一、算法分类
1.有监督学习:输入数据有人为的标签来指导学习,不断地改进模型参数。用于分类预测问题。
2.无监督学习:黑盒训练模式,没有任何指导,分析结果不可控。用于聚类和特征关联。
3.半监督学习:用于有数据缺失的情况,算法运算于有/无监督之间。
二、回归算法
1.线性回归:其表达形式为y = w'x+e,e为误差服从均值为0的正态分布。用于预测一个连续的值。
回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
*要点:
(1)Cost损失函数:描述h函数不好的程度(前面乘上的1/2是为了在求导的时候,这个系数就不见了。)
(2) Goal:如何调整θ以使得J(θ)取得最小值有很多方法,其中有最小二乘法和梯度下降法。
*梯度下降:有可能是全局极小值,这与初始点的选取有关,收敛较慢。
1)首先对θ赋值,这个值可以是随机的,也可以让θ是一个全零的向量。
2)改变θ的值,使得J(θ)按梯度下降的方向进行减少。
梯度方向由J(θ)对θ的偏导数=0确定,由于求的是极小值,因此梯度方向是偏导数的反方向。结果为
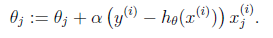
迭代更新的方式有单样本的随机梯度下降、minibatch的批梯度下降,全部样本的梯度下降。
*最小二乘法:将训练特征表示为X矩阵,结果表示成y向量,仍然是线性回归模型,误差函数不变。那么θ可以直接由下面公式得出
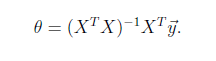
*优缺点:建模速度快,不需要很复杂的计算、每个特征对结果的影响强弱可以由前面的参数体现(而且每个特征变量可以首先映射到一个函数,然后再参与线性计算,这样就可以表达特征与结果之间的非线性关系)、对异常值噪声很敏感(一般不用来分类,而是求连续值)。
2.逻辑logistic回归:不是回归,而是分类器,二分类,多分类。
logistic回归本质上是线性回归,只是在特征到结果的映射中加入了一层函数映射,即先把特征线性求和,然后使用函数g(z)来预测。g(z)可以将连续值映射到0和1上。
*形式:logistic回归的假设函数如下,线性回归假设函数是![]() 。
。
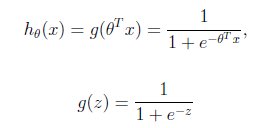
logistic回归用来分类0/1问题,这里假设了二值满足伯努利分布,也就是