
笔记整理:许方舟,天津大学硕士
链接:https://link.springer.com/article/10.1007/s11704-022-1339-7
动机
现如今在元学习框架下诞生了许多小样本学习方法,他们能够从多种任务中学习并泛化到新任务中。如果所有样本都来自相同分布,这种情况下小样本学习能够达到预期的性能。然而在实际应用中,小样本学习范式往往会受到数据偏移的影响,即不同任务中的样本,甚至同一任务中的样本,都可能来自不同的数据分布。大多数现有的小样本学习方法没有考虑数据偏移,因此当数据分布偏移时性能不佳。针对这一问题,本文提出了一种新颖的元学习框架,借助知识图谱来提取任务特定的表示和任务共享的表示。因此,任务内/任务间的数据迁移可以通过任务共享和任务特定表示的组合来解决。
亮点
(1)研究了数据迁移下的小样本学习,而现有的模型主要研究不考虑数据迁移的小样本学习;
(2)提出了一种有效的方法来利用知识图谱来指导任务共享表示的学习,并将其与任务特定的表示相结合,在小样本学习中生成合适的类别原型;
(3)构建了两个数据集,相比于现有流行基准有着更加明显的数据偏移,并通过实验证明本文GPN模型的有效性。
概念及模型
问题确立:
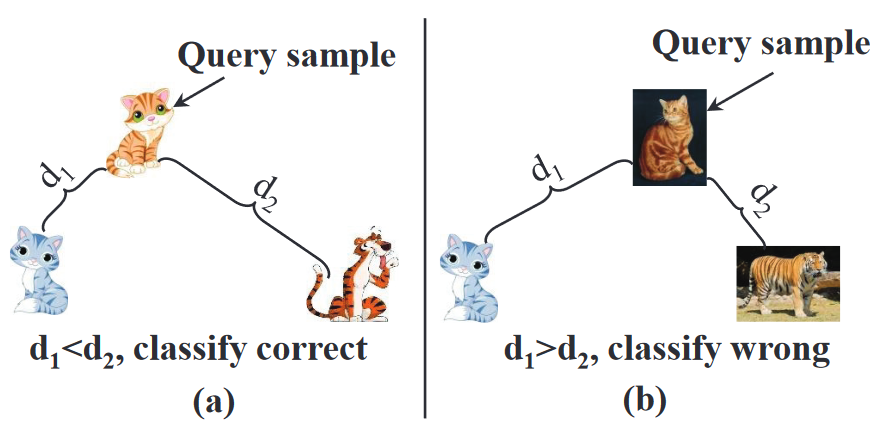
现有的小样本学习方法假设训练集和测试集中的所有样本来自相同的分布,但在现实应用场景中往往不符合这一情况,如下图所示,样本有时来自不同的分布,导致真实世界的猫被错误分类为老虎。本文假设训练集和测试集中的样本来自不相同的分布。
任务特异性表征:
对于每个任务,一个原型 被定义为来自同一个类n的支持样本嵌入的均值向量,原型 的质量因任务而异,其中包含任务的特异性信息,下文中将利用 表示不同抽取任务的特定原型:
