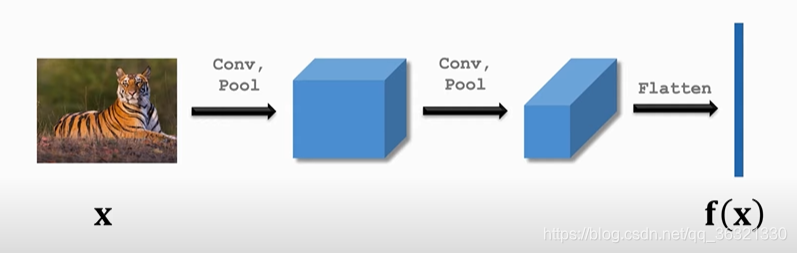
3. 训练孪生网络
在这里插入图片描述](https://img-blog.csdnimg.cn/20200810212005144.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM2MzIxMzMw,size_16,color_FFFFFF,t_70)
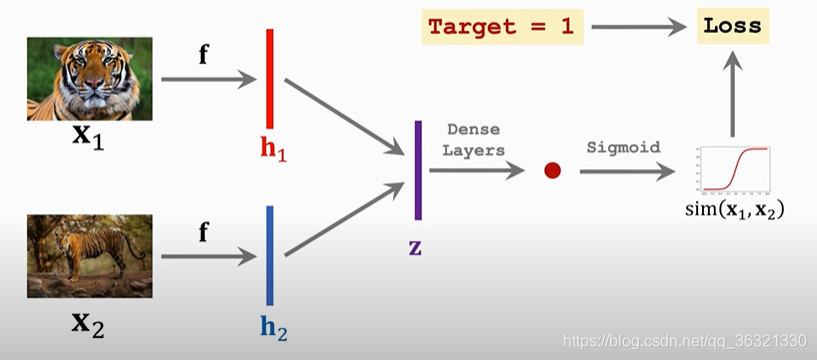
提取特征的网络是一个,图片经过提取特征的网络之后得到特征向量h1, h2, z = | h1 - h2 | , 表示x1 和 x2 向量之间的差别,在经过Dense Layers + Sigmoid来处理z向量 获得一个标量,来表示x1 和 x2之间的相似度。
正样本的数目和负样本的数目要一致。
4.one-shot prediction

Support Set 不在训练集中,判断Query属于哪个类。
Triplet Loss
- 准备训练数据

选择一个anchor图片(比如Tiger类中最下面的那个),在同类中选择一个正样本,在不同类中选择一个负样本。
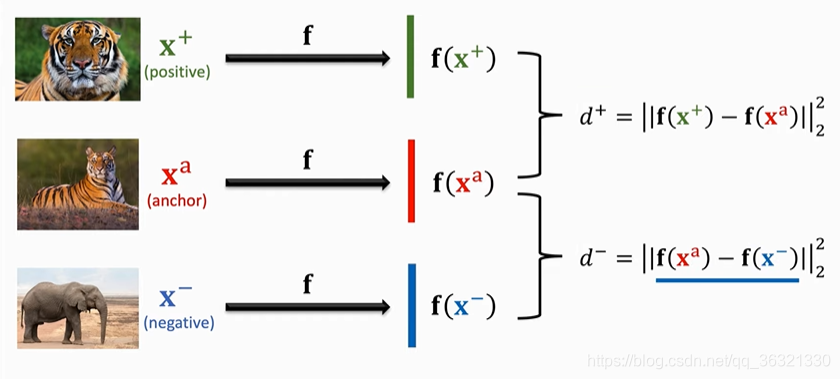
我们希望d+ 很小,d-很大。
根据我们所希望的,定义损失函数

