逻辑回归算法梳理
逻辑回归与线性回归算法
分析LR原理之前,先分析一下线性回归。线性回归能将输入数据通过对各个维度的特征分配不同的权重来进行表征,使得所有特征协同作出最后的决策。但是,这种表征方式是对模型的一个拟合结果,不能直接用于分类。
在LR中,将线性回归的结果通过sigmod函数映射到0到1之间,映射的结果刚好可以看做是数据样本点属于某一类的概率,如果结果越接近0或者1,说明分类结果的可信度越高。这样做不仅应用了线性回归的优势来完成分类任务,而且分类的结果是0~1之间的概率,可以据此对数据分类的结果进行打分。对于线性不可分的数据,可以对非线性函数进行线性加权,得到一个不是超平面的分割面
https://blog.csdn.net/touch_dream/article/details/79371462
1线性回归
线性回归一般用于预测连续值变量,如房价预测问题。
线性回归的一般表达式为:
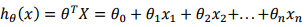
代价函数为MSE(均方误差):
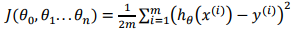
其中权重theta的更新,一般可选用梯度下降等相关优化方法。由于MSE对特征值的范围比较敏感,一般情况下对会对特征进行归一化处理。
具体线性回归相关内容见我的上一篇博客https://blog.csdn.net/wehung/article/details/88899615
2 逻辑回归
逻辑回归虽然叫做回归,但是其主要解决分类问题。可用于二分类,也可以用于多分类问题。
由于线性回归其预测值为连续变量,其预测值在整个实数域中。
而对于预测变量y为离散值时候,可以用逻辑回归算法(Logistic Regression)
逻辑回归的本质是将线性回归进行一个变换,该模型的输出变量范围始终在 0 和 1 之间。
2.1 逻辑回归原理
逻辑回归模型的假设是:
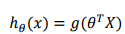
其中,g代表逻辑函数,逻辑函数在逻辑回归中为sigmoid函数,简称S型函数

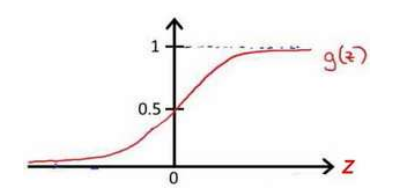

2.2 逻辑回归损失函数
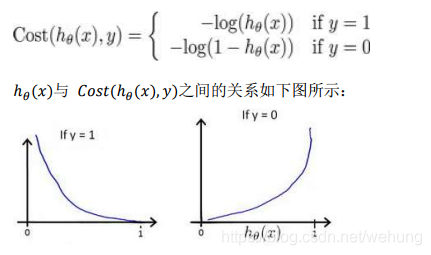
逻辑回归的代价函数为交叉熵函数:
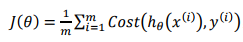
其中,

