先引入两个公式勾起大家的回忆
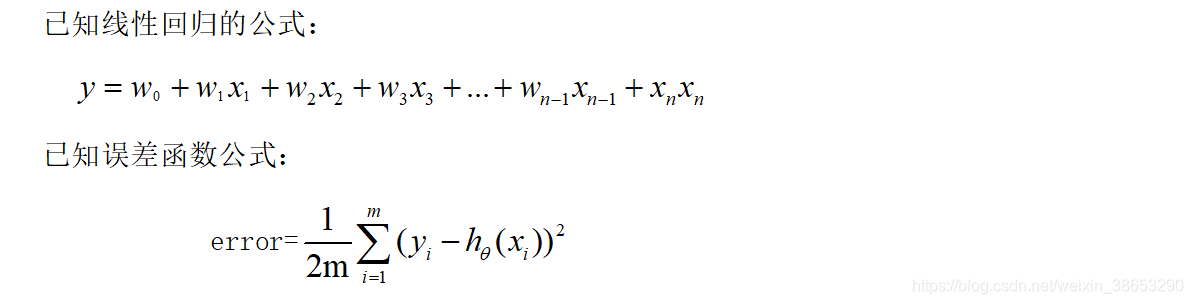
import org.apache.log4j.{Level, Logger}
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.regression.{LabeledPoint, LinearRegressionWithSGD}
import org.apache.spark.{SparkConf, SparkContext}
object LinearRegressionExample01{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("LinearRegressionWithSGD").setMaster("local")
val sc = new SparkContext(conf)
Logger.getRootLogger.setLevel(Level.WARN)
// sc.setLogLevel("WARN")
//读取样本数据
val data_path1 = "lpsa.data"
val data = sc.textFile(data_path1)
val examples = data.map { line =>
val parts = line.split(',')
val y = parts(0)
val xs = parts(1)
//构建有监督模型训练集(即有y值的训练集)
LabeledPoint(parts(0).toDouble, Vectors.dense(parts(1).split(' ').map(_.toDouble)))
}.cache()
//训练集0.8与测试集0.2
val train2TestData = examples.randomSplit(Array(0.8, 0.2), 1)
/*
* 迭代次数
* 训练一个多元线性回归模型收敛(停止迭代)条件:
* 1、error值小于用户指定的error值
* 2、达到一定的迭代次数
*/
val numIterations = 100 //迭代次数
//在每次迭代的过程中 梯度下降算法的下降步长大小 0.1 0.2 0.3 0.4
val stepSize = 1
// 设置为1意思是80%的训练集即全部的训练集都要参与计算error
val miniBatchFraction = 1
val lrs = new LinearRegressionWithSGD()
//让训练出来的模型有w0参数,就是有截距
lrs.setIntercept(true)
//设置步长
lrs.optimizer.setStepSize(stepSize)
//设置迭代次数
lrs.optimizer.setNumIterations(numIterations)
//每一次下山后,是否计算所有样本的误差值,1代表所有样本,默认就是1.0
lrs.optimizer.setMiniBatchFraction(miniBatchFraction)
val model = lrs.run(train2TestData(0)) //拿到0.8的训练集
println(model.weights) //权重
println(model.intercept) //截距
// 对样本进行测试 train2TestData(1)是0.2的测试集
val prediction = model.predict(train2TestData(1).map(_.features))
//将真实的y值与预测的y值进行压缩到一起
val predictionAndLabel = prediction.zip(train2TestData(1).map(_.label))
val print_predict = predictionAndLabel.take(20)
//循环打印两个预测的y值与真实的y值
println("prediction" + "\t" + "label")
for (i <- 0 to print_predict.length - 1) {
println(print_predict(i)._1 + "\t" + print_predict(i)._2)
}
// 计算测试集平均误差
val loss = predictionAndLabel.map {
case (p, v) =>
val err = p - v
Math.abs(err)
}.reduce(_ + _)
val error = loss / train2TestData(1).count
println(s"Test RMSE = " + error)
// 模型保存
val ModelPath = "model"
model.save(sc, ModelPath)
// val sameModel = LinearRegressionModel.load(sc, ModelPath)
sc.stop()
}
}
结果第一行是对训练集通过线性回归算法得出的权重值 即各w的值
第二行得出直线的截距
下面的是通过测试集数据进行测试直线得到预测值与真实值的对比
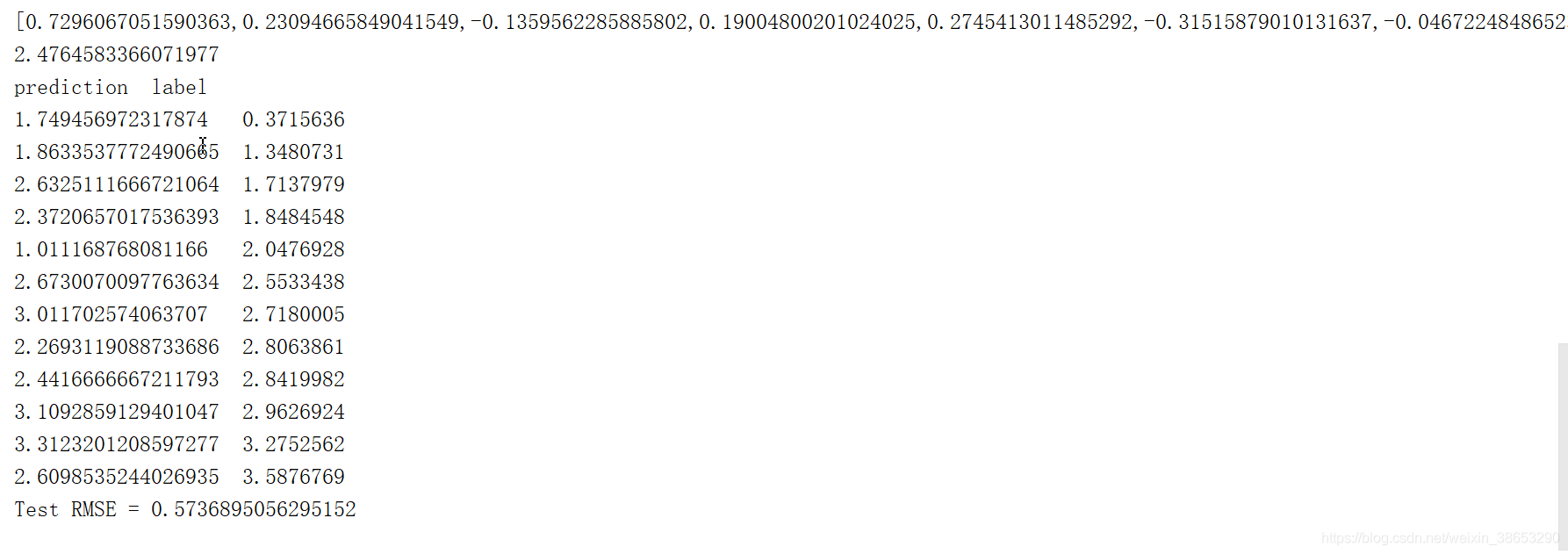
为了使预测的结果更准确 我们可以使用更多的训练集训练,也可以适当调节步长、调节迭代次数、或者使用自己指定的较小的error值