α是一个超参数

计算特征向量之间的距离,取最小的。
(测试的这个数据 在训练集中没有出现过)
Summary
使用孪生网络解决 Few-shot learning

Embedding: 把图片映射成特征向量(效果比较好)
Pretraining and Fine Tuning
Cosine Similarity
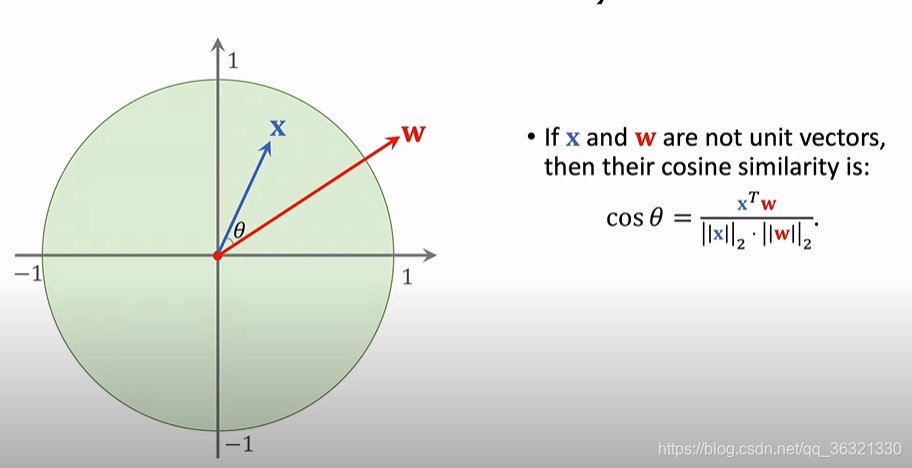
x在w上的投影
Softmax Function
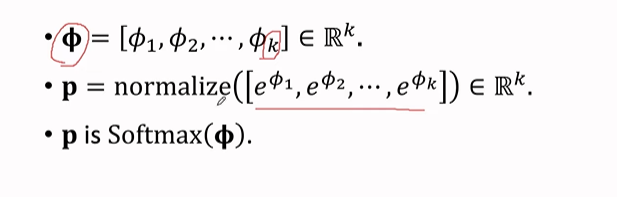
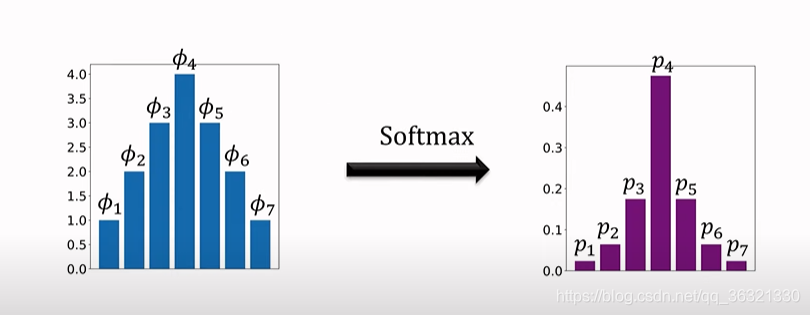
softmax会让最大的值变大,其余的值变小
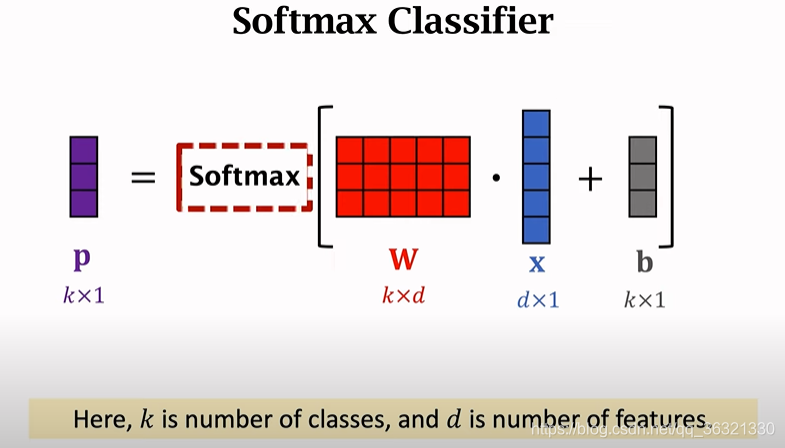
x是一个特征向量,w和b是参数
现在的训练流程:
先用一个大数据集来预训练一个神经网络,用来从图片中提取特征,做few-shot 预测的时候,使用这个预训练的神经网络。把Query和Support Set中的图片映射成特征向量,比较Query和Support Set在特征空间上的相似度,计算两两之间的相似度,选择相似度最高的,作为query的分类结果。

