整理思路
- 获取所有职位信息的url
- 通过正则去掉不符合要求的url
- 爬取详情页信息
- 解析详情页
- 写入txt文件
- 循环抓取
- 提高速度多线程爬取
先放上url:https://search.51job.com/list/000000,000000,0000,00,9,99,+,2,1.html
url的最后“1.html”中的1是指第一页第二页就是2.html以此类推我们可以使用一个变量替代实现循环抓取
分析网页结构:

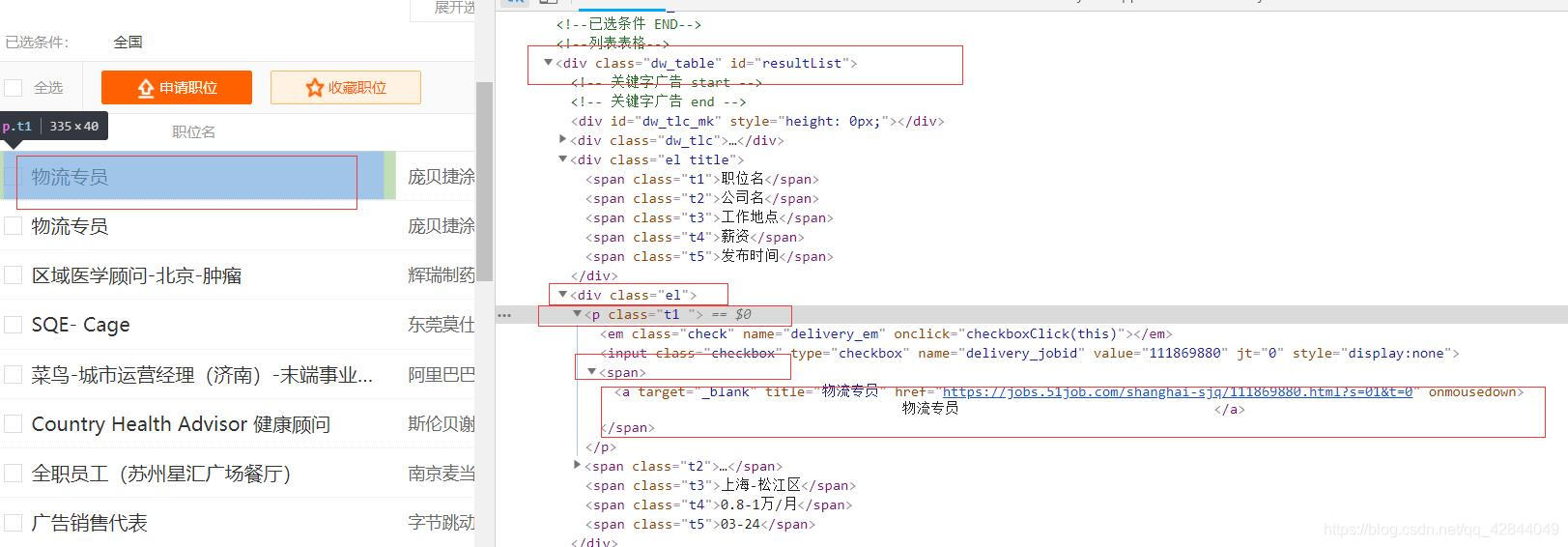
提取详情页url:
使用谷歌F12后审查元素我们发现所有的url都包含在p标签的span标签中
我们先选中所有的p标签然后再提取出里面的span和a标签
url_items = soup.select('#resultList .el .t1')
我们打印一下提取出来的p标签
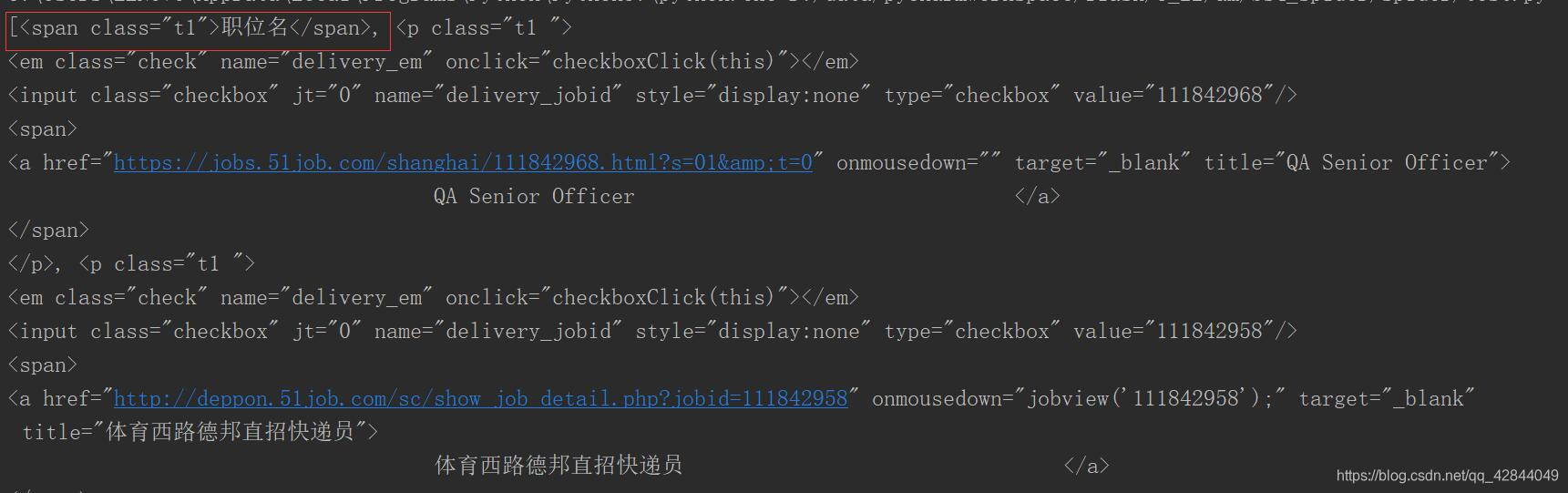
我们发现多了一条没用的信息没关系我们删掉他
url_items = soup.select('#resultList .el .t1')
url_items.pop(0)
接下来我们提取所有span标签中的a标签的href属性
for url_item in url_items:
all_a = url_item.find('span').find('a')
print(all_a['href'])
通过打印a标签的href属性我们又发现了一个新问题
并不是所有的url都是可以抓取的
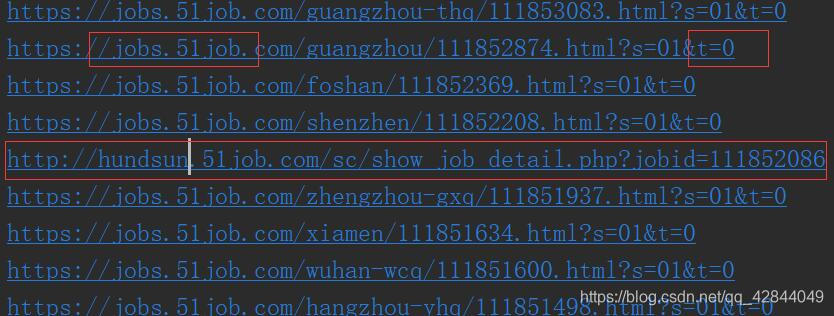
通过观察我们会发现能够抓取的url都是以http或https开头然后是jobs.51job.com最后以t=0结尾
我们通过正则过滤掉无效的url
pattern = re.compile(r'.*?://jobs.*?t=0')
这样我们抓取的详情页url就都符合规范了
抓取详情页
套路和抓取详情页url一样我就不过多赘述了
解析详情页
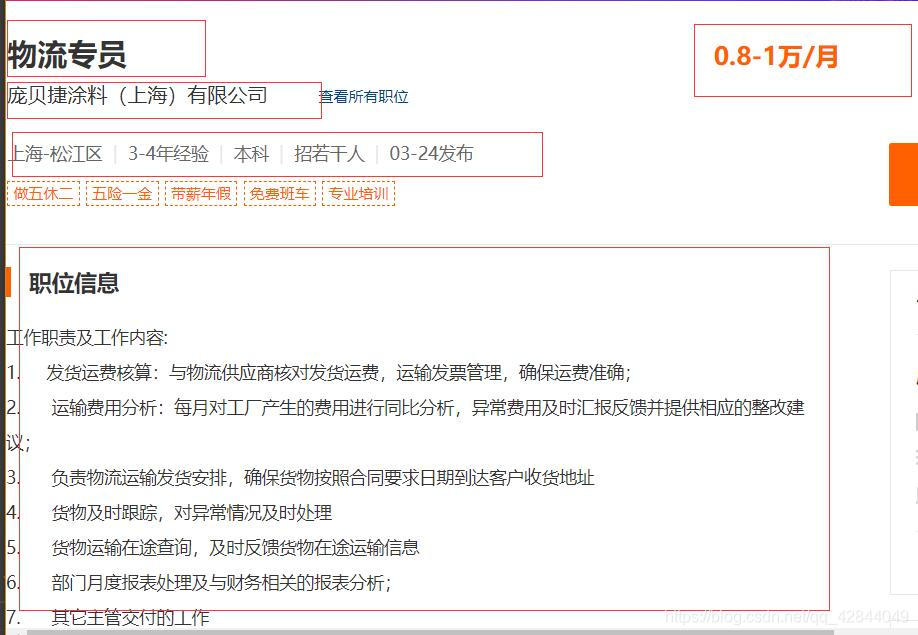
我们所需要的信息:职位名称、公司、地点、薪资、经验要求、学历要求、人数、时间和职位信息
我们通过bs4的css选择器依次提取,不熟悉bs4的小伙伴可以去看一下官方文档很简单的bs4中文文档
我直接上代码了
其中:地点、经验、学历、职位信息等很不规范,有的网页有,有的网页没有所以我们无法规范的抓取所以对于地点等标签我们全部抓取然后加在一个列表里。对于职位信息我们定位到包含职位信息的div通过正则提取出所有中文,有能力的小伙伴可以爬一下智联那个比较规范不过智联反爬比较厉害能爬的信息也比较少只有12页数据都是通过ajax动态加载的
regx = re.compile(r'[\u4e00-\u9fa5]+')
soup = BeautifulSoup(html,'lxml')
job = soup.select('.tHeader.tHjob .in .cn h1')[0]['title']
salary = soup.select('.tHeader.tHjob .in .cn strong')[0].text
company = soup.select('.tHeader.tHjob .in .cn .cname .catn')[0]['title']
info = soup.select('.tHeader.tHjob .in .cn .msg.ltype')[0]['title'].replace('\xa0\xa0','')