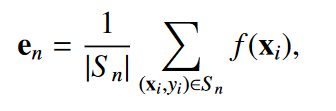
任务间共享表征:
为了解决任务内和任务间的数据偏移,本文提出两个关键思想:学习一个稳定的任务共享表征,并对不同类别进行桥接。其中知识图谱中所包含的信息能够让我们捕获到稳定的语义类别信息,并能够链接所有类别的语义关系。虽然样本来自不同分布,但他们通常共享相同的知识,因此知识图谱可以驱动稳定的任务共享表征的学习,弥补学习任务和测试任务中类别之间的鸿沟。本文的目的将训练集中学到的知识能够迁移到小样本中,并学习到其中的类别知识,其中二者之间的链接通过后备知识完成。具体来说,知识图谱和类别的关系通过一个包含自环形式的对称邻接矩阵 完成。
GPN模型结构:
面向数据偏移问题下小样本分类的GPN框架由CNN (以图像作为输入)和GCN (以词向量作为输入)组成,模型整体结构如下所示:
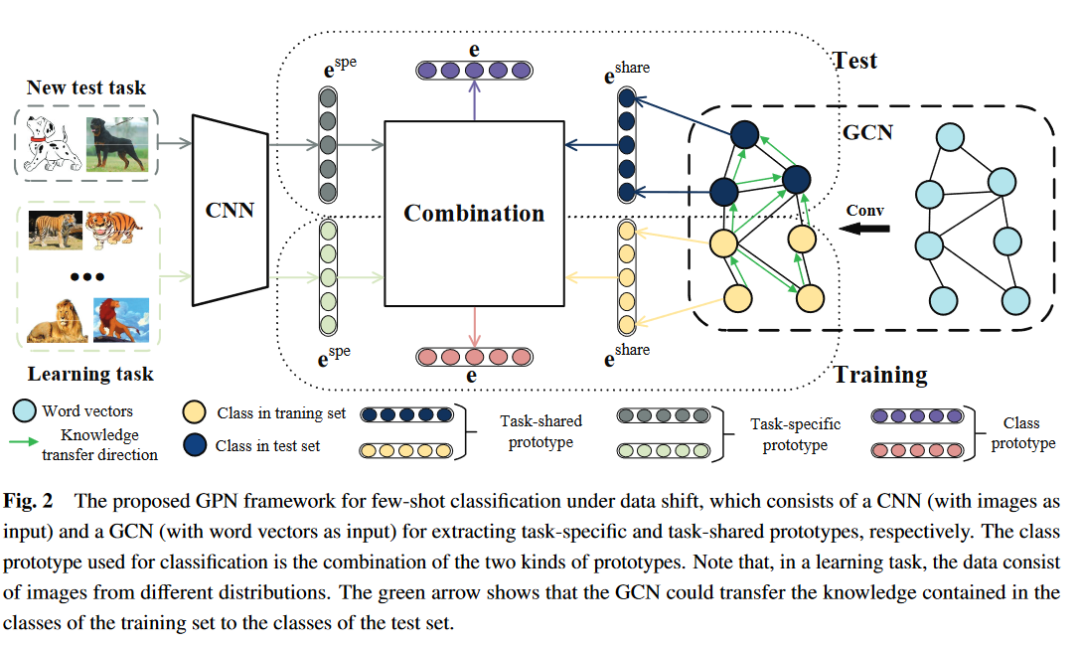
CNN:抽取任务特定的原型 ,尤其是会受到支持集质量影响的原型
GCN:输入词嵌入信息与知识图谱,抽取任务共享原型 。
Combination:利用CNN和GCN抽取的原型进行合并,生成每个类的稳定的原型 ,公式如下所示:
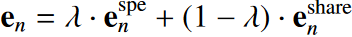
对于一个查询实例x,GPN基于CNN抽取的f(x)和嵌入空间中的原型 之间距离进行softmax进行类别的预测:
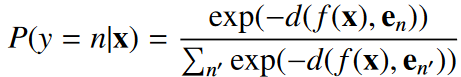
其中d代表欧氏距离,损失函数定义为“查询集”上的交叉熵损失:
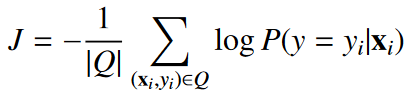
理论分析
实验
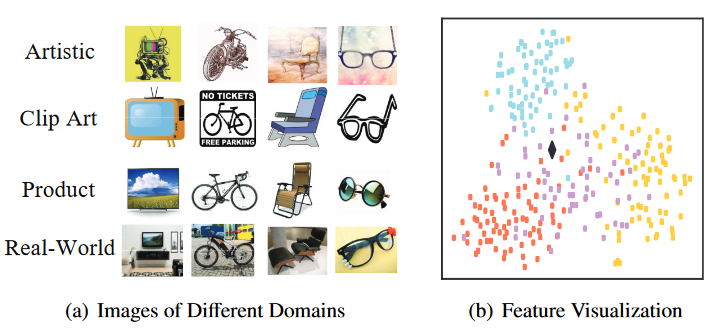