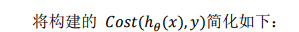
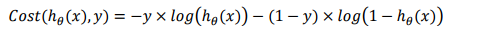
2.3 简化后的逻辑回归损失函数
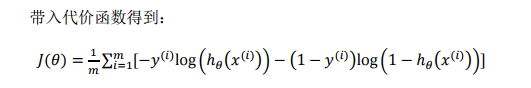
3 联系与区别
综上,联系与区别如下
3.1 联系
- 本质上,逻辑回归就是线性回归再进行了sigmod变换,其值变化到(0,1).
3.2 区别
- 任务定位:线性回归 用于回归任务;逻辑回归用于分类任务
- 输出值: 线性回归输出连续值;逻辑回归输出概率值;本质是因为逻辑回归使用了sigmod函数进行了映射 ,将值域映射到(0,1),在二类任务中,若大于0.5,则为某个类,小于0.5,为另一类。
- 损失函数:线性回归采用MSE损失函数,逻辑回归采用交叉熵损失函数。
损失函数不同的原因:
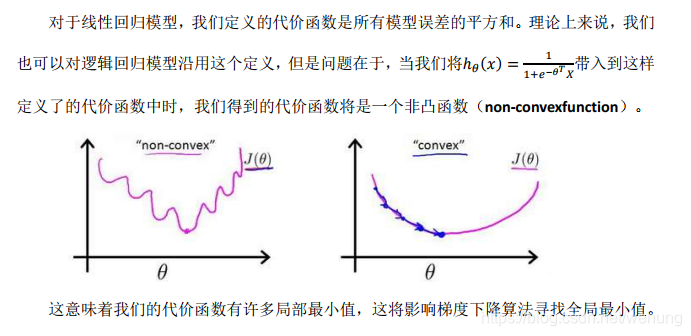
将最后的sigmoid函数输出值与实际值差别用交叉熵函数衡量。相等时候,损失为0,不相等的时候损失很大。见1.2.2图。
4 正则化与模型评估指标
4.1 正则化作用
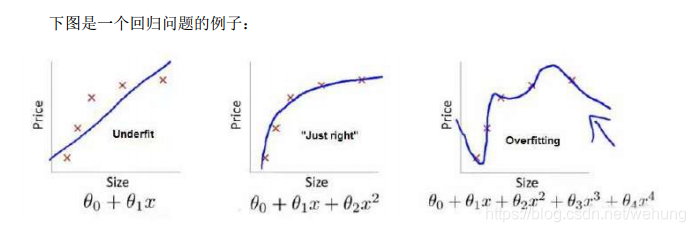
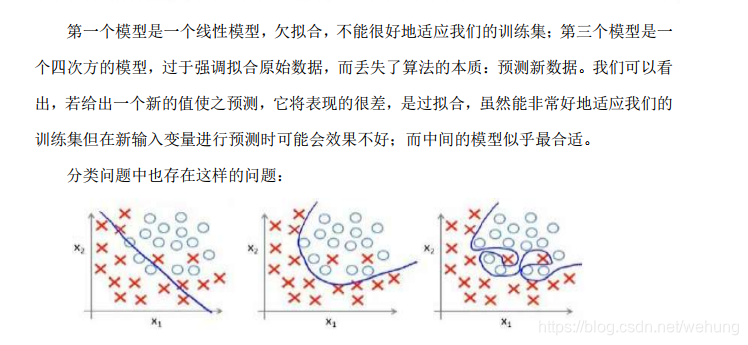




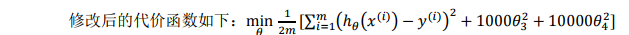

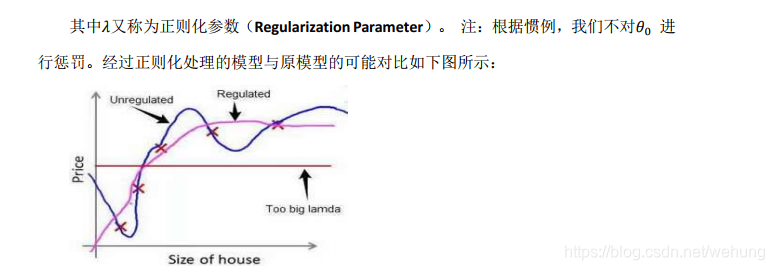



lambda正则化参数 是超参数,一般很难选择,通常使用random search或者Grid Search等方法 进行参数选择。
4.2 线性回归模型正则化
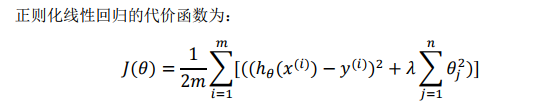

