目录
(4)partial_link_text定位(部分超链接定位)

三、利用selenium和beautifulsoup爬取网页实例
爬虫的方法有很多,但是我认为最牛逼的还是selenium。
那么,selenium到底是什么呢?它为什么叫自动化呢?那是因为它能模拟人为操作浏览器,而且也不需要requests解析网页,他自己就可以解析。下面废话少说,直接开肝!
一、安装浏览器驱动器
selenium为什么要安装驱动器呢?因为就相当于汽车的引擎,如果没有,就不能驱动。
驱动器有两种,一个是谷歌的,还有一个是火狐的。我是安装的谷歌的,只需要找到与浏览器对应的驱动器下载就行。
1. 下载驱动器
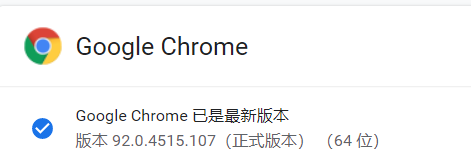
这里就可以看到了自己的版本号,接下来就是下载驱动器的版本了 点击进入下载驱动器。

找到了自己对应的版本,如果没有找到你对应版本号,可以先去更新浏览器,如果还是没有就下载和自己版本相近的就行。最后点击进入。

可以看到这里可以看到有4个压缩包,第一个是虚拟机的,第二个和第三个是苹果系统的,最后一个windows的,如果电脑配置是win64,下载win32也行。
下载之后,将压缩包解压,得到chromedriver.exe。
安装驱动器不仅仅用在selenium上还能再pyecharts上(绘图工具,非常全能),所以建议大家还是把驱动器装上。
2. 启动驱动器
1. 就要带上驱动器的路径,例如我的驱动器 chromedriver.exe 位置在:C:\Users\86178\Desktop\重庆科技学院\爬虫\谷歌驱动器\chromedriver.exe。
driver = webdriver.Chrome(r'C:\Users\86178\Desktop\重庆科技学院\爬虫\谷歌驱动器\chromedriver.exe')
2. 当然你也可以不用带上路径,直接将chromedriver.exe放在所在的包下面,启动时就可以不用带上路径,建议使用,如下:
driver = webdriver.Chrome()
如果不能启动驱动器就会出现,一下这种情况,
![]()
出现以上这种情况原因:1. 驱动器版本下载错误,这时候就要重新下载驱动器版本。
2. 启动时路径出错。
二 、selenium的使用
先说这里需要引入的库
from selenium import webdriver # 调用浏览器驱动器
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
import pandas as pd
import time当开始学习selenium时,感觉非常难。但是实际上并没有那么难。下面就跟着我一起学习selenium吧!
我本来想用前程无忧上面举例,但是这个网站上面没有合适的例子,我就用大家百度来举例,方便又快捷,简单又易懂。
1. 启动驱动器加载网页
以下代码,可以直接启动驱动器和加载到网站。
注意:如果你的chromedriver.exe不是和运行的文件在一个包下,就必须要添加chromedriver.exe 的位置,如上一点启动驱动器那里讲的。
driver = webdriver.Chrome() # 启动驱动器
driver.get('https://www.baidu.com') # 加载的网页2. 八大元素定位
selenium最重要的就是元素定位。有name,id,link_text,partial_link_text,class_name,xpath,css,tag_name
(1)id 定位
根据标签下面的属性为id来定位。例如搜索框的值为id = ‘kw’ 来定位。

搜索框部分的HTML:
-<input id="kw" name="wd" class="s_ipt" value maxlength="255" autocomplete="off">
# driver.find_element_by_id('kw').send_keys('奥运会') # 不建议使用,不利于封装,知道就行
driver.find_element(By.ID,'kw').send_keys('奥运会') # 注意大写
driver.find_element(By.ID,'su').click() # 点击‘百度一下’
这里用id定位的方法有两种,结果都是一样的,我使用的是第二种,第一种不推荐使用,因为在定义类中不利于封装。
这里的意识是根据id定位到搜索框,然后在搜索框中输入”奥运会“搜索,再点击‘百度一下’
得到的结果如图,

这里暂停一下,我们看到了send_keys()和click() 这是键盘事件和鼠标事件。

还有很多的这种类似的操作,如果有需要,可以去搜索,这里主要讲元素定位。
(2)name定位
和id一样,找到属性name,并且还有他的值。
driver.find_element(By.NAME,'wd').send_keys('杨倩')
driver.find_element(By.ID,'su').click()(3)link_text定位(超链接定位)
定位带有href超链接的元素,但是它的元素值并不是超链接。
driver.find_element(By.LINK_TEXT,'地图').click()
(4)partial_link_text定位(部分超链接定位)
link_text的拓展。
driver.find_element(By.PARTIAL_LINK_TEXT,'地').click()
(5)class_name定位
和id、name的定位方式一样,定位属性为class的元素。
driver.find_element(By.CLASS_NAME,'title-content-title').click() # 只能找到第一个元素
(6)xpath定位
这种定位方式十分主要,和css定位必须要掌握其中一种。可以说,掌握了就能解决绝大多数的问题
CTRL+F输入标签查看是否唯一,再使用xpath或者css时,可以先用CTRL+F定位查看是否正确
1. 绝对路径:开头只有一个/
右键元素,选择copy,点击copy full xpath复制绝对路径,但是复制xpath的方法经常出错。