作者采用了四个数据集进行实验,分别为miniImageNet数据集、Office-Home数据集以及作者自行构建的Easy-Office-Home和Hard-Office-Home数据集。其中Easy-Office-Home和Hard-Office-Home数据集是Office-Home数据集的子集,Office - Home中共有四个域(每个域中样本为不同风格的图片)以及65个类别。数据样例如下图所示,每个类别拥有四种图片类型:

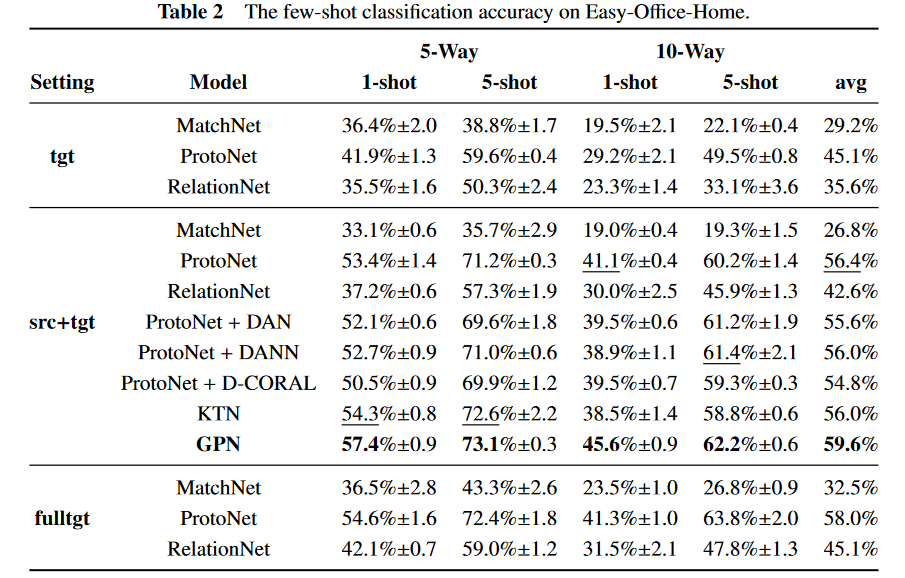
两个数据集的构建如下:首先,将65个类随机分成3部分,其中38个用于训练,12个用于验证,其余15个用于测试。然后,选择四个域中其中一个域作为目标域,其他三个域作为辅助域。所有设置的验证集和测试集分别使用来自目标域的12个验证类和15个测试类的图像。为了进一步研究数据偏移产生的影响,作者提出了三种数据集设定:
( 1 ) tgt:仅使用目标域中属于12个训练类的样本进行训练;
( 2 ) src + tgt:使用全部辅助域样本(来自38个训练类别)和目标域样本(来自12个训练类别);
( 3 ) fulltgt:使用目标域中38个训练样本的全部样本。
其中tgt和fulltgt设置下的所有样本来自同一个域(分布),可视为不存在数据偏移。此外,在src + tgt设置下,学习任务的样本可能来自四个域,导致任务内数据偏移。
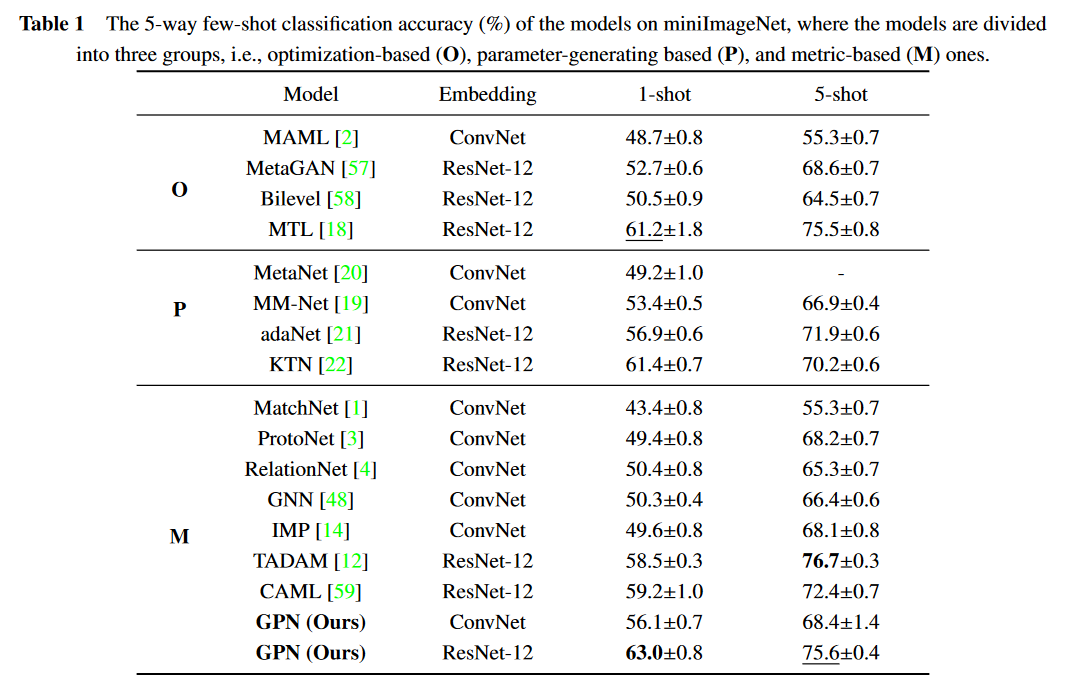
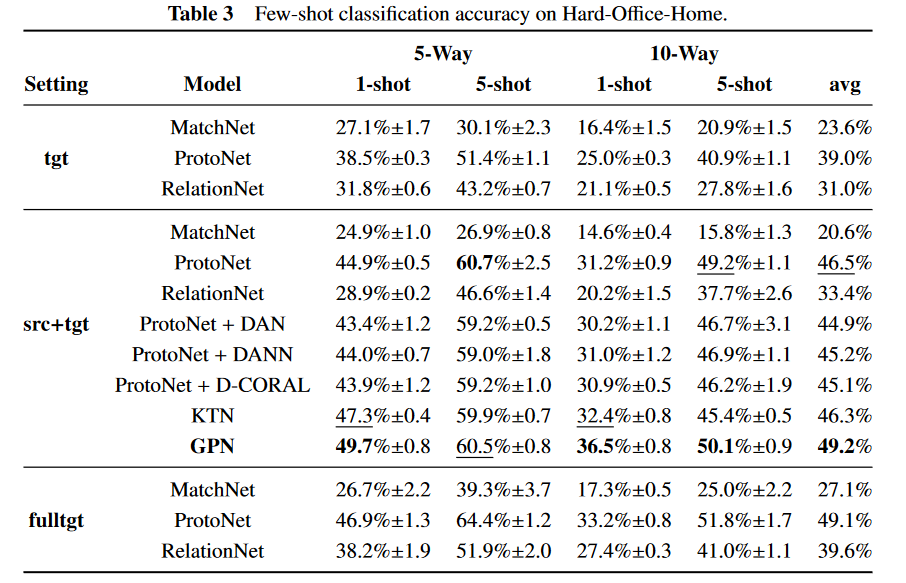
mini Image Net、Easy - Office - Home和Hard - Office - Home的结果分别如表1、表2和表3所示。首先,GPN在流行的基准mini Image Net上可以取得显著的效果。在src + tgt设置下,GPN几乎在所有任务上都优于所有对比模型。特别地,在构建的两个数据集上,GPN在最佳基线上大幅提高了平均准确率(约3 % )。现有的结果证明了所提出的GPN在数据偏移问题下处理这种小样本的有效性。由于小样本的特点,传统的小样本学习方法更容易受到样本质量的影响。在这种情况下,利用额外的任务共享信息可以极大地帮助任务特异性表征实现稳定性和可靠性。
其中,KTN 和本文的GPN都是利用知识图谱进行小样本学习,并且GPN在大多数任务上都优于KTN,验证了GPN比KTN更有效。主要原因是KTN使用KG和GCN作为无监督方法,并不适合小样本学习。相反,本文的GPN使用了基于小样本框架的KG和GCN,更适合小样本学习。
作者通过消融实验验证了GPN各部分的有效性。其中表明GCN可以借助知识图谱将更多的知识从训练类别迁移到测试类别。如下图所示,作者还可视化了同一类别样本在不同任务上学习到的表示,用不同颜色加以区分,其中黑点代表GCN学习到的任务共享原型。该图也证实了数据偏移的存在,此外共享原型位于所有点的中心位置,证实了所提出的GPN能够学习到任务特定的和任务共享的表示。
总结
对于小样本学习,现有方法大多关注如何有效利用有限的标记样本,而忽略了数据漂移问题。在实际应用中,数据偏移问题广泛存在于流行的小样本基准测试中,并对现有方法有着负面的影响。本文分析了表现为任务内和任务间数据迁移的问题,本文提出GPN模型,该模型利用知识图谱同时学习和考虑任务共享和任务特定的表示,然后产生一个更稳定的表示。最后,大量的实验证明了一些传统的小样本方法的不足,以及所提出的GPN在数据迁移场景中的有效性。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。