以51job网上爬取的一万条电商类招聘信息为样本,具体分析该行业的就业前景、工作地点、平均薪资和任职要求等
本文主要通过词云图和可视化图表对数据进行展示描述
1.先上样本信息图(由于太多,只截了一部分)


第一张图包括了职位名称、公司名称、工作地点、薪资、发布时间(公司的发布时间,我爬的时候是2020.6.24号)和详情页的url链接;第二张图中就是链接网页的具体内容,描述了该岗位的工作信息和任职要求 。
以下数据可视化全部基于上述爬取的样本信息。
2.词云图展示
(1)工作岗位

通过对职位名称图的观察分析,发现在采集的一万条样本信息中,管理类的岗位需求量较高,如运营、经理、主管、总监、客服等均排名前几位;技术类的岗位需求相对较少,如美工,设计、平面等出现的次数较少;同时随着社交电商的发展以及疫情的影响,电商直播,电商主播等形式也渐渐丰富,直播类岗位较之前有了明显增加;
同时电商类岗位也常与电商平台结合起来,如亚马逊,淘宝,天猫,京东,速卖通等;
随着全球化的发展,商品的海内外流动更加频繁,跨境电商前景颇好。
(2)工作地点

通过观察分析,发现目前做电商最热门的城市还是北京、上海、广州、深圳和东南沿海经济发达的城市,相较之下,一些内地城市,如武汉、长沙、昆明、西安等提供的岗位数量较少,电商发展受限;
另外,一些西南地区如成都、重庆等新一线城市政策环境良好,电商岗位需求量增加,对人才的吸引力强,电商发展的潜力很大。
(3)任职要求

观察分析后,发现电商企业青睐运营管理类人才,要求有一定的实操经验,能够与国内知名的电商平台结合,熟悉电商平台的运行规则和活动推广,了解店铺的上新维护,以客户为导向,提供高质量的服务体验。
在求职者素质方面,电商企业比较看重求职者的能力,学历要求不高,具有责任心和团队合作精神,具有良好的沟通能力等。
3.可视化图表
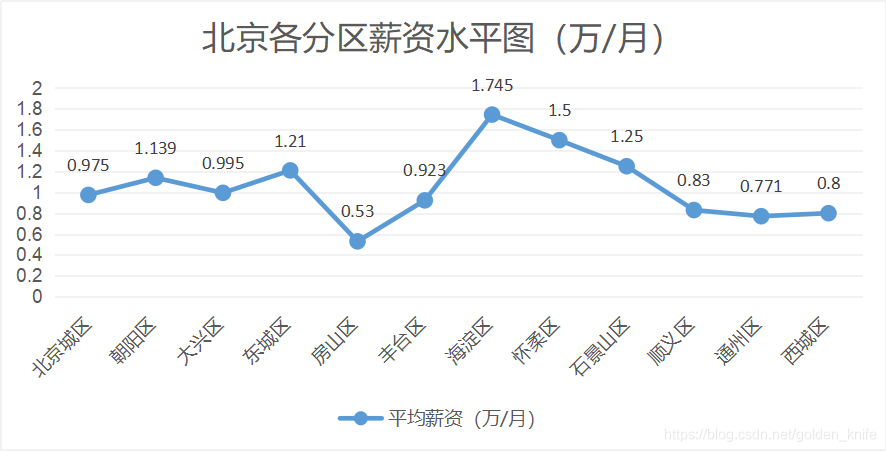
(1)平均薪资和岗位数量分布
Excel数据分析的目的是得出目前电商行业的平均薪资,对北上广深杭——大多数有意从事电商行业的毕业生可能会选择的城市做具体的分析。
北京


广州



上海



深圳



杭州



(2)北上广深杭与全国平均薪资水平对比

在一万条样本数据中,广州市计算得出的平均薪资是0.814万/月,低于全国平均薪资0.86万/月,也是五个城市中唯一一个薪资水平低于全国平均水平的城市;
而北京市平均薪资高达1.056万/月,领跑全国,上海市紧随其后,杭州深圳平均薪资也快接近1万,发展潜力很大。
4.爬虫代码
主要采用requests和BeautifulSoup库对前程无忧招聘网进行爬取,搜索框键入电商,得到跳转页面,前1万条电商职位数据即为本文采集的样本数据。
爬取的部分代码信息块(主要是工作岗位、公司名、地点、发布时间、薪资、详情页链接)
def getjoblist(lf,joburl,lst): #定义工作的(每一页的,后面会随着for循环不断到第二页)列表,里面存放职位名等信息和每个详情页的url链接,lst表示每一大页的链接
la=[] #定义空列表存放职位名
lb=[] #存放公司名
lc=[] #存放地点
ld=[] #存放薪资
le=[] #存放发布时间
for joburl in lst:
html=gethtml(joburl)
soup=BeautifulSoup(html,'html.parser')
#lf=[] #存放每个页面中对应的工作列表详情页的链接
#应该还要有下一页
la.append('职位名')
lf.append('详情页链接')
for i in soup.find_all('p',class_='t1'):
la.append(i.text.split(' ')[20])
lf.append(i.a['href'])
for i in soup.find_all('span',class_='t2'):
lb.append(i.string)
for i in soup.find_all('span',class_='t3'):
lc.append(i.string)
for i in soup.find_all('span',class_='t4'):
ld.append(i.string)
for i in soup.find_all('span',class_='t5'):
le.append(i.string)
有需要完整代码块的同学可以私信我哦
数据可视化正在学习中
欢迎各位兄弟姐妹们前来指导