线性回归算法梳理
一、机器学习相关概念
1、有监督学习与无监督学习
(1)有监督学习的数据具备特征(features)与预测目标(label),有监督学习同时拥有输入变量x和输出变量y。用一个算法把输入到输出的映射关系——y=f(x)学习出来,当拿到新数据x1时就可以用学习到的映射关系得到相应的y1。常见有监督学习算法:回归和分类。如线性回归、朴素贝叶斯分类、逻辑回归、决策树、SVM、KNN属于有监督学习。
(2) 无监督学习的没有预测目标(label),只有输入变量x。无监督学习目的是将训练数据潜在的结构或分布找出来,以便于我们对这些数据有更多了解。KMeans属于无监督学习。
2、过拟合、欠拟合、泛化能力、交叉验证
(1)过拟合是指模型在训练集上表现良好,在测试集上表现不好的情况。过拟合的原因是模型对数据学习的太彻底,以至于噪声数据也学习到了。
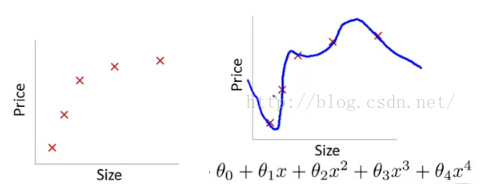
解决方法:
(1.1)重新清洗数据,清洗不纯数据。
(1.2)增大数据的训练量。
(1.3)采用正则化方法。正则化方法包括L0,L1,L2正则,在机器学习中一般用L2正则。
(1.4)采用dropout方法。通常用在神经网络中,在训练过程中随机丢掉一部分神经元。
(1.5)交叉验证法。
(2)欠拟合是指模型在训练集和测试集上表现的都不好的情况。欠拟合的原因是模型没有很好的学习数据特点,以至于不能很好地拟合。
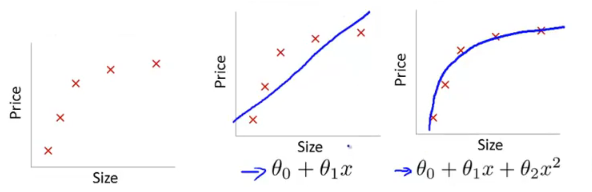
解决方法:
(2.1)添加其他特征项。
(2.2)添加多项式特征,例如将线性模型通过添加二次项或者三次项使模型泛化能力更强。如上图中就是通过增加二次项解决欠拟合问题。
(2.3)减少正则化参数。
(3) 泛化能力是指学习到的模型对未知数据的预测能力,也可以理解为迁移能力。通过测试误差来评价泛化能力。其中过拟合和欠拟合就是机器学习泛化能力弱的两大原因。
(4)交叉验证其基本思想就是将原始数据(dataset)进行分组,一部分做为训练集来训练模型,另一部分做为测试集来评价模型。交叉验证用于评估模型的预测性能,一定程度上减少过拟合。主要方法有:留出法、k折验证法。
二、线性回归原理
(1)线性回归模型:利用线性函数对一个或多个自变量(x或(x1,x2,…,xk))和因变量(y)之间的关系进行拟合的模型。回归分析用来建立方程模拟两个或多个变量之间如何关联。
三、线性回归的损失函数、代价函数、目标函数
(1)损失函数:是单个训练集的误差,即真实值和预测值间的差距。
(2)代价函数:整个训练集所有损失之和的平均值。
(3)目标函数:是代价函数加上正则化项。

四、 一元、多元线性回归的参数求解公式推导
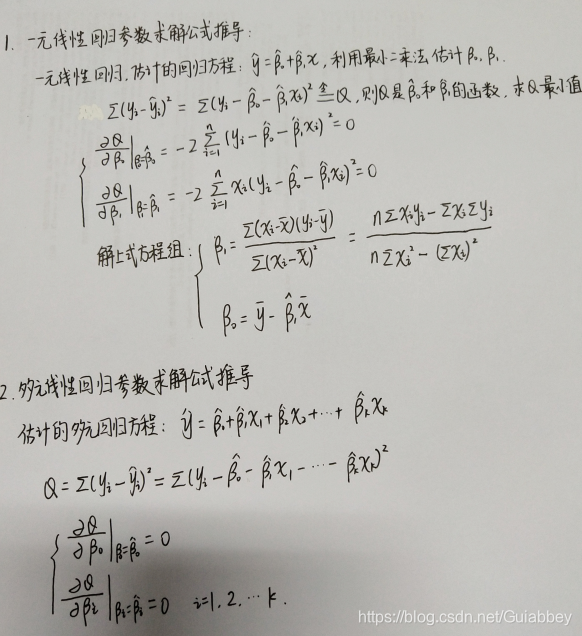
五、线性回归的评估指标及原理
(1)残差平方和(SSE):真实值与预测值之差的平方和。SSE越小越好,越小说明模型拟合越好。
(2) 判定系数(R2):回归平方和占总平方和的比例,等于回归平方和(SSR)/总平方和(SST),又等于1—SSE/SST。判定系数测度了回归直线对观测数据的拟合程度。判定系数越大,说明线性回归方程拟合的越好。
(3)均方误差(MSE)
六、sklearn包线性回归参数详解
LinearRegression(fit_intercept=True,normalize=False,copy_X=True,n_jobs=1)
(1)fit_intercept:是否有截据,如果没有则直线过原点。默认为True.
说明:是否对训练数据进行中心化。如果该变量为false,则表明输入的数据已经进行了中心化,在下面的过程里不进行中心化处理;否则,对输入的训练数据进行中心化处理。
(2)normalize:是否将数据归一化。
(3)copy_X:默认为True,当为True时,X会被copied,否则X将会被覆写.。(即经过中心化,标准化后,是否把新数据覆盖到原数据上)。
(4)n_jobs:默认值为1。计算时使用的核数。