info_list = info.split('|')
job_info_item = soup.select('.bmsg.job_msg.inbox')[0].text
regx = re.compile(r'[\u4e00-\u9fa5]+')
job_info = ''.join(re.findall(regx,job_info_item))
写入txt文件
def write_to_file(data):
with open('result.txt','a+',encoding='utf-8') as f:
datas = json.dumps(data,ensure_ascii=False)
f.write(datas+'\n')
f.close()
循环抓取
for i in range(1,2001):
url = 'https://search.51job.com/list/000000,000000,0000,00,9,99,%2B,2,'+str(i)+'.html?'
看一下效果:

多线程
from multiprocessing import Pool
pool = Pool
pool.map(main,[i for i in range(1,2001)])
ps:如果不是对速度有要求不要使用多线程我们也要考虑服务器的压力尽量使用time.sleep()控制自己的爬取速度如果速度过快很多网站都是会封ip的提高速度的话也可以使用scrapy爬取
最后放上完整代码供大家交流
# 作者: LENOVO
# 时间: 2019/3/22 8:50
import json
from multiprocessing import Pool
import requests
from bs4 import BeautifulSoup
import re
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'}
def get_all_url(url):
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
response.encoding = response.apparent_encoding
return response.text
return None
except ConnectionError:
return None
def parse_url(html):
soup = BeautifulSoup(html, 'lxml')
url_items = soup.select('#resultList .el .t1')
url_items.pop(0)
for url_item in url_items:
all_a = url_item.find('span').find('a')
yield all_a['href']
def deal_with_url(href_list):
pattern = re.compile(r'.*?://jobs.*?t=0')
urls = []
for href in href_list:
url_list = re.findall(pattern, href)
if len(url_list) != 0:
urls.append(url_list[0])
return urls
def get_detail_html(url):
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
response.encoding = response.apparent_encoding
