问题描述
从前程无忧网站:https://www.51job.com/上查询热点城市(北京、上海、广州、深圳、武汉、西安、杭州、南京、成都、苏州)程序员的招聘信息。要求在Excel文件中保存招聘信息(职位名、公司名、工作地点、薪资、发布时间),每个城市一工作表,统计出每个城市招聘职位总数,并按从高到低顺序排序,输出到Excel的一个工作表中,并画出各城市招聘职位数分圆饼图。
广州程序员信息
from lxml import etree
import requests
import csv
temp='C:\\Users\\lenovo\\Desktop'+'\\'+'广州程序员工作'
with open(temp+'.csv','a',newline='') as f:
csvwriter=csv.writer(f,dialect='excel')
csvwriter.writerow(['职位','公司名称','地址','薪水','发布日期'])
headers = {
"cache-control": "no-cache",
"postman-token": "72a56deb-825e-3ac3-dd61-4f77c4cbb4d8",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36",
}
#广州程序员工作的页数
for i in range(1,12):
#网址
url='https://search.51job.com/list/030200,000000,0000,00,9,99,%25E7%25A8%258B%25E5%25BA%258F%25E5%2591%2598,2,{}.html?'.format(i)
respond = requests.get(url,headers=headers)
respond.encoding='gbk'
respond1=respond.text
html=etree.HTML(respond1)
work_name=html.xpath('//div[@id="resultList"]/div[@class="el"]/p/span/a/@title')
company_name=html.xpath('//div[@id="resultList"]/div[@class="el"]/span[@class="t2"]/a/@title')
work_place=html.xpath('//div[@id="resultList"]/div[@class="el"]/span[@class="t3"]/text()')
salary=html.xpath('//div[@id="resultList"]/div[@class="el"]/span[@class="t4"]/text()')
date=html.xpath('//div[@id="resultList"]/div[@class="el"]/span[@class="t5"]/text()')
for a,b,c,d,e in zip(work_name,company_name,work_place,salary,date):
print(a,b,c,d,e)
with open(temp+'.csv','a',newline='') as f:
csvwriter=csv.writer(f,dialect='excel')
csvwriter.writerow([a,b,c,d,e])

爬取其他几个城市程序员工作的代码与此类此,只需将城市名称,页数和网址更换即可,在此不一一列举。
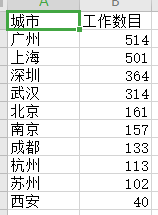
以下代码是将各个城市程序员工作数目统计到一张表格中。并绘制圆饼图和条形统计图。
import pandas as pd
import matplotlib.pyplot as plt
import csv
temp='C:\\Users\\lenovo\\Desktop'+'\\'+'热门城市程序员工作数目统计'
with open(temp+'.csv','a',newline='') as f:
csvwriter=csv.writer(f,dialect='excel')
csvwriter.writerow(['城市','工作数目'])
guangnumber=pd.read_csv(open(r'C:\Users\lenovo\Desktop\Python爬虫\广州程序员工作.csv'),sep=',')
beinumber=pd.read_csv(open(r'C:\Users\lenovo\Desktop\Python爬虫\北京程序员工作.csv'),sep=',')
shangnumber=pd.read_csv(open(r'C:\Users\lenovo\Desktop\Python爬虫\上海程序员工作.csv'),sep=',')
shengnumber=pd.read_csv(open(r'C:\Users\lenovo\Desktop\Python爬虫\深圳程序员工作.csv'),sep=',')
wunumber=pd.read_csv(open(r'C:\Users\lenovo\Desktop\Python爬虫\武汉程序员工作.csv'),sep=',')
xinumber=pd.read_csv(open(r'C:\Users\lenovo\Desktop\Python爬虫\西安程序员工作.csv'),sep=',')
hangnumber=pd.read_csv(open(r'C:\Users\lenovo\Desktop\Python爬虫\杭州程序员工作.csv'),sep=',')
nannumber=pd.read_csv(open(r'C:\Users\lenovo\Desktop\Python爬虫\南京程序员工作.csv'),sep=',')
chengnumber=pd.read_csv(open(r'C:\Users\lenovo\Desktop\Python爬虫\成都程序员工作.csv'),sep=',')
sunumber=pd.read_csv(open(r'C:\Users\lenovo\Desktop\Python爬虫\苏州程序员工作.csv'),sep=',')
plt.rcParams['font.sans-serif'] = 'SimHei' ## 设置中文显示
plt.rcParams['axes.unicode_minus'] = False
dic={'广州':len(guangnumber),'北京':len(beinumber),'上海':len(shangnumber),'深圳':len(shengnumber),
'武汉':len(wunumber),'西安':len(xinumber),'杭州':len(hangnumber),'南京':len(nannumber),'成都':
len(chengnumber),'苏州':len(sunumber)}
dict=sorted(dic.items(),key=lambda
x:x[1],reverse=True)
name=[]
number=[]
for key,value in dict:
name.append(key)
number.append(value)
with open(temp+'.csv','a',newline='') as f:
csvwriter=csv.writer(f,dialect='excel')
csvwriter.writerow([key,value])
sum=0
numbers=[]
for i in number:
sum+=i
for i in number:
numbers.append(i/sum)
plt.xlabel('热门城市')
plt.ylabel('程序员工作数目')
plt.title('热门城市程序员工作数目统计')
plt.bar(range(len(name)),number,tick_label=name)
plt.show()
figl,axl=plt.subplots() #图版
axl.pie(numbers,labels=name,autopct="%1.1f%%",shadow=True) #autopct自动分配颜色
axl.axis('equal') #进行美化处理
plt.title('热门城市程序员工作分布圆饼图')
plt.show()
以下是效果图: