用了几天时间爬取了前程无忧上的数据进行分析,完成了一个小项目,
截取了部分代码,不足之处,你也打不到我!
pi… pi…
网站:前程无忧
数据库:MySQL
知识点:scrapy框架,mysql数据库,xpath,echarts,jeiba
直接看项目!
爬虫代码》》
import scrapy
from qiancheng.items import QianchengItem
class QcwyspiderSpider(scrapy.Spider):
name = 'qcwyspider'
# allowed_domains = ['https://search.51job.com']
start_urls = ['https://search.51job.com/list/030200,000000,0000,00,9,99,%%2B,2,%s.html'% k for k in range(2000)]
def parse(self, response):
temp = response.xpath('//div[@class="el"]/p/span/a/@href').extract()
for i in temp:
url = response.urljoin(i)
yield scrapy.Request(url=url, callback=self.parseContents, dont_filter=True)
def parseContents(self,response):
item = QianchengItem()
item['title'] = ''.join(response.xpath('//div[@class="in"]/div/h1/@title').extract())
item['salary'] = ''.join(response.xpath('//div[@class="in"]/div/strong/text()').extract())
item['company'] = ''.join(response.xpath('//div[@class="tHeader tHjob"]/div/div/p/a/@title').extract())
item['style'] = ''.join(response.xpath('//div[@class="tCompany_sidebar"]/div/div[@class="com_tag"]/p[1]/@title').extract())
yield item
item设置》》
import scrapy
class QianchengItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
salary = scrapy.Field() # 工资
company = scrapy.Field() # 公司
style = scrapy.Field() # 地址
pipelines(管道)设置》》
import pymysql
from scrapy.conf import settings as st
class QianchengPipeline(object):
def __init__(self):
self.conn = pymysql.connect(
host="127.0.0.1",
port=3306,
user='root',
password='12345678',
db='mysql'
)
self.cursor = self.conn.cursor()
self.cursor.execute('drop table if exists fangyuan')
sql = """create table fangyuan (
title char(255)not null,
company varchar(1000),
salary varchar(1000),
style varchar(1000)
)"""
self.cursor.execute(sql)
def process_item(self,item,spider):
print("开始储存---")
sql="insert into fangyuan(title,salary,company,style) values('%s','%s','%s','%s')" % (item['title'],item['salary'],item['company'],item['style'])
self.cursor.execute(sql)
self.conn.commit()
print("储存结束----")
return item
setting设置》》
BOT_NAME = 'qiancheng'
SPIDER_MODULES = ['qiancheng.spiders']
NEWSPIDER_MODULE = 'qiancheng.spiders'
ITEM_PIPELINES = {
'qiancheng.pipelines.QianchengPipeline': 300,
}
DEFAULT_REQUEST_HEADERS = {
'Referer': 'https://search.51job.com/jobsearch/search_result.php?fromJs=1&jobarea=030200%2C00&funtype=0000&industrytype=00&keyword='
}
DOWNLOAD_DELAY = 1
ROBOTSTXT_OBEY = True
爬虫部分结束。
开始可视化:
饼状图:》》
from pyecharts import Pie
import pymysql
con = pymysql.connect(
