文章目录
- 第三周超参数调试,batch正则化和程序框架(Hyperparameter tuning, Batch Normalization and Programming Frameworks)
- 3.1 调试处理(Tuning process)
- 3.2 为超参数选择和适合范围(Using an appropriate scale to pick hyperparameters)
- 3.3 超参数训练的实践:Pandas vs. Caviar(Hyperparameters tuning in practice: Pandas vs. Caviar)
- 3.4 网络中的正则化激活函数(Normalizing activations in a network)
- 3.5 将 Batch Norm拟合进神经网络(Fitting Batch Norm into a neural network)
- 3.6 为什么Batch Norm奏效?(Why does Batch Norm work?)
- 3.7 测试时的Batch Norm(Batch Norm at test time)
- 3.8 Softmax 回归(Softmax Regression)
- 3.9 训练一个Softmax 分类器(Training a softmax classifier)
- 3.10 深度学习框架(Deep learning frameworks)
- 3.11 TensorFlow(TensorFlow)
注:图片来自网络
第三周超参数调试,batch正则化和程序框架(Hyperparameter tuning, Batch Normalization and Programming Frameworks)
3.1 调试处理(Tuning process)
超参数搜索:

α无疑是最重要的,接下来是橙色圈住的那些,然后是紫色圈住的那些
β1通常设置为0.9,β2为0.999,ε为10^(-8)
随机取值和精确搜索:
随机取值而不是网格取值表明,能探究更多重要超参数的潜在值
当你给超参数取值时,也可以采用由粗糙到精细的策略
3.2 为超参数选择和适合范围(Using an appropriate scale to pick hyperparameters)
随机均匀取值:隐藏单元的数量、神经网络的层数
对数标尺搜索:学习率α,Momentum参数β

如果想要β在0.9到0.999区间搜索,1-β值在0.1到0.001区间内
当β接近1时,所得结果的灵敏度会变化,需要更加密集地取值

3.3 超参数训练的实践:Pandas vs. Caviar(Hyperparameters tuning in practice: Pandas vs. Caviar)
熊猫方式: 你照看一个模型,通常是有庞大的数据组,但没有许多计算资源或足够的CPU和GPU的前提下,基本而言,你只可以一次负担起试验一个模型或一小批模型,在这种情况下,即使当它在试验时,你也可以逐渐改良。观察它的表现,耐心地调试学习率,但那通常是因为你没有足够的计算能力,不能在同一时间试验大量模型时才采取的办法。
鱼子酱方式: 同时试验多种模型,同时你可以开始一个有着不同超参数设定的不同模型,所以,不同模型会产生不同的学习曲线,用这种方式你可以试验许多不同的参数设定,然后只是最后快速选择工作效果最好的那个。
所以这两种方式的选择,是由你拥有的计算资源决定的,如果你拥有足够的计算机去平行试验许多模型,那绝对采用鱼子酱方式,尝试许多不同的超参数,看效果怎么样。

3.4 网络中的正则化激活函数(Normalizing activations in a network)
Batch归一化优点:使你的参数搜索问题变得很容易,使神经网络对超参数的选择更加稳定,超参数的范围会更加庞大,工作效果也很好,也会使训练更加容易。
Batch归一化作用: 使隐藏单元值的均值和方差标准化,即Z[|(i)有固定的均值和方差,均值和方差可以是0和1,也可以是其它值,它是由β和γ两参数控制的。
计算步骤:
1.对于第l层的m个输出z[l(i),本节中简化为z(i),将其化为0均值和标准单位方差的序列

2.赋予新的均值与方差
γ和β是模型需要学习的参数
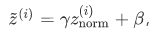

3.替代后,用于后续计算
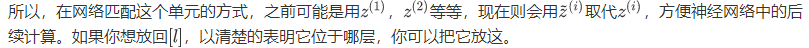
3.5 将 Batch Norm拟合进神经网络(Fitting Batch Norm into a neural network)
Batch 归一化,简称BN
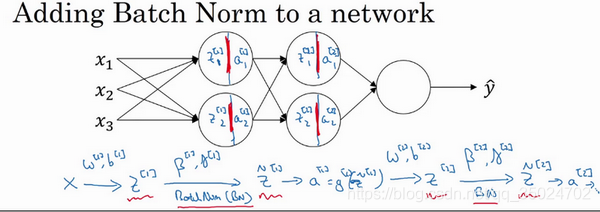
每一层加入新的参数

注:Batch归一化学习参数β[1],β[2]等等和用于Momentum、Adam、RMSprop算法中的β不同。
更新参数β为
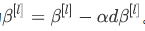
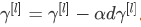
也可以使用Adam或RMSprop或Momentum,以更新参数β和γ,并不是只应用梯度下降法。
Batch 归一化通常和训练集的mini-batch一起使用
维数:β(n[l],1) γ(n[l],1)
3.6 为什么Batch Norm奏效?(Why does Batch Norm work?)
①通过归一化输入特征值,使其均值为0,方差1,可以加速学习
②通过Batch归一化,对于输入值和隐藏单元的值,在