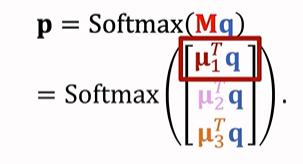
先用预训练的网络f 来提取向量,然后取均值,然后进行归一化。分类的时候,query通过预训练的网络f 来提取特征向量然后归一化成q,拿q跟 u1 u2 u3 分别做对比。
M = 【 u1,
u2,
u3
】
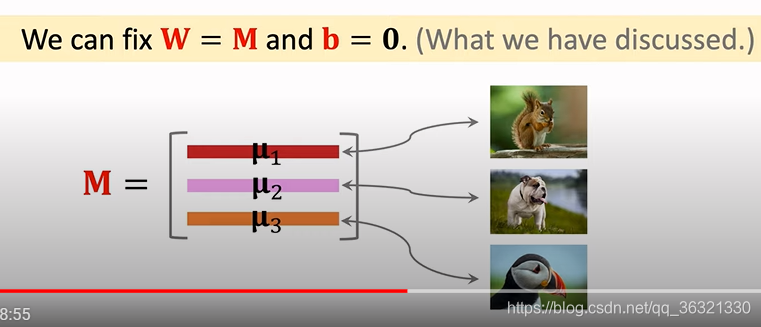
Fine-Tuning

将固定W b , W=M and b=0, 改成在Support Set上进行训练,学习W b

使用crossentropy 来衡量差别,Sum over all the samples in the support set.
由于样本很小,可以在后面加入Regularization来防止过拟合。
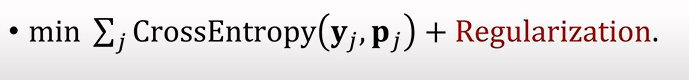

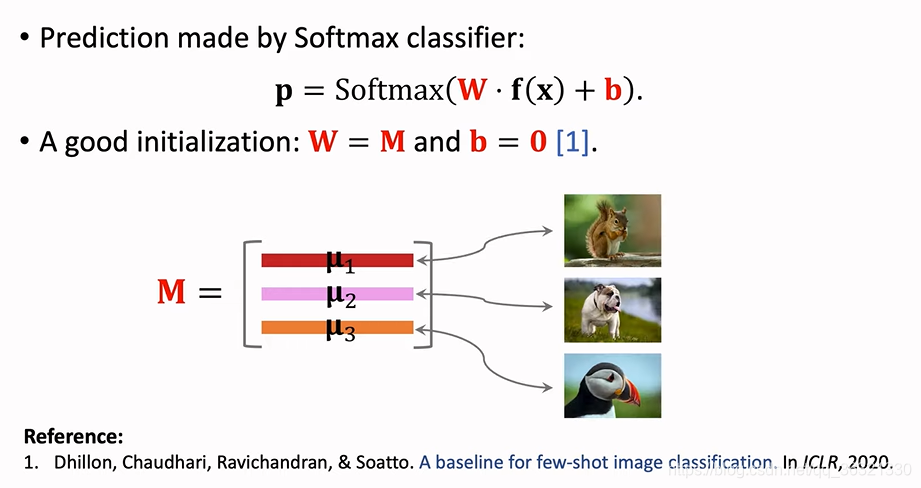
Trick 1:A good initialization
将W初始化为M,将b初始化为0,不要随机初始化。
Trick2: 使用合适的Regularization 来防止过拟合

对每一个Query求出Entropy,取平均作为Entropy regularization
我们希望Entropy regularization越小越好。

Trick2: 结合Cosine Similarity 和 Softmax Classifier

summary