得到绝对路径:/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input
CTRL+F定位查看是否定位成功
 说明能够精确定位到搜索框
说明能够精确定位到搜索框
driver.find_element(By.XPATH,'/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input').send_keys('奥运会')
2. 相对路径:开头是两个/
(1)相对路径+索引定位
//form/span[1]/input
如果input是唯一的那么就可以直接查找。唯一的开头标签form下面的span,但是span有多个,定位在第一个,直到找到input 注意:这里的索引不是python里面的索引

这里也能精确定位到搜索框
driver.find_element(By.XPATH,'//form/span[1]/input').send_keys('奥运会')
(2)相对路径+属性定位
//input[@maxlength='255']
注意理解,在input标签下的属性,呼叫(@)这个属性(唯一的)
这里就不演示CTRL+F了,反正能精确定位。
driver.find_element(By.XPATH,'//input[@maxlength="255"]').send_keys('奥运会')
(3)相对路径+通配符定位
//*[@maxlength='255']
在所有的标签下查找属性为maxlength='255' ,也可以写//*[@*="255"] 在所有的标签下查找所有的属性值为255。
driver.find_element(By.XPATH,'//*[@maxlength="255"]').send_keys('许昕')
driver.find_element(By.XPATH,'//*[@*="255"]').send_keys('许昕')
driver.find_element(By.XPATH,'//input[@type="submit"]').click() # 点击进入(4)相对路径+部分属性值定位
//*[starts-with(@maxlength,'2')] 属性值@maxlength以2开头
//*[substring(@maxlength,2)=55] 属性值以第二个字符开始到结尾截取为55
//*[contains(@maxlength,'25')] 属性值包含25
driver.find_element(By.XPATH,'//input[starts-with(@name,"w")]').send_keys('马龙') # 开始
driver.find_element(By.XPATH,'//input[(substring(@maxlength,2)="55")]').send_keys('吕小军') # 从第2个开始是‘55’
driver.find_element(By.XPATH,'//input[contains(@maxlength,"55")]').send_keys('阿凡达') # 包含(5)相对路径+文本定位
<span class="soutu-hover-tip" style="display: none;">按图片搜索</span>
查找文本但是没有超链接,不能使用LINK_TEXT,所以只能使用文本定位
//span[text()='按图片搜索']
driver.find_element(By.XPATH,' //span[text()="按图片搜索"]')
(7)css定位
给出一个HTML的一个例子,大家可以根据学习xpath的方法,学习css。
注意:在css中,class用 . 来代替,id用 # 来代替。
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title> css locate </title>
</head>
<body>
<div class="formdiv">
<form name="fnfn">
<input name="username" type="text"></input>
<input name="password" type="text"></input>
<input name="continue" type="button"></input>
<input name="cancel" type="button"></input>
<input value="SYS123456" name="vid" type="text">
<input value="ks10cf6d6" name="cid" type="text">
</form>
<div class="subdiv">
<a href="http://www.baidu.com" id="baiduUrl">baidu</a>
<ul id="recordlist">
<p>Heading</p>
<li>Cat</li>
<li>Dog</li>
<li>Car</li>
<li>Goat</li>
</ul>
</div>
</div>
</body>
</html>以下讲的很清楚,大家一定要结合以上的HTML看,这样会更懂的。
| div | 匹配所有div标签 |
| div.formdiv | 匹配 <div class="formdiv">,class为. |
| #recordlist | 匹配 <ul id="recordlist">,id为# |
| div.subdiv p | 匹配div标签下属性class=‘subdiv’,然后下面的p标签,即<p>Heading</p> |
| div.subdiv>ul>p | 匹配div标签下属性class=‘subdiv’,下面的ul标签,下面的p标签,即<p>Heading</p> |
| form+div | 匹配form标签之后的同级标签div(只匹配一个),即<div class="subdiv"> |
