Prototypical Networks for Few-shot Learning
2017 NIPS
https://papers.nips.cc/paper/6996-prototypical-networks-for-few-shot-learning
https://github.com/jakesnell/prototypical-networks

Motivation
Few-shot分类问题中,对于训练集中没有给出的新类别,分类器能够仅根据新类别的几个样本就能进行归纳。作者提出了原型网络来解决这一问题,通过计算测试样本与每一个类的原型间的距离进行分类。
Method
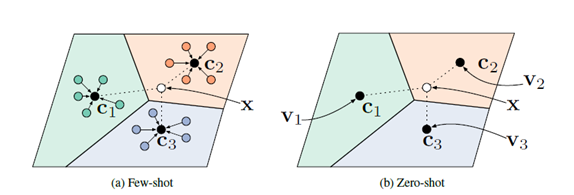
简单点来说,就是每个类中样本的embedding的均值作为该类的原型,因此就可以用原型来代表这个类,分类的准则就是测试样本的embedding和每类原型的距离比较,最近的即是他属于的类。
这一假设的依据是,存在一种embedding,能够使每类中的样本点聚类在原型周围。因此,作者使用了神经网络,得到输入到embedding空间的非线性映射, 并用每类样本的embedding的均值作为该类的原型。
训练过程的伪代码如下:
训练集中总的样本数为N,类别数为K。N_c是每个episode中的类别数,N_c <= K,N_s是每类中支撑集的样本数,N_q是每类中查询集的样本数。RANDOMSAMPLE(S,N)代表从S集中随机取N个元素。
1.先从K类中采样N_c 个类
Support set: N_c way N_s shot
Query set: N_c way N_q shot
2.计算support set的原型
3. query 中样本的embedding和support set的原型计算loss,这个loss是负的对数似然概率。

Experiment
作者在Omniglot和miniImageNet上进行了few-shot的实验。


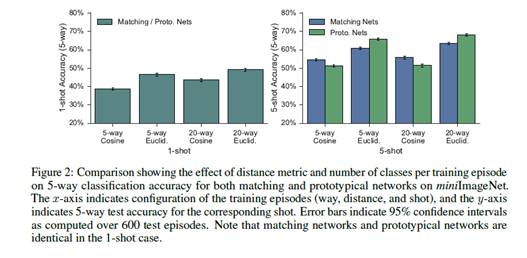
值得注意的一点是,作者提出,training shot 和test shot匹配,且在训练episode时使用更多的类,这样的做法是很有利的。因此,每个训练episode包含了60个类。关于这点,我看了Omniglot代码中,的确是用60类进行训练的。在miniImageNet,1-shot是30-way episodes,5-shot是20-way episodes。
此外,距离度量函数的选择也很重要。使用欧式距离而不是余弦距离能够提升Proto. Net的准确率,20-way比5-way的准确率高。
Related Work
Matching Networks,区别:matching net使用的是一个加权最近邻分类器,而proto. Net是一个用欧氏距离的线性分类器。
Thoughts
Proto. net里估计的原型和真实原型的偏差。