4.3 正则化的逻辑回归模型
代价函数:
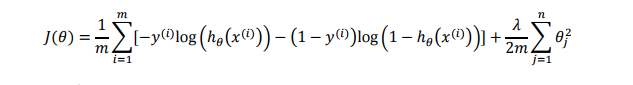

注意:
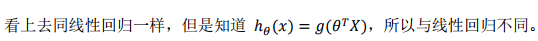
正则化中多了一个sigmoid函数。
5.逻辑回归优缺点
LR是解决工业规模问题最流行的算法。在工业应用上,如果需要分类的数据拥有很多有意义的特征,每个特征都对最后的分类结果有或多或少的影响,那么最简单最有效的办法就是将这些特征线性加权,一起参与到决策过程中。比如预测广告的点击率,从原始数据集中筛选出符合某种要求的有用的子数据集等等。
优点:1)适合需要得到一个分类概率的场景。2)计算代价不高,容易理解实现。LR在时间和内存需求上相当高效。它可以应用于分布式数据,并且还有在线算法实现,用较少的资源处理大型数据。3)LR对于数据中小噪声的鲁棒性很好,并且不会受到轻微的多重共线性的特别影响。(严重的多重共线性则可以使用逻辑回归结合L2正则化来解决,但是若要得到一个简约模型,L2正则化并不是最好的选择,因为它建立的模型涵盖了全部的特征。)
缺点:1)容易欠拟合,分类精度不高。2)数据特征有缺失或者特征空间很大时表现效果并不好。3)不能用 logistic 回归来解决非线性问题,
https://blog.csdn.net/touch_dream/article/details/79371462
6 类别不均衡问题
类别不平衡问题是指分类任务重不同类别的训练样例数目差别很大。
如有998个反例,2个正例。则一个学习模型只需返回反例,则正确率就有99.8%。
西瓜书中提到对本节假设负样本更多,正样本更少:



解决方法:
- 欠采样
- 过采样
- 阈值移动


7.sklearn参数解释
class sklearn.linear_model.LogisticRegression(penalty=’l2’, dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver=’warn’, max_iter=100, multi_class=’warn’, verbose=0, warm_start=False, n_jobs=None)
Logistic回归(aka logit,MaxEnt)分类器。
在多类情况下,如果’multi_class’选项设置为’ovr’,则训练算法使用one-vs-rest(OvR)方案,如果’multi_class’选项设置为’multincial’,则使用交叉熵丢失”。 (目前’‘多项’选项仅受’lbfgs’,'sag’和’newton-cg’解算器的支持。)
该类使用’liblinear’库,‘newton-cg’,'sag’和’lbfgs’求解器实现正则化逻辑回归。 它可以处理密集和稀疏输入。 使用包含64位浮点数的C有序数组或CSR矩阵以获得最佳性能; 任何其他输入格式将被转换(和复制)。
‘newton-cg’,'sag’和’lbfgs’求解器仅支持使用原始公式的L2正则化。 'liblinear’求解器支持L1和L2正则化,具有仅针对L2惩罚的双重公式。
penalty : str, ‘l1’ or ‘l2’, default: ‘l2’
惩罚项:字符型 'l1’正则化或者’l2’正则化,默认‘’l2’
dual : bool, default: False
对偶:布尔值,默认False
Dual or primal formulation. Dual formulation is only implemented for l2 penalty with liblinear solver. Prefer dual=False when n_samples > n_features.
双重或原始配方。 使用liblinear解算器,双重公式仅实现l2惩罚。 当n_samples> n_features时,首选dual = False。
tol : float, default: 1e-4
Tolerance for stopping criteria.停止参数、
C : float, default: 1.0
C:浮点数。1.0
Inverse of regularization strength; must be a positive float. Like in support vector machines, smaller values specify stronger regularization.
正则项的倒数.必须是正的浮点类型.像SVM一样,C越小则,正则化程度越强
fit_intercept : bool, default: True
fit_intercept:布尔值,默认:True
Specifies if a constant (a.k.a. bias or intercept) should be added to the decision function.
指定常量(偏差或者截距)是否添加到决策函数.
intercept_scaling : float, default 1.
intercept_scaling:float,默认值为1。
仅在使用求解器“liblinear”且self.fit_intercept设置为True时有用。 在这种情况下,x变为[x,self.intercept_scaling],即具有等于intercept_scaling的常数值的“合成”特征被附加到实例矢量。 截距变为intercept_scaling * synthetic_feature_weight。
注意! 合成特征权重与所有其他特征一样经受l1 / l2正则化。 为了减小正则化对合成特征权重(并因此对截距)的影响,必须增加intercept_scaling。
class_weight : dict or ‘balanced’, default: None
class_weight:dict或’balanced’,默认值:无
与{class_label:weight}形式的类相关联的权重。 如果没有给出,所有课程都应该有一个权重。
“平衡”模式使用y的值来自动调整与输入数据中的类频率成反比的权重,如n_samples /(n_classes * np.bincount(y))。
请注意,如果指定了sample_weight,这些权重将与sample_weight(通过fit方法传递)相乘。
版本0.17中的新功能:class_weight =‘balanced’ 意思是所有类权重一样
random_state : int, RandomState instance or None, optional, default: None
random_state:int,RandomState实例或None,可选,默认值:None
伪随机数生成器的种子,用于在混洗数据时使用。 如果是int,则random_state是随机数生成器使用的种子; 如果是RandomState实例,则random_state是随机数生成器; 如果为None,则随机数生成器是np.random使用的RandomState实例。 在求解器=='sag’或’liblinear’时使用。
solver : str, {‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’, ‘saga’}, default: ‘liblinear’.
求解器:str,{‘newton-cg’,‘lbfgs’,‘liblinear’,‘sag’,‘saga’},默认:‘liblinear’。
用于优化问题的算法。
对于小数据集,'liblinear’是一个不错的选择,而’sag’和’saga’对于大数据集来说更快。
对于多类问题,只有’newton-cg’,‘sag’,‘saga’和’lbfgs’处理多项式损失; 'liblinear’仅限于一对一其他方案。
‘newton-cg’,‘lbfgs’和’sag’只处理L2惩罚,而’liblinear’和’saga’处理L1惩罚。
请注意,“sag”和“saga”快速收敛仅在具有大致相同比例的要素上得到保证。 您可以使用sklearn.preprocessing中的缩放器预处理数据。
版本0.17中的新功能:随机平均梯度下降求解器。
版本0.19中的新功能:SAGA求解器。
版本0.20更改:默认值将在0.22中从’liblinear’更改为’lbfgs’。
max_iter : int, default: 100
Useful only for the newton-cg, sag and lbfgs solvers. Maximum number of iterations taken for the solvers to converge.
max_iter:int,默认值:100
仅适用于newton-cg,sag和lbfgs求解器。 求解器收敛的最大迭代次数。
multi_class:str,{‘ovr’,‘multinomial’,‘auto’},默认值:‘ovr’
如果选择的选项是’ovr’,那么二进制问题适合每个标签。 对于“多项式”,最小化的损失是整个概率分布中的多项式损失拟合,即使数据是二进制的。 当solver ='liblinear’时,‘multinomial’不可用。 如果数据是二进制的,或者如果solver =‘liblinear’,‘auto’选择’ovr’,否则选择’multinomial’。
版本0.18中的新功能:用于“多项式”情况的随机平均梯度下降求解器。
版本0.20更改:默认值将在0.22中从“ovr”更改为“auto”。
verbose:int,默认值:0
对于liblinear和lbfgs求解器,将详细设置为任何正数以表示详细程度。
warm_start:bool,默认值:False
设置为True时,重用上一次调用的解决方案以适合初始化,否则,只需擦除以前的解决方案。 对于liblinear解算器没用。 请参阅词汇表。
版本0.17中的新功能:warm_start支持lbfgs,newton-cg,sag,saga求解器。
b_jobs:CPU个数。
如果multi_class =‘ovr’“,则在对类进行并行化时使用的CPU核心数。 无论是否指定了“multi_class”,当求解器设置为“liblinear”时,都会忽略此参数。 除非在joblib.parallel_backend上下文中,否则表示1。 -1表示使用所有处理器。 有关详细信息,请参阅词汇表。
参考资料:
1 机器学习 周志华老师
2 机器学习 coursera Andrew Ng
3 博客中所附链接https://blog.csdn.net/touch_dream/article/details/79371462