1.介绍
使用python采用requests+bs4爬取豆瓣top250图书信息,参考代码中都有注释就不详细说了。
链接:https://book.douban.com/top250?start=0
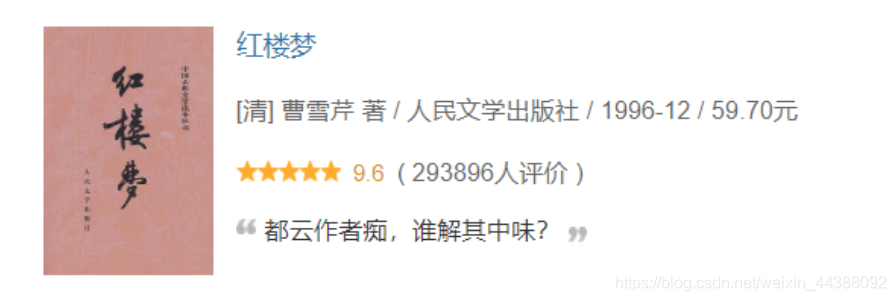
可以输出的内容:(对应上图举例)
图书封面的链接:https://img1.doubanio.com/view/subject/s/public/s1070959.jpg
书名:红楼梦
作者:[清] 曹雪芹 著
出版社: 人民文学出版社
发行年份:1996-12
价格:59.70元
评分:9.6
评价人数:293896
名言:都云作者痴,谁解其中味?
实现的功能:可以分页爬取所有top250的图书信息以及存储相关数据进入数据库。
2.参考代码
# -*- coding: utf-8 -*-
# author:Gary
import requests # 获取网页内容
from bs4 import BeautifulSoup # 解析网页内容
import pymysql
# 获取网页的内容
def get_html(url):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/79.0.3945.130 Safari/537.36'}
res = requests.get(url, headers=header) # 获取网页,并带有伪装的浏览器头,一般好的网站会有检测是不是程序访问
res.encoding = res.apparent_encoding # 设置编码,防止乱码
# print(res.text)#输出网页内容
return res.text # 返回网页的内容
# 通过bs4解析,主要是标签选择器
def ana_by_bs4(html):
soup = BeautifulSoup(html, 'html.parser') # 注意需要添加html.parser解析
tables = soup.find_all("table") # 选择table标签
# 或者通过tr的class属性定位
# trs = soup.find_all('tr', class_='item')
data_list = []
for table in tables:
img = table.find('img')['src'] # 图片链接
# title = table.find('div', class_='pl2').text.strip() # 正标题
title = table.find('div', class_='pl2').find('a')['title'] # 去除多余换行
strInfo = table.find('p', class_='pl').text.strip() # 作者、出版社、年份、价格等信息
'''
infos = strInfo.strip() .split('/')#有多作者的可能,这个方面就会出错
# print(infos)
author = infos[0].strip().replace('\n','') # 作者
pub = infos[1].strip() # 出版社
year = infos[2].strip() # 年份
price = infos[3].strip() # 价格
'''
infos = strInfo.strip().split('/') # 有多作者的可能
author_list = infos[:-3]
author = ''
for item in author_list:
author += '/' + item.strip().replace('\n', '') # 作者
author = author[1:] # 因为多了一个/,所以第一个/不输出,优化输出效果
pub = infos[-3].strip() # 出版社
year = infos[-2].strip() # 年份
price = infos[-1].strip() # 价格
rating = table.find('span', class_='rating_nums').text.strip() # 评分
remark_num = table.find('span', class_='pl').text.replace('\n', '').strip()[20:-3] # 评分人数
try:
quote = table.find('span', class_='inq').text.replace('\n', '') # 名言
except: # 名言可能不存在
quote = ''
# 优化输出模式
print('---------------------------------华丽的分割线--------------------------------------')
# print('图片封面链接', '书名', '作者', '出版社', '年份', '价格', '评分', '评分人数', '名言')
print('图片封面链接:', img)
print('书名:', title)
print('作者:', author)
print('出版社:', pub)
print('出版年份:', year)
print('售价:', price)
print('评分:', rating)
print('评价人数:', remark_num)
print('名言或评注:', quote)
# print(img, title, author,pub, year, price, rating,remark_num, quote)
data_list.append((img, title, author, pub, year, price, rating, remark_num, quote))
return data_list
# 存储数据
def insert_data(data_list):
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='Xts0916.', db='spider',
charset='utf8') # 连接数据库
cur = conn.cursor() # 用于访问和操作数据库中的数据(一个游标,像一个指针)
# 首先得保证存在spider数据库,然后库中有books表,属性和下面的对应
sql = 'insert into books(img_href, title, author,pub, pub_year, price, grade,remark_num, quote) values(%s,%s,%s,%s,%s,%s,%s,%s,%s)' # 插入多条
cur.executemany(sql, data_list) # data_list类型是列表中嵌套多个元组比如[(),(),()]
conn.commit() # 提交事务,执行了这一步数据才真正存到数据库
cur.close() # 关闭游标
conn.close() # 关闭数据库连接
if __name__ == '__main__':
for page in range(10):
print('第{}页'.format(page + 1))
single_url = 'https://book.douban.com/top250?start={}'.format(page * 25) # 图书每一页的url,有多页的时候需要观察url的规律
text = get_html(single_url) # 获取网页内容
# print(text)
dataList = ana_by_bs4(text) # bs4方式解析
# insert_data(dataList) # 数据存入数据库