数据的获取是数据挖掘的第一步,如果没有数据何谈数据挖掘?有时候在做算法测试的时候,一个好的数据集也是算法实验成功的前提保障。当然我们可以去网上下载大型数据网站整理好的,专业的数据,但是自己动手爬取数据是不是更惬意呢?
说到这里,给大家推荐一些常用的大型数据集:
(1)、MovieLens
MovieLens数据集中,用户对自己看过的电影进行评分,分值为1~5。MovieLens包括两个不同大小的库,适用于不同规模的算法.小规模的库是943个独立用户对1682部电影作的10000次评分的数据;大规模的库是6040个独立用户对3900部电影作的大约100万次评分。
(2)、EachMovie
HP/Compaq的DEC研究中心曾经在网上架设EachMovie电影推荐系统对公众开放.之后,这个推荐系统关闭了一段时间,其数据作为研究用途对外公布,MovieLens的部分数据就是来自于这个数据集的.这个数据集有72916个用户对l628部电影进行的2811983次评分。早期大量的协同过滤的研究工作都 是基于这个数据集的。2004年HP重新开放EachMovie,这个数据集就不提供公开下载了。
(3)、BookCrossing
这个数据集是网上的Book-Crossing图书社区的278858个用户对271379本书进行的评分,包括显式和隐式的评分。这些用户的年龄等人口统计学属性(demographic feature)都以匿名的形式保存并供分析。这个数据集是由Cai-Nicolas Ziegler使用爬虫程序在2004年从Book-Crossing图书社区上采集的。
(4)、Jester Joke
Jester Joke是一个网上推荐和分享笑话的网站。这个数据集有73496个用户对100个笑话作的410万次评分。评分范围是-10~10的连续实数。这些数据是由加州大学伯克利分校的Ken Goldberg公布的。
(5)、Netflix
这个数据集来自于电影租赁网址Netflix的数据库。Netflix于2005年底公布此数据集并设立百万美元的奖金(netflix prize),征集能够使其推荐系统性能上升10%的推荐算法和架构。这个数据集包含了480189个匿名用户对大约17770部电影作的大约lO亿次评分。
(6)、Usenet Newsgroups
这个数据集包括20个新闻组的用户浏览数据。最新的应用是在KDD2007上的论文。新闻组的内容和讨论的话题包括计算机技术、摩托车、篮球、政治等。用户们对这些话题进行评价和反馈。
(7)、UCI知识库
UCI知识库是Blake等人在1998年开放的一个用于机器学习和评测的数据库,其中存储大量用于模型训练的标注样本。
其他数据集:
(8)、http://snap.stanford.edu/na09/resources.html
(9)、http://archive.ics.uci.edu/ml/
(10)、http://www.ituring.com.cn/article/details/1188
闲来无事,用R语言爬取了一下前程无忧网上的招聘职位数据,要找工作的司机们可以借鉴一下最近到底有哪些热门职位呢?
这是我保存的本地职位文件:
http://mmbiz.qpic.cn/mmbiz_png/pKsJz0Y4P7rdcoMicAv2h1bZpwQJ7V0Hicic3aQWIXC3ItTHhIrKJE97ZON83SrGY8DxAAAST6giaYum2kygxN18Lg/640?wx_fmt=png&tp=webp&wxfrom=5&wx_lazy=1
好像还是不错的哦!当然了,网络爬虫要懂一些网页的基本知识,一些简单的网页元素、标签要懂,最好会做一些简单的网页。这里用到的R包主要是”rvest”,没有的话可以安装一下,很简单只需要运行以下命令:
install.packages(“rvest”)
创建一个本地文件夹保存抓取的数据:
filename<-"E:\\工作簿2.csv" #如果不存在这个文件,会自动创建新文件
这是我抓取主页面的网址,有点长,没办法:
url_<-"http://search.51job.com/jobsearch/search_result.php?fromJs=1&jobarea=010000%2C00&district=000000&funtype=0000&industrytype=32&issuedate=9&providesalary=99&keyword=测试工程师&keywordtype=2&curr_page=1&lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&list_type=0&fromType=14&dibiaoid=0&confirmdate=9"打开主页面如下图;
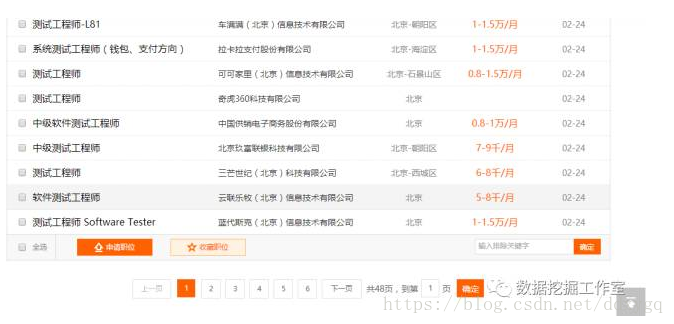
可以看出一共有48个页面,爬取玩当前页面后需要跳转到下一个网页,然后继续爬取,那么怎么获取下一页网址呢?像这种大型网站,再简单也是有点小复杂的。思考了好久,我决定从下一页下手,不管当前处于哪一页(比如第二页),点击下一页直接跳转(第三页),这样就避免了获取下一页网址的困难。
link<-web%>%html_nodes(‘div.p_in li.bk a’)%>%html_attr(“href”)
获取下一页网址
根据“div.p_in li.bk a”获取链接link里面会有两个链接,也就是说length(link)=2。当然我也不知道什么原因,毕竟这个大型网站还是比较复杂的,但是,我发现,当处于第一页时,link[1]就是第二页的网址,当不处于第一页时link[2]即为下一页网址,于是有:
for(i in 1:48){
if(i==1){
web<-read_html(url_,encoding = "GBK") #注意网页编码为'GBK',不是常用的'utf-8',可以右击编码(E)
title<-html_text(html_nodes(web,'p.t1 a')) #职位名根据网页结构剖析,下同
location<-html_text(html_nodes(web,'span.t3')) #工作地域
location<-location[2:length(location)]
salary<-html_text(html_nodes(web,'span.t4'))
salary<-salary[2:length(salary)]
Time<-html_text(html_nodes(web,'span.t5'))
Time<-Time[2:length(Time)]
这里发现除了title(职位名)外,其它长度多了一个【地域】、【薪水】、【时间】,取2~length()长度
url_<-link[1]
Data<-data.frame(title,location,salary,Time) #拼接成数据框
}
else{ #不是第一页时,前面解释过
web<-read_html(url_,encoding = "GBK")
title<-html_text(html_nodes(web,'p.t1 a'))
web<-read_html(url_,encoding = "GBK")
title<-html_text(html_nodes(web,'p.t1 a'))
location<-html_text(html_nodes(web,'span.t3'))
location<-location[2:length(location)]
salary<-html_text(html_nodes(web,'span.t4'))
salary<-salary[2:length(salary)]
Time<-html_text(html_nodes(web,'span.t5'))
Time<-Time[2:length(Time)]
link<-web%%html_nodes('div.p_in li.bk a')%%html_attr("href")
# 从当前页面获取下一页网址,审查元素【下一页】那个按钮
url_<-link[2] #前面解释过
Data<-rbind(Data,data.frame(title,location,salary,Time)) #每次循环都拼接数据框Data,直到把48个页面所有数据拼接在一个数据框里
}
}
################将数据框以csv格式写入本地文件##################
write.csv(Data,file = filename,row.names = FALSE)上面的Data<-rbind(Data,data.frame(title,location,salary,Time)) 是按行拼接,它还有个兄弟cbind()。分别是列数相同按行拼接,行数相同按列拼接。以上代码亲测好用,直接拿来用的哦。