| p+li | 匹配p标签之后的同级标签li(只匹配一个),即<li>Cat</li> |
| p~li | 匹配p标签之后的所有li标签,<li>Cat</li>(还有3个就不一一列出) |
| form>input[name=username] | 匹配form 下面的input标签中的属性name的属性值为username,即<input name="username" type="text"></input> |
| input[name$=id][value^=SYS] | 匹配input标签下面的name属性,它的属性值以id结尾和value属性以SYS开头的元素,即<input value="SYS123456" name="vid" type="text"> |
| input[value*='SYS'] | 匹配input标签下面的value属性,属性值包含SYS的元素<input value="SYS123456" name="vid" type="text"> |
| a:link | 匹配a标签下的带有的网站,即<a href="http://www.baidu.com">baidu</a> |
| input:first-child | 匹配form标签的第一个元素并且为input标签,即<input name="username" type="text"></input> |
| input:last-child | 匹配input标签的最后一个元素并且为input标签,即<input value="ks10cf6d6" name="cid" type="text"> |
| li:nth-child(2) | 匹配ul标签下的第二个节点并且为li标签,即<li>Cat</li> |
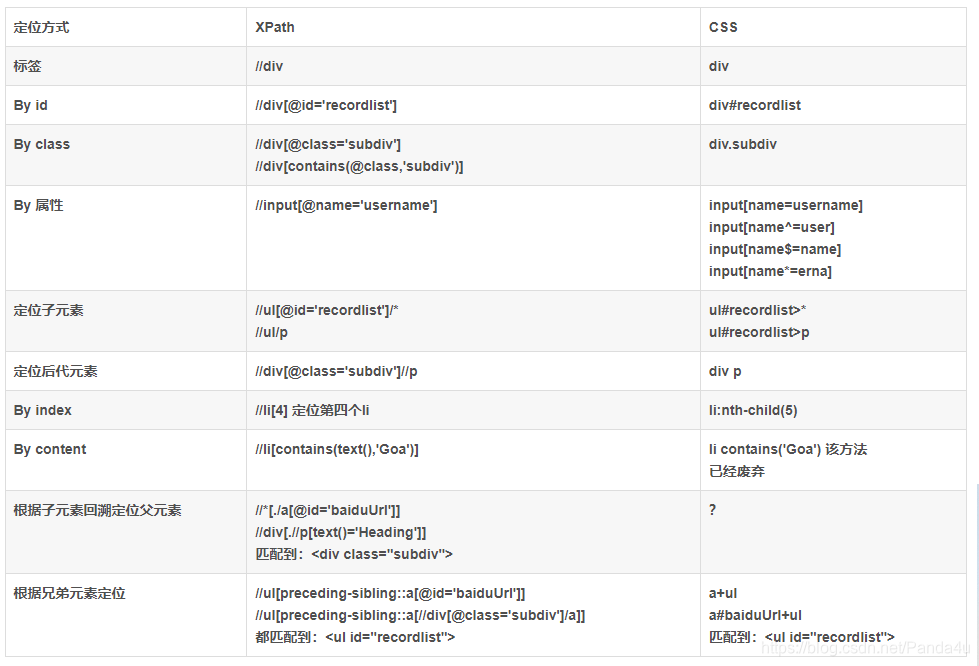
另外,根据以上xpath的学习,相信css也是大同小异,这里就直接给出了,xpath和css的定位方式的区别。
(8)tag_name定位
tag意思是标签的意识,那么顾名思义,这种方法就是根据标签名来定位,不过这种方法局限性很大,用途也不是很大。要是理解了xpath和css定位就会知道这种方法,定位出来的元素很难找到唯一。
driver.find_element(By.TAG_NAME,'input').send_keys('军神')
根本就定位不到百度的搜索框,因为input标签有很多个。
这里selenium定位元素就已经结束了。主要是掌握xpath或者css,以及id,name,link_text定位
下面就正式开始爬取前程无忧网站上面的 招聘信息。
三、利用selenium和beautifulsoup爬取网页实例
1. 启动驱动器加载网页
启动驱动器,开始加载网页。并在搜索框内搜索python,点击进入网页。
driver = webdriver.Chrome()
driver.get('https://www.51job.com/')
driver.find_element(By.ID,'kwdselectid').send_keys('python')
driver.find_element(By.CSS_SELECTOR,'body > div.content > div > div.fltr.radius_5 > div > button').click()
time.sleep(20)
# 在这20秒内,你还可以选择其它爬取的对象,例如爬取的地点范围,薪水等等
进入网页之后,还有20秒的时间选择条件你想要爬取数据,例如选择是工作地点,月薪范围等等。
2. 解析网页爬取数据
搜索全国的所有关于python的招聘信息,一共有1036页,每页有50条招聘信息,我这里爬取了前1000页。我们先对每页分析,然后利用循环爬取1000页。
(1) 解析页面
page = driver.page_source # 解析的是当前网页的内容
soup = BeautifulSoup(page,'html.parser')
注意:这里的 driver.page_source 获取当前网页的内容,然后利用beautifulsoup解析当前页面。
(2)soup搜索元素
这里给出对工作名称,工作的发布时间,薪水进行爬取,还有一些数据还没有写出。
job_names = soup.find_all('span',attrs={'class':'jname at'})
job_time = soup.find_all('span',attrs={'class':'time'})
job_salary = soup.find_all('span',attrs={'class':'sal'})最后将每条招聘的所有信息放在一个列表中(也就是一个列表里面就是一条招聘信息)。
for i in range(len(job_names)):
list_job = []
list_job.append(job_names[i].get_text())
list_job.append(job_time[i].get_text())
list_job.append(job_salary[i].get_text())然后利用pandas将列表换成Dataframe,然后添加进excel中,
pd = pd.DataFrame(list_all_job,columns=['职位名称','发布时间','薪水','公司地点','工作经验要求','学历要求','招聘人数','公司名称','公司类型','公司人数','工作类型'])
pd.to_excel(r'C:\Users\86178\Desktop\爬取51job.xlsx')这里补充一下,在循环1000中,每页的翻页
driver.find_element(By.XPATH,'//li[@class="next"]/a[@style="cursor: pointer;"]').click() # 点击进入下一页
最后我爬取的50000条招聘信息。

