文章目录
- 第二周:优化算法 (Optimization algorithms)
- 2.1 Mini-batch 梯度下降(Mini-batch gradient descent)
- 2.2 理解Mini-batch 梯度下降(Understanding Mini-batch gradient descent)
- 2.3 指数加权平均(Exponentially weighted averages)
- 2.4 理解指数加权平均(Understanding Exponentially weighted averages)
- 2.5 指数加权平均的偏差修正(Bias correction in exponentially weighted averages)
- 2.6 momentum梯度下降(Gradient descent with momentum)
- 2.7 RMSprop——root mean square prop(RMSprop)
- 2.8 Adam优化算法(Adam optimization algorithm)
- 2.9 学习率衰减(Learning rate decay)
- 2.10 局部最优问题(The problem of local optima)
注:图片来自网络
第二周:优化算法 (Optimization algorithms)
2.1 Mini-batch 梯度下降(Mini-batch gradient descent)
向量化能够让你相对较快地处理所有个样本。如果m很大的话,处理速度仍然缓慢。比如说,如果m是500万或5000万或者更大的一个数,在对整个训练集执行梯度下降法时,你要做的是,你必须处理整个训练集,然后才能进行一步梯度下降法,然后你需要再重新处理500万个训练样本,才能进行下一步梯度下降法。所以如果你在处理完整个500万个样本的训练集之前,先让梯度下降法处理一部分,你的算法速度会更快。

X{t}:第t个子集
Y{t}:第t个子集


优点:使用batch梯度下降法,一次遍历训练集只能让你做一个梯度下降,使用mini-batch梯度下降法,一次遍历训练集(1epoch),能让你做5000个梯度下降
2.2 理解Mini-batch 梯度下降(Understanding Mini-batch gradient descent)
代价函数J:

1.使用batch梯度下降法时,每次迭代你都需要历遍整个训练集,可以预期每次迭代成本都会下降,J会随着每次迭代而减少。
2.使用mini-batch梯度下降法,如果你作出成本函数在整个过程中的图,则并不是每次迭代都是下降的,特别是在每次迭代中,你要处理的是X{t}和Y{t},如果要作出成本函数J{t}的图,而J{t}只和X{t},Y{t}有关,也就是每次迭代下你都在训练不同的样本集或者说训练不同的mini-batch,如果你要作出成本函数的图,你很可能会看到这样的结果,走向朝下,但有更多的噪声。
选择mini-batch的大小:
mini-batch=1:随机梯度下降法(紫色)
1.任取起始点,每次迭代,你只对一个样本进行梯度下降,大部分时候你向着全局最小值靠近,有时候你会远离最小值,因此有很多噪声,随机梯度下降法永远不会收敛,而是会一直在最小值附近波动,但它并不会在达到最小值并停留在此
2.你会失去所有向量化带来的加速,因为一次性只处理了一个训练样本,这样效率过于低下
3.如果只要处理一个样本,那这个方法很好,这样做没有问题,通过减小学习率,噪声会被改善或有所减小
mini-batch=m:batch梯度下降法(蓝色)
1.任取起始点,相对噪声低些,幅度也大一些
2.每个迭代需要处理大量训练样本,当训练样本数量巨大时,单次迭代耗时太长
3.如果训练样本不大(2000),batch梯度下降法运行地很好。
mini-batch在1-m之间:(绿色)
1.它不会总朝向最小值靠近,但它比随机梯度下降要更持续地靠近最小值的方向,它也不一定在很小的范围内收敛或者波动,如果出现这个问题,可以慢慢减少学习率。
2.把mini-batch大小设成2的次方64到512的mini-batch比较常见。
3.一方面,你得到了大量向量化,比你一次性处理多个样本快得多。另一方面,你不需要等待整个训练集被处理完就可以开始进行后续工作。

2.3 指数加权平均(Exponentially weighted averages)

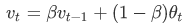
θ:当日温度数据
v:移动平均值

β高时: 曲线要平坦一些,原因在于你多平均了几天的温度,所以这个曲线,波动更小,更加平坦。缺点是曲线进一步右移,因为现在平均的温度值更多,要平均更多的值,指数加权平均公式在温度变化时,适应地更缓慢一些,所以会出现一定延迟,
β低时: 平均的数据太少,所以得到的曲线有更多的噪声,有可能出现异常值,但是这个曲线能够更快适应温度变化。
指数加权平均数在统计学中被称为指数加权移动平均值,我们就简称为指数加权平均数通过调整这个参数β,可以取得稍微不同的效果,往往中间有某个值效果最好。
2.4 理解指数加权平均(Understanding Exponentially weighted averages)
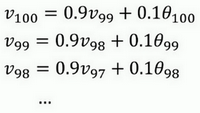
展开得:
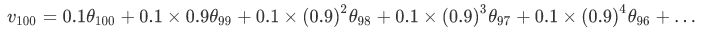
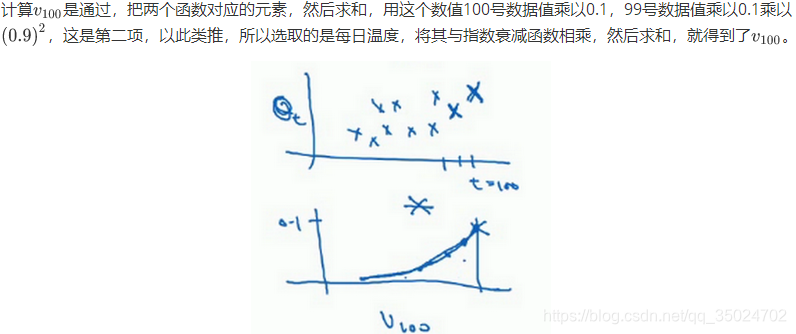
初始化:

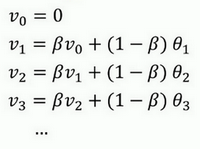
指数加权平均数公式的好处之一在于,它占用极少内存,电脑内存中只占用一行数字而已,然后把最新数据代入公式,不断覆盖就可以了,正因为这个原因,其效率,它基本上只占用一行代码,计算指数加权平均数也只占用单行数字的存储和内存,当然它并不是最好的,也不是最精准的计算平均数的方法。
2.5 指数加权平均的偏差修正(Bias correction in exponentially weighted averages)
如图,红色曲线对应的β=0.9,绿色曲线对应的β=0.98,如果执行原公式,在β等于0.98的时候,得到的并不是绿色曲线,而是紫色曲线

紫色曲线的起点较低,如何处理紫色曲线?


2.6 momentum梯度下降(Gradient descent with momentum)
动量梯度下降法Momentum:运行速度几乎总是快于标准的梯度下降算法,基本的想法就是计算梯度的指数加权平均数,并利用该梯度更新权重。
优化成本函数时,函数形状如图,红点代表最小值的位置,假设你从蓝色点开始梯度下降法,无论是batch或mini-batch下降法,计算下一步梯度下降,然后再计算一步,再一步,计算下去。


超参数: 学习率α以及参数β(0.9)
优点:
在纵轴方向,平均过程中,正负数相互抵消,所以平均值接近于零。
在横轴方向,所有的微分都指向横轴方向,因此横轴方向的平均值仍然较大,因此用算法几次迭代后,你发现动量梯度下降法,最终纵轴方向的摆动变小了,横轴方向运动更快,因此你的算法走了一条更加直接的路径,在抵达最小值的路上减少了摆动。
2.7 RMSprop——root mean square prop(RMSprop)
root mean square prop算法: 加速梯度下降
假设纵轴代表参数b,横轴代表参数W,想减缓纵轴方向的学习,同时加快横轴方向的学习。
在第t次迭代中,该算法会照常计算当下mini-batch的微分dW,db
(为了确保数值稳定,需要在分母上加上一个很小很小的ε,如10^(-8) )
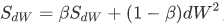
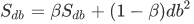
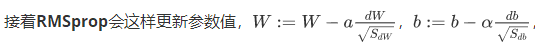
db的平方较大,所以Sdb也会较大,而相比之下,dW平方会小一些,因此会小一些,结果就是纵轴上的更新要被一个较大的数相除,就能消除摆动,而水平方向的更新则被较小的数相除,如下图绿色线

2.8 Adam优化算法(Adam optimization algorithm)
Adam优化算法基本上就是将Momentum和RMSprop结合在一起(可用于梯度下降和批梯度下降)


超参数学习率α很重要,也经常需要调试,你可以尝试一系列值,然后看哪个有效。
β1常用的缺省值为0.9,这是dW的移动平均数(加权平均数),这是Momentum涉及的项。
β2推荐使用0.999,这是在计算以及的移动加权平均值,这是Adam涉及的项
2.9 学习率衰减(Learning rate decay)
学习率衰减: 随时间慢慢减少学习率,可以加快学习算法。
使用固定值α,向这里的最小值下降,但是不会精确地收敛,最后在附近摆动。
慢慢减少学习率α的话,在初期的时候,学习率α还较大,你的学习还是相对较快,但随着变小,你的步伐也会变慢变小,所以最后你的曲线(绿色线)会在最小值附近的一小块区域里摆动。

第一次遍历训练集叫做第一代,第二次就是第二代,依此类推,你可以将学习率设为
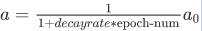
其中,decay-rate为衰减率,epoch-num为代数,α0为初始学习率
衰减率decay-rate为超参数。
这个学习率衰减的公式,人们还会用其它的公式:如指数衰减、离散下降、手动衰减等

2.10 局部最优问题(The problem of local optima)
创建一个神经网络时,通常梯度为零的点不是局部最优点,而是鞍点。

平稳段会减缓学习,平稳段是一块区域,其中导数长时间接近于0,如果你在此处,梯度会从曲面从从上向下下降,因为梯度等于或接近0,曲面很平坦,你得花上很长时间慢慢抵达平稳段的这个点。Momentum或是RMSprop,Adam这样的算法,能够加速学习算法。在这些情况下,更成熟的优化算法,如Adam算法,能够加快速度,让你尽早往下走出平稳段。

