准备阶段
前程无忧官网:https://www.51job.com/
本文对职位的爬取以python职位为例。
现在网站的反爬措施比较强,但可以用selenium进行爬取,虽然速度相对较慢但是爬取的方式较为方便。
我们在爬取之前需要安装和配置selenium和安装python所需的依赖库。
规划阶段
| 步骤 | 目标 | 函数名 | 所用知识 |
|---|---|---|---|
| 爬取前的准备 | 确定目标网站 | ready() | |
| 开始爬取 | 爬取网页代码 | begin() | selenium |
| 页面分析 | 得到解析的前端代码、得到职位总页数 | read_text()、getpage() | etree、xpath |
| 爬取数据 | 对各条职位信息进行查找与提取其中的数据 | save_database() | selenium |
| 数据清洗 | 将数据转化成特定的格式 | data_change_xinxi()、data_change_jy()、data_change_money() | re正则表达式 |
| 数据存储 | 把数据存入sqlite与csv中 | save_csv()、save_database() | sql语句、sqlite |
代码编写阶段
1.爬取前的准备:
from lxml import etree
import sqlite3
from selenium import webdriver
import time
import re
import csv
def ready():
url='https://search.51job.com/list/000000,000000,' \
'0000,00,9,99,%25E7%25BD%2591%25E7%25BB%259C,2,2.html?lang=c&post' \
'channel=0000&workyear=99&cotype=99°reefrom=99' \
'&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare='
begin(url)
2.开始爬取
#开始爬取
def begin(url):
opt=webdriver.ChromeOptions()
opt.add_argument('--headless')
opt.add_argument('--disable-gpu') #无界面模式
drive = webdriver.Chrome(options=opt)
drive.get(url)
#page=getpage(drive.page_source) #总页数
#由于网站更新,已获取不到page总页数
#for i in range(page): #对每一页进行自动操作和爬取,控制最大页面为page页
for i in range(100):#对每一页进行自动操作和爬取,控制最大页面为100页
time.sleep(2) #每一页爬取完毕休息,减少给对方服务器造成的压力
text = drive.page_source
text_zw = read_text(text)
save_database(text_zw)
#可能在爬取进行的时候,职位页数有减少
try:
drive.find_element_by_xpath('//li[@class="next"]//i[@class="e_icons"]').click()#寻找下一页按钮并自动点击下一页
except:
drive.quit()
return
print('第%d页爬取完毕' % (i + 1))