四、完整代码
# coding = utf-8
from selenium import webdriver
from bs4 import BeautifulSoup
from selenium.webdriver.common.by import By
import pandas as pd
import time
driver = webdriver.Chrome()
driver.get('https://www.51job.com/')
driver.find_element(By.ID,'kwdselectid').send_keys('python')
driver.find_element(By.CSS_SELECTOR,'body > div.content > div > div.fltr.radius_5 > div > button').click()
list_all_job = []
time.sleep(20)
# 在这20秒内,你还可以选择其它爬取的对象,例如爬取的地点范围,薪水等等
for start in range(1000):
page = driver.page_source # 解析的是当前网页的内容
soup = BeautifulSoup(page,'html.parser')
job_names = soup.find_all('span',attrs={'class':'jname at'})
job_time = soup.find_all('span',attrs={'class':'time'})
job_salary = soup.find_all('span',attrs={'class':'sal'})
job_info = soup.find_all('span',attrs={'class':'d at'})
job_local,job_exp,job_educcation,job_num = [],[],[],[]
for info in job_info:
line = info.get_text().strip().split('|')
if len(line) == 4:
job_local.append(line[0].strip())
job_exp.append(line[1].strip())
job_educcation.append(line[-2].strip())
job_num.append(line[-1].strip())
elif len(line) == 3 :
job_local.append(line[0].strip())
job_exp.append(line[1].strip())
job_educcation.append('')
job_num.append(line[2].strip())
else :
job_local.append(line[0].strip())
job_exp.append('')
job_educcation.append('')
job_num.append('')
company_names = soup.find_all('a',attrs={'class':'cname at'})
# 有的公司招聘信息不全
company_types = soup.find_all('p',attrs={'class':'dc at'})
company_type,company_space = [],[]
for type in company_types:
if '|' in type.get_text():
line = type.get_text().strip().split('|')
company_type.append(line[0].strip())
company_space.append(line[1].strip())
else :
company_type.append(type.get_text())
company_space.append('')
job_type = soup.find_all('p',attrs={'class':'int at'})
for i in range(len(job_names)):
list_job = []
list_job.append(job_names[i].get_text())
list_job.append(job_time[i].get_text())
list_job.append(job_salary[i].get_text())
list_job.append(job_local[i])
list_job.append(job_exp[i])
list_job.append(job_educcation[i])
list_job.append(job_num[i])
list_job.append(company_names[i].get_text())
list_job.append(company_type[i])
list_job.append(company_space[i])
list_job.append(job_type[i].get_text())
list_all_job.append(list_job)
time.sleep(2)
driver.find_element(By.XPATH,'//li[@class="next"]/a[@style="cursor: pointer;"]').click() # 点击进入下一页
pd = pd.DataFrame(list_all_job,columns=['职位名称','发布时间','薪水','公司地点','工作经验要求','学历要求','招聘人数','公司名称','公司类型','公司人数','工作类型'])
pd.to_excel(r'C:\Users\86178\Desktop\爬取51job.xlsx')
补充:
下一期我会对爬取的数据做数据分析。很有趣的是我发现了一个非常好的绘图工具pyecharts。matplotlib是一个静态的,然而pyecharts是一个动态的,而且功能非常全面。
绘制工作类型词云图,

例如,这是我根据招聘信息中公司所处的位置,绘制的关于全国python的招聘公司的分布图。

如果大家有什么疑问,可以尽管在评论区里面发言,我会尽量为大家解决!