host="127.0.0.1",
port=3306,
user="root",
password="12345678",
db='mysql',
)
k = []
o = []
cursor = con.cursor(pymysql.cursors.DictCursor)
u = cursor.execute('''select style from fangyuan ''')
a = cursor.fetchall()
for y in a:
if y['salary'] not in k:
k.append(y["salary"])
for h in k:
r = cursor.execute('select style from fangyuan where style="%s"' % h)
o.append(r)
print(o)
print(k)
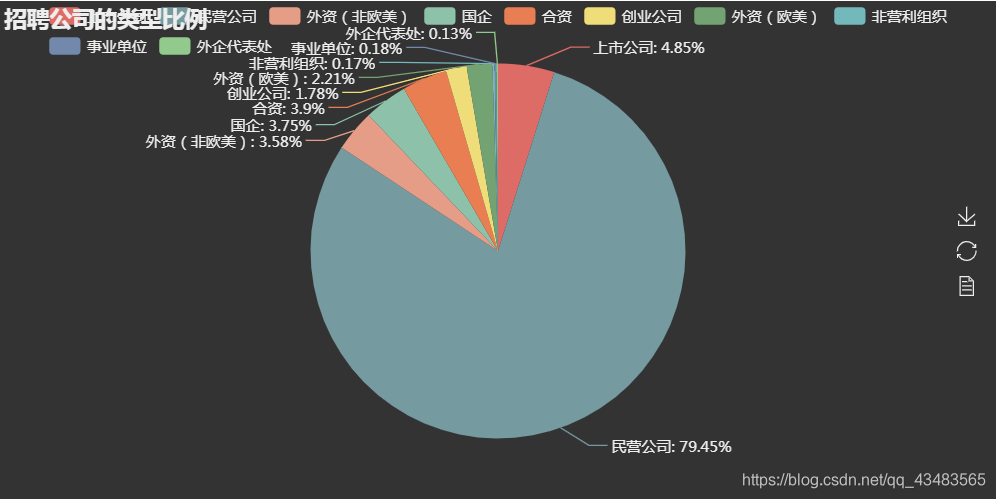
pie = Pie('招聘公司的类型比例')
attr = ['上市公司', '民营公司', '外资(非欧美)', '国企', '合资', '创业公司', '外资(欧美)', '非营利组织', '事业单位', '外企代表处']
v1 = [2597, 42541, 1918, 2008, 2088, 954, 1183, 93, 95, 67]
pie.use_theme('dark')
pie.add('公司类型', attr, v1, is_label_show=True)
pie.render('pie.html')
条形图:》》
扫描二维码关注公众号,回复:
4555990 查看本文章

from pyecharts import Bar
import pymysql
con = pymysql.connect(
host="127.0.0.1",
port=3306,
user="root",
password="12345678",
db='mysql',
)
k = []
o = []
cursor = con.cursor(pymysql.cursors.DictCursor)
u = cursor.execute('''select salary from fangyuan ''')
a = cursor.fetchall()
for y in a:
if y['salary'] not in k:
k.append(y["salary"])
for h in k:
r = cursor.execute('select salary from fangyuan where salary="%s"' %h)
o.append(r)
for n in o[:20]:
print(n)
for m in k[:20]:
print(m)
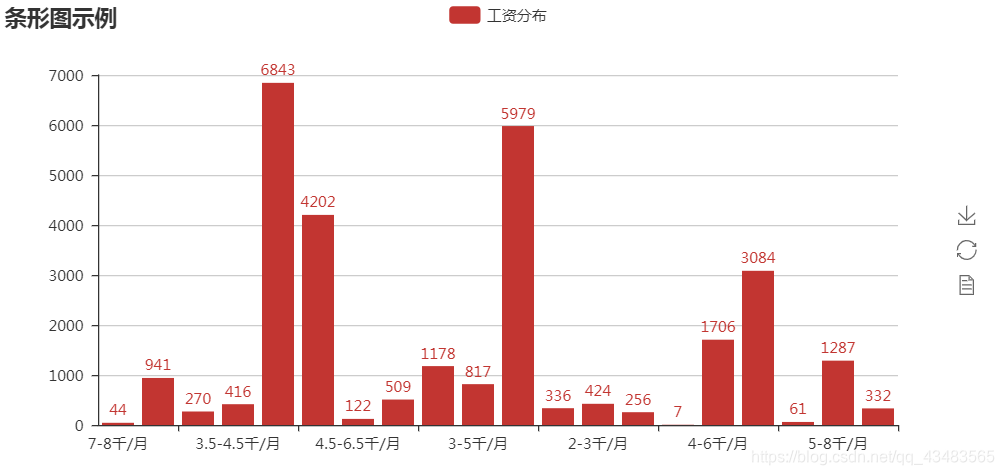
v1 = [941, 270, 416, 6843, 4202, 122, 509, 1178, 817, 5979, 336, 256, 1706, 3084, 1287, 332]
attr = [ '0.8-1.5万/月', '0.7-1万/月', '3.5-4.5千/月', '6-8千/月', '3-4.5千/月', '4.5-6.5千/月', '3.5-5千/月', '0.6-1万/月', '3-5千/月', '4.5-6千/月', '3.5-6千/月', '8-10万/年', '4-6千/月', '1-1.5万/月', '5-8千/月', '3-8千/月']
bar = Bar('各行业薪资水平')
bar.use_theme('dark')
bar.add('工资分布', is_label_show=True)
bar.render('bar.html')
 选取了一部分数据进行分析,还有要改善的地方
选取了一部分数据进行分析,还有要改善的地方
最后再来张词云图:》》
import jieba
from wordcloud import WordCloud
from matplotlib import pyplot as plt
from PIL import Image
import numpy as np
with open(r'C:\Users\hc\Desktop\fangyuan.txt', 'r', encoding="UTF-8") as file1:
content = "".join(file1.readlines())
content_after = "".join(jieba.cut(content, cut_all=True))
# 添加的代码,把刚刚你保存好的图片用Image方法打开,
# 然后用numpy转换了一下
images = Image.open("hello.jpg")
maskImages = np.array(images)
# 修改了一下wordCloud参数,就是把这些数据整理成一个形状,
# 具体的形状会适应你的图片的.
wc = WordCloud(font_path="C:\Windows\Fonts\simsun.ttc",background_color="black",max_words=1000,max_font_size=100,width=1500,height=1500, mask=maskImages).generate(content)
plt.imshow(wc)
wc.to_file('cyt.png')

啦啦啦啦阿拉啦啦啦啦。。。。。。。。。。。
就这样,还有好多要完善的地方,希望各位大佬给点建议!
。。。。。。。。
顺便再给点鼓励,毕竟路还很长,你的鼓励足以温暖我心!。。。。。。。。。。。。。。