time.sleep(5)
drive.quit()
3.页面解析
#利用xpath解析得到该页所有职位元素,返回所有职位元素,供后续提取
def read_text(text):
tree=etree.HTML(text)
all_zw=tree.xpath('//div[@class="j_joblist"]/div[@class="e"]')
return all_zw
def getpage(url_text):
text=etree.HTML(url_text)
page_text=text.xpath('//div[@class="j_page"]//div[@class="p_in"]/span[1]/text()')[0]
page_text=re.findall('\d+',page_text)[0]
page=int(page_text)
return page
4.爬取数据与存入数据库
#利用sqlite来存储数据
def save_database(all_zw):
connect = sqlite3.connect("wl.db") #数据库文件地址,数据库连接
c = connect.cursor() #游标建立
sql = '''
create table job(
name text,
money text,
pj_money int,
company text,
place text,
expri text,
min_expri int,
xueli text,
num text,
job_url text,
company_xinxi1 text,
company_xinxi2 text,
fl text
)
'''
try: #执行sql语句,建立数据表
c.execute(sql)
connect.commit()
except:
pass
for zw in all_zw: #对所有职位的信息进行提取
zw_name = ''.join(zw.xpath('.//p[@class="t"]/span[1]/text()')) #职位名称
zw_money = ''.join(zw.xpath('.//p[@class="info"]/span[1]/text()')) #职位工资
pj_money=data_change_money(zw_money) #对职位工资进行处理,得到平均工资
xinxi3=''
try:
xinxi = zw.xpath('.//p[@class="info"]/span[2]/text()')[0] # 职位信息(地点、经验、学历、招聘人数)
xinxi3 = data_change_xinxi(xinxi) #对信息进行处理
zw_place = xinxi3[0] # 地点
except:
zw_place='null'
try:
zw_expri = xinxi3[1] # 经验
zw_xueli = xinxi3[2] # 学历
zw_num = xinxi3[3] # 招聘人数
min_jy = data_change_jy(zw_expri) # 提出最低经验要求
except:
zw_expri = 'null'
zw_xueli = 'null'
zw_num = 'null'
min_jy = -2
company_xinxi2 = ''.join(zw.xpath('./div[@class="er"]/p[2]/text()')) # 公司类型
zw_company = ''.join(zw.xpath('./div[@class="er"]/a/text()')) #公司名称
