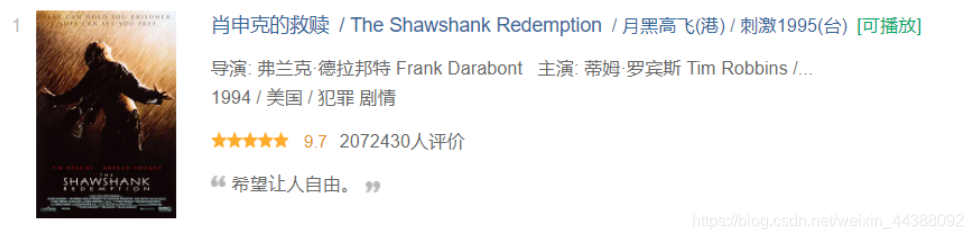
爬取豆瓣top250电影说明
(链接:https://movie.douban.com/top250,可爬取一页或者多页(输出电影的正标题(肖申克的救赎),副标题( The Shawshank Redemption)、其他名( / 月黑高飞(港) / 刺激1995(台))、导演和主演(导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /…)、年份(1994)、国家(美国)、类型(犯罪 剧情)、评分(9.7)、评分人数(2072430)、名言(对应下图的希望让人自由)))
示例代码
# -*- coding: utf-8 -*-
# author:Gary
import requests # 获取网页内容
from bs4 import BeautifulSoup # 解析网页内容
import re # 正则匹配内容
# 获取网页的内容
def get_html(URL):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/79.0.3945.130 Safari/537.36'}
res = requests.get(URL, headers=header) # 获取网页,并带有伪装的浏览器头,一般好的网站会有检测是不是程序访问
res.encoding = res.apparent_encoding # 设置编码,防止乱码
# print(res.text)#输出网页内容
return res.text # 返回网页的内容
# 通过bs4解析,主要是标签选择器
def ana_by_bs4(html):
soup = BeautifulSoup(html, 'html.parser') # 注意需要添加html.parser解析
lis = soup.select("ol li") # 选择ol li标签
for li in lis:
index = li.find('em').text # 索引
title = li.find_all('span', class_='title') # 正标题
the_title = title[0].text # 正标题
if len(title) > 1: # 如果title存在两个则表明存在副标题
sub_title = title[1].text
else:
sub_title = ''
try:
other_title = li.find('span', class_='other').text # 其他标题
except:
other_title = ''
actor = li.find('div', class_='bd').find('p').text.split('\n')[1].strip() # 导演和演员
strInfo = re.search("(?<=<br/>).*?(?=<)", str(li.select_one(".bd p")), re.S | re.M).group().strip() # 年份、国家、类型
infos = strInfo.split('/')
year = infos[0].strip() # 年份
area = infos[1].strip() # 国家,地区
m_type = infos[2].strip() # 类型
rating = li.find('span', class_='rating_num').text # 评分
remark_num=li.find('div',class_='star').find_all('span')[3].text[:-3]#评分人数
try:
quote = li.find('span', class_='inq').text # 名言
except: # 名言可能不存在
quote = ''
# print(actor)
print(index, the_title, sub_title, other_title, actor, year, area, m_type, rating,remark_num, quote)
if __name__ == '__main__':
for page in range(10):
print('第{}页'.format(page + 1))
print('正标题', '副标题', '其他标题', '导演和主演', '年份', '地区', '类型', '评分', '评分人数','名言')
url = 'https://movie.douban.com/top250?start={}&filter='.format(page * 25) # 电影的url,有多页的时候需要观察url的规律
text = get_html(url) # 获取网页内容
ana_by_bs4(text) # bs4方式解析