return response.text
return None
except ConnectionError:
return None
def parse_detail(html):
soup = BeautifulSoup(html, 'lxml')
job = soup.select('.tHeader.tHjob .in .cn h1')[0]['title']
salary = soup.select('.tHeader.tHjob .in .cn strong')[0].text
company = soup.select('.tHeader.tHjob .in .cn .cname .catn')[0]['title']
info = soup.select('.tHeader.tHjob .in .cn .msg.ltype')[0]['title'].replace('\xa0\xa0', '')
info_list = info.split('|')
# location = info_list[0]
# exp = info_list[1]
# amount = info_list[2]
# date = info_list[3]
job_info_item = soup.select('.bmsg.job_msg.inbox')[0].text
regx = re.compile(r'[\u4e00-\u9fa5]+')
job_info = ''.join(re.findall(regx, job_info_item))
yield {
'job': job,
'salary': salary,
'company': company,
'info_list': info_list,
# 'location':location,
# 'exp':exp,
# 'amount':amount,
# 'date':date,
'job_info': job_info
}
def write_to_file(data):
with open('result.txt', 'a+', encoding='utf-8') as f:
datas = json.dumps(data, ensure_ascii=False)
f.write(datas + '\n')
f.close()
def main(offset):
print('正在抓取', offset)
url = 'https://search.51job.com/list/000000,000000,0000,00,9,99,%2B,2,' + str(offset) + '.html?'
url_html = get_all_url(url)
if url_html:
href_list = parse_url(url_html)
urls = deal_with_url(href_list)
for url1 in urls:
detail_html = get_detail_html(url1)
if detail_html:
details = parse_detail(detail_html)
for detail in details:
# print(detail)
write_to_file(detail)
if __name__ == '__main__':
# for i in range(1,2001):
# main(i)
pool = Pool()
pool.map(main, [i for i in range(1, 2001)])