复现论文Prototypical Networks for Few-shot Learning
论文链接https://arxiv.org/abs/1703.05175v2
paperwithcode链接https://paperswithcode.com/paper/prototypical-networks-for-few-shot-learning
NeurIPS链接Advances in Neural Information Processing Systems 30 (NIPS 2017) 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA.
0.概念

- 预训练:使用基本的分类方法。卷积+FC训练完成之后将FC去掉,卷积作为encoder直接使用。预训练的测试方法与正式训练时的测试方法一致。
- 训练集&测试集:两者没有交集。
- Support set:图1中绿色部分。train和test的S无交集。
- 在构建这个episode时候,会从全量数据中每个episode都随机选择一些类别,比如C个类别,然后从数据集中同样随机从这选定的C个类别中选取同样数量的K个样本,这便构成了support set,总共包含C * K个样本。一般而言模型会在这个上面进行一次训练。这样构造出来的任务便是C-way K-shot
- Query set:图1中红色部分。train和test的Q无交集。同一行的Q和S当中,Q和S中的某些图片是一类。但是在train和test中- 的Q和S都无交集。
- 和support set类似,会在剩下的数据集样本中的C个类(注意这里的类别是从对应的spport set类别选择)采样一些样本作为query set,一般而言,模型在support set进行一次训练后,会在query set上求得loss
- task:小样本中每次是按照子任务(task)进行训练和测试的。一个task就是图1中的一行。有S有Q的
- way:一个task中的S的种类数。
- shot:如果一个task中S的种类数为n,那么n个种类中每一类有的图片数。如果一个task中S中有狗这一类,且有m张图狗的图片,那么就是m-shot。
- tqdm:进度条显示工具,很好用。
- episode:一个episode,就是一次选择support set和query set类别的过程,episode = batch_size * task
- meta trainig set: 通常而言,根据训练数据的规模大小,可以构建出来多个训练的episode,这些episode便可以称为meta-training set
- meta test set: 因为在meta training set的若干个task(也就是若干个episode)上已经训练好了一个模型,那么希望模型在一些新的task上也能有比较好的表现。因此,meta test set在数据构成上和meta training set完全一致,也包含了support set和query set,基本思想就是希望模型能够基于新任务下的support set,迅速抓住问题的本质,从而能够快速在meta test set中的query set上取得比较好的效果。
1.环境准备
首先创建虚拟环境(python>=3.7),我这选择3.10
#conda update -n base -c defaults conda
conda create -n fewshot python=3.10 pip -y
conda activate fewshot
conda安装setup.py
python setup.py build
python setup.py install
就行了,记得你的conda环境的Python版本要符合setup.py文件中的
classifiers=[
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Operating System :: OS Independent",
],
中的版本,如果还有东西没安装就直接
pip install -r dev_requirements.txt
Jupyter
要安装Jupyter内核相关包
如果直接在jupyter notebook中使用虚拟环境,要%pip install而不是!pip install
如果要在提供的jupyter notebook跑,查看日志文件,要再安装TensorBoardconda install TensorBoard
2.数据集准备
参数说明
注意,测试集、验证集以及训练集的以下参数均可以不同,尤其是WAY,验证和测试集可能没办法达到训练集这么多WAY,所以也要密切关注数据集的划分(要复现论文就要严格参考论文中描述的数据集划分)
另外,Query在测试的时候一般只影响accuracy的方差,不影响均值
N_WAY = 5 # Number of classes in a task
N_SHOT = 5 # Number of images per class in the support set
N_QUERY = 15 # Number of images per class in the query set
N_EVALUATION_TASKS = 1000
CUB
download-cub:
mkdir -p data/CUB
wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=1GDr1OkoXdhaXWGA8S3MAq3a522Tak-nx' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=1GDr1OkoXdhaXWGA8S3MAq3a522Tak-nx" -O data/CUB/images.tgz
rm -rf /tmp/cookies.txt
tar --exclude='._*' -zxvf data/CUB/images.tgz -C data/CUB/
也就是说数据集链接
https://docs.google.com/uc?export=download&id=1GDr1OkoXdhaXWGA8S3MAq3a522Tak-nx
注意划分成训练集100个类,验证集和测试集各50,因为数据集的默认划分不是这样
omniglot
miniImageNet
注意训练集64,验证集16(所以验证集的WAY不能超过16),测试集20
miniImageNet数据集链接,提取码xcu4
来源于https://lyy.mpi-inf.mpg.de/mtl/download/Lmzjm9tX.html
解压
tar -xvf file.tar //解压 tar包
参考解压缩命令
若给出的csv中存储的文件名与实际文件名不一致
那就自己导出csv吧
import os
import csv
directory = './mini_imagenet/test/' # 指定文件所在的目录
# 遍历目录下的所有文件
file_paths = []
for root, dirs, files in os.walk(directory):
for file in files:
file_path = os.path.join(root, file)
file_paths.append(file_path)
# 批量处理文件路径
data = []
for file_path in file_paths:
image_name = os.path.basename(file_path) # 提取文件名
label = os.path.dirname(file_path).split('/')[-1] # 提取标签
data.append([label, image_name])
# 导出到CSV文件
with open('test1.csv', 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
# 写入标题行
writer.writerow(['class_name', 'image_name'])
# 写入数据行
writer.writerows(data)
其他
如果感兴趣也可以访问可以访问https://blog.csdn.net/qq_36104364/article/details/107508592查看其他小样本数据集
3.运行
显卡选择
查看空闲显卡
watch -n 1 nvidia-smi
适当选择显卡,在代码最开始的地方加这一句,括号里是GPU编号
torch.cuda.set_device(1)
Omniglot
如果需要Omniglot损失函数的曲线的话,在对应位置添加
from torch.utils.tensorboard import SummaryWriter
from pathlib import Path
from statistics import mean
tb_logs_dir = Path("./trainlog/Omniglot/1Way5Shot")
average_loss = mean(all_loss)
tb_writer.add_scalar("Train/loss", average_loss, episode_index)
CUB
from easyfsl.datasets import CUB
train_set = CUB(split="train", training=True)
test_set = CUB(split="test", training=False)
miniImageNet
from easyfsl.datasets import MiniImageNet
train_set = MiniImageNet(root="where/imagenet/is", split="train", training=True)
test_set = MiniImageNet(root="where/imagenet/is", split="test", training=False)
或
make benchmark-mini-imagenet METHOD=prototypical_networks
计算置信区间
在utils.py适当位置添加.
导入和变量
import math
import numpy as np
total_predictions = 0
correct_predictions = 0
accuracies = []
循环内:
accuracies.append(correct_predictions / total_predictions)
# Compute mean accuracy
mean_accuracy = correct_predictions / total_predictions
# Compute standard deviation
std_dev = np.std(accuracies)
# Compute confidence interval
confidence_interval = 1.96 * std_dev / math.sqrt(len(accuracies))
lower_bound = mean_accuracy - confidence_interval
upper_bound = mean_accuracy + confidence_interval
print(f"Average accuracy : {
(100 * mean_accuracy):.2f} %")
print("Confidence Interval: [{:.4f}, {:.4f}]".format(lower_bound, upper_bound))
欧几里得距离改为余弦距离
论文中两个距离的实验都有,我们这里修改部分代码来复现
将
# Compute the euclidean distance from queries to prototypes
dists = torch.cdist(z_query, z_proto)
改成
# Normalize the feature vectors
z_proto_normalized = F.normalize(z_proto, dim=1)
z_query_normalized = F.normalize(z_query, dim=1)
# Compute the cosine similarity between queries and prototypes
sims = torch.mm(z_query_normalized, z_proto_normalized.t())
# Convert cosine similarity to cosine distance
dists = 1 - sims
4.分析
TensorBoard
参考TensorBoard教程
启动
tensorboard --logdir=<directory_name>
例如我就是
tensorboard --logdir=./notebooks/trainlog

如果有输出文件
就可以访问
http://localhost:6006/查看了
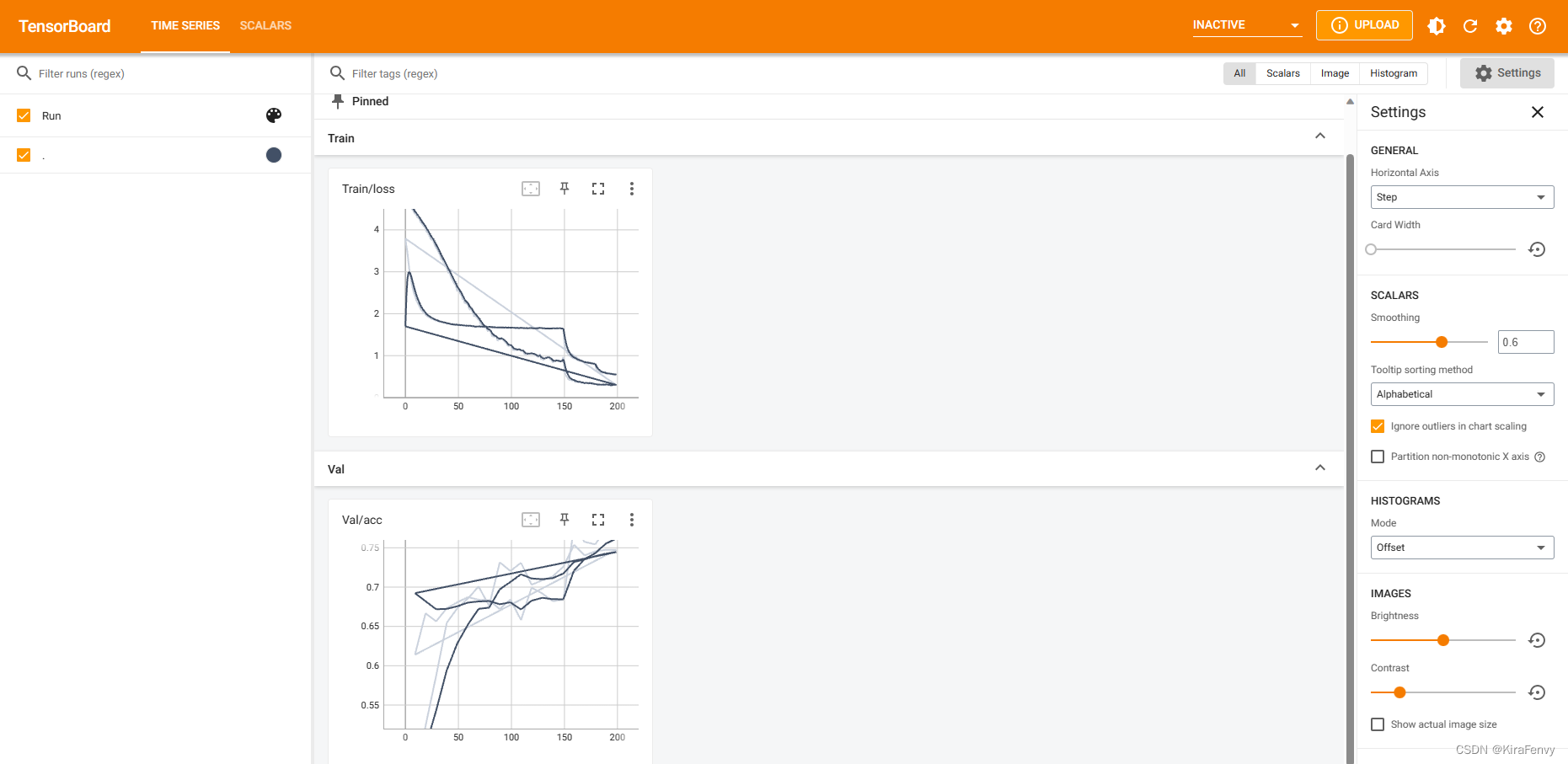
这里有很多条线,让人感到混乱,因此最好每个输出的文件单独放到一个文件夹下再进行可视化,但是可能会疑惑哪些文件是什么时候创建的,可以在linux中输入命令(参考https://blog.csdn.net/qq_31828515/article/details/62886112)
stat 文件名
会显示