job_url = ''.join(zw.xpath('.//a/@href')) #职位的url
if 'jobs.51job.com' not in job_url: #筛选出该关键词的网站,为之后的再次爬取做准备
job_url=''
company_xinxi1 = ''.join(zw.xpath('./div[@class="er"]/p[1]/text()')) #外资合资
fl_all=zw.xpath('.//p[@class="tags"]//i') #公司福利(五险一金、补贴等)
fl=''
for f in fl_all: #福利
fl=fl+''.join(f.xpath('./text()'))
csv_list=[zw_name, zw_money,pj_money, zw_company, zw_place, zw_expri, min_jy,zw_xueli, zw_num,job_url,company_xinxi1,company_xinxi2,fl]#存入csv
save_csv(csv_list)
# print(zw_name, zw_money,pj_money, zw_company, zw_place, zw_expri,min_jy, zw_xueli, zw_num,job_url,company_xinxi1,company_xinxi2,fl)
try:#将每个职位的信息存入数据表
sql2 = '''
insert into job
(name,money,pj_money,company,place,expri,min_expri,xueli,num,job_url,company_xinxi1,company_xinxi2,fl)
values("%s","%s",%d,"%s","%s","%s",%d,"%s","%s","%s","%s","%s","%s")
''' % (zw_name, zw_money,pj_money, zw_company, zw_place, zw_expri,min_jy, zw_xueli, zw_num,job_url,company_xinxi1,company_xinxi2,fl)
c.execute(sql2)
connect.commit()
except:
pass
c.close()#关闭游标
connect.close()#关闭数据库
5.数据清洗
#对工资进行处理,返回平均工资类型为int
def data_change_money(zw_money):
int_money = re.findall(r'\d+\.?\d*', zw_money)
if '万/年' in zw_money or '万以上/年' in zw_money:
if len(int_money) == 2:
pj1_money = (float(int_money[0]) + float(int_money[1])) / 2 * 10000 / 12
pj_money = int(format(pj1_money, '.0f'))
else:
pj1_money = float(int_money[0]) * 10000 / 12
pj_money = int(format(pj1_money, '.0f'))
elif '万/月' in zw_money or '万以上/月' in zw_money:
if len(int_money) == 2:
pj1_money = (float(int_money[0]) + float(int_money[1])) / 2 * 10000
pj_money = int(format(pj1_money, '.0f'))
else:
pj1_money = float(int_money[0]) * 10000
pj_money = int(format(pj1_money, '.0f'))
elif '千/月' in zw_money:
if len(int_money) == 2:
pj1_money = (float(int_money[0]) + float(int_money[1])) / 2 * 1000
pj_money = int(format(pj1_money, '.0f'))
else:
pj1_money = float(int_money[0]) * 1000
pj_money = int(format(pj1_money, '.0f'))
elif '元/天' in zw_money:
if len(int_money) == 2:
pj1_money = (float(int_money[0]) + float(int_money[1])) / 2 * 30
pj_money = int(format(pj1_money, '.0f'))
else:
pj1_money = float(int_money[0]) * 30
pj_money = int(format(pj1_money, '.0f'))
else:
pj_money =-2 #值为-2的都表示之后不处理
return pj_money
#将(地点、经验、学历、招聘人数)信息进行分割,返回一个列表
def data_change_xinxi(xinxi):
xinxi2 = xinxi.split('|')
xinxi3 = []
for xx in xinxi2:
xinxi3.append(xx.strip())
return xinxi3
#提出最低经验要求,类型为int
def data_change_jy(zw_expri):
int_jy = re.findall(r'\d+', zw_expri)
if '在校生' in zw_expri:
min_jy=-1
return min_jy
if '无需经验' in zw_expri:
min_jy=0
return min_jy
try:
min_jy = int(int_jy[0])
except:
min_jy=-2
return min_jy
6.存入csv
#将数据存入csv
def save_csv(csv_list):
with open(r'wl2.csv', 'a', newline='') as file_csv: #csv地址
csv_write=csv.writer(file_csv)
csv_write.writerow(csv_list)
file_csv.close()
运行展示
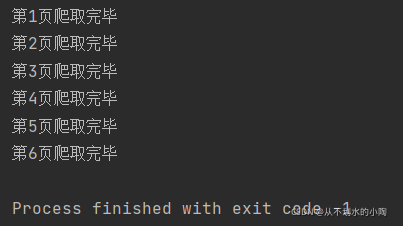
程序运行控制台展示:
文件路径生成:
“51job_spider.py”为爬虫运行文件
“wl.db”为生成的sqlite数据库文件
“wl2.csv”为生成的csv文件

使用SQLiteSpy可视化软件查看生成的sqlit数据库文件
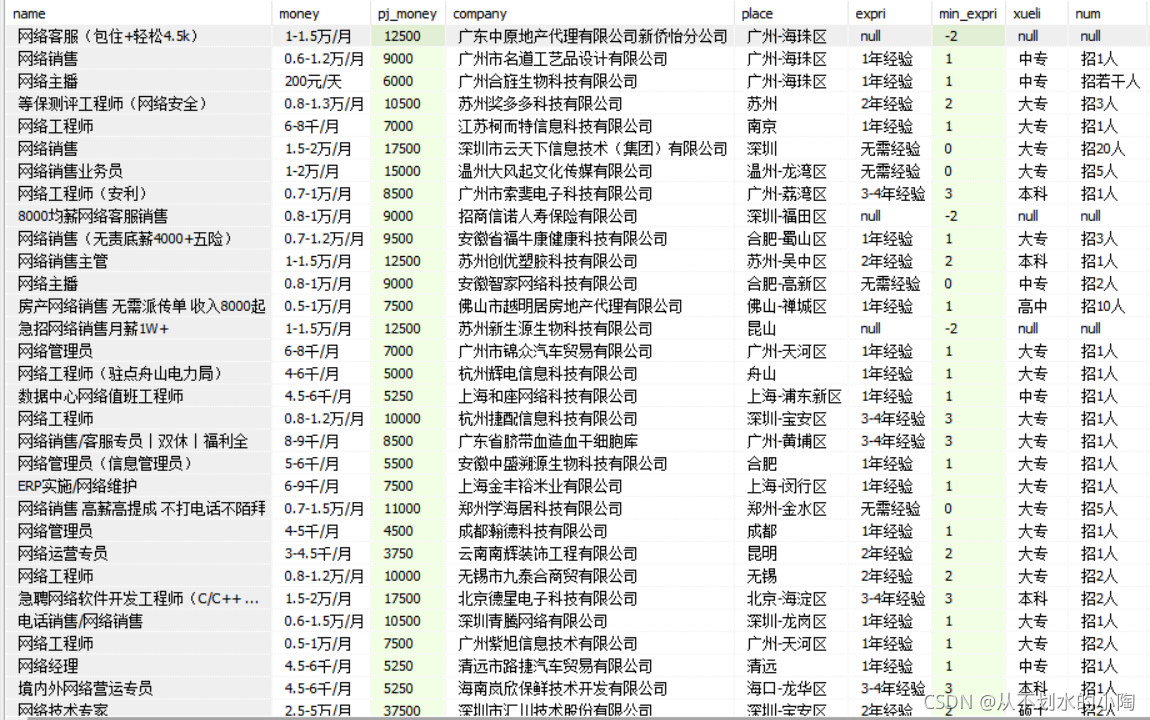

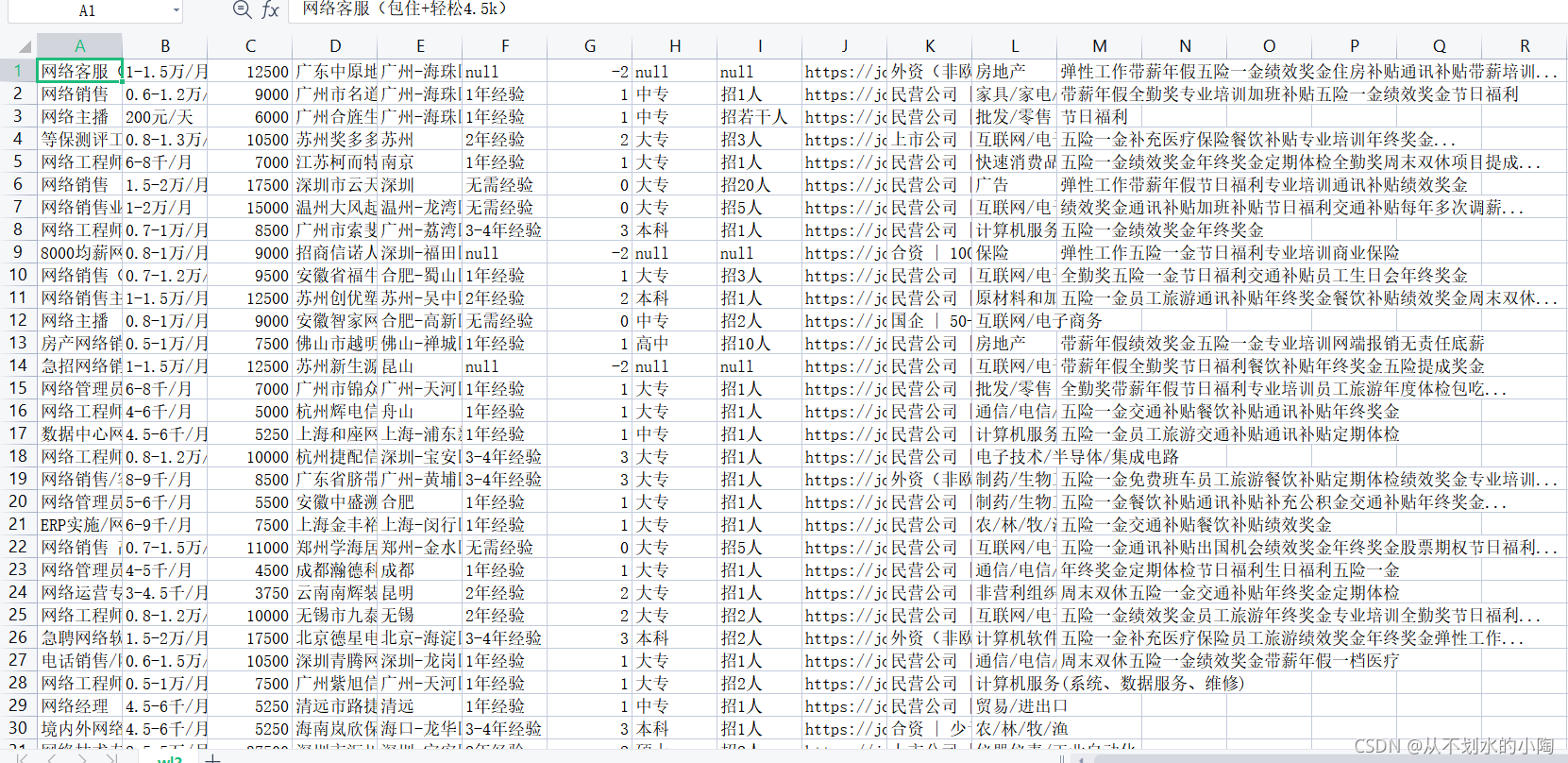
生成csv文件中的数据:
爬取了海量数据后,接下来就是数据分析与可视化的过程。