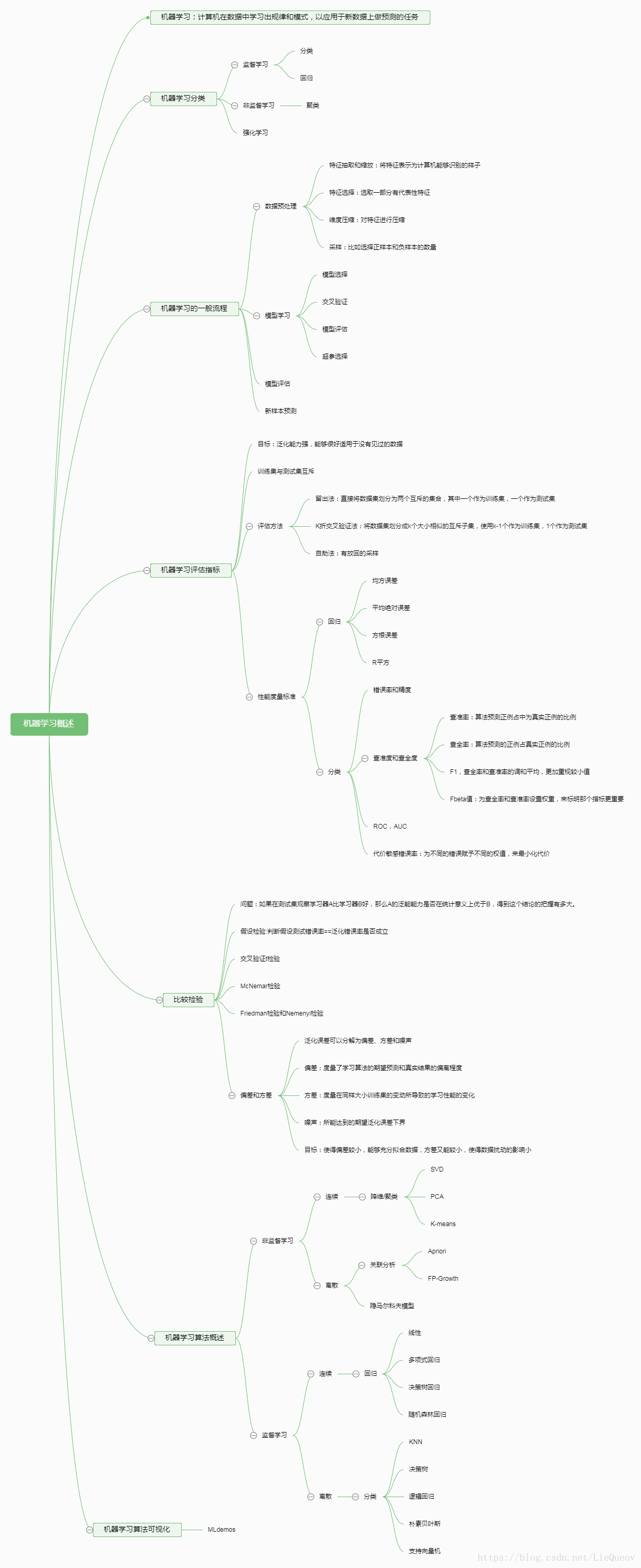
一、思维导图

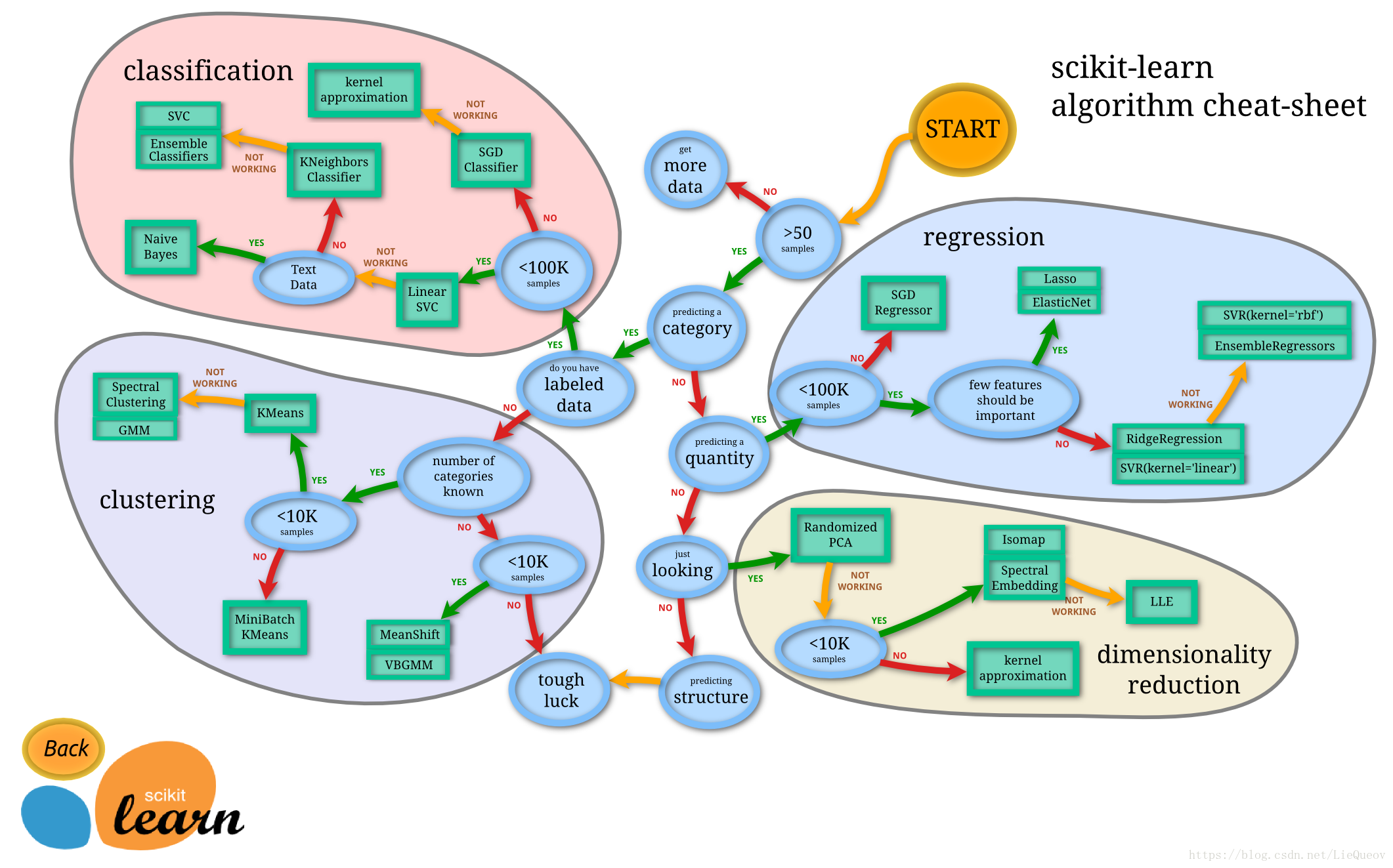
二、sk-learn小抄
图片来源:http://scikit-learn.org/stable/tutorial/machine_learning_map/
三、算法笔记
1. 留出法
将数据集D划分为两个互斥的集合,其中一个集合作为训练集S,另一个作为测试集T,在S中训练模型,在T上测试模型。
注意点:
(1)训练集/测试集要尽量保持数据分布的一致性。例如在一些对性别敏感的应用中,训练集中的男性与女性的比例要保持和测试集中男性与女性的比例一致。
(2)留出法的划分不唯一,通常采用多次随机划分后取均值的方法进行评估。
(3)测试集大小适中,S太大,T太小,那么评估的准确性不稳定。S太小,T太大,学习的量少,降低了评估的保真性。
2. K折交叉验证法
将数据集D划分为k个大小相似的互斥子集,每个子集要保持数据分布的一致性。然后将k-1个子集的并集作为训练集,余下的一个子集作为测试集,这样就可以获得k组训练/测试集。
注意点:
(1)与留出法一样,对于数据的划分方式不唯一,k折交叉验证可以随机使用不同的数据划分重复p次。最终的结果为p次k折划分交叉验证结果的均值。
(2)如果D中有m个样本,若m=k,则划分方式唯一,称为留一法。优点是相对准确,缺点是训练m个模型的计算开销太大。
3. 自助法
每次随机从数据集D中选择一个样本放到D’中,然后将这个样本再放回D中(有放回的采样)。重复这个过程,选择m个样本。然后D’作为训练集,D-D’作为测试集。
注意点:
(1) 优点:在小样本的情况下好用,对于集成学习有很大的帮助。
(2) 缺点:改变了数据的分布,引入了估计偏差。数据量足够的时候,一般不采用。
4.凸函数
对实数集上的函数,可以通过二阶导数来判别:若二阶导数在区间上非负,则称为凸函数;若二阶导数在区间上恒大于0,则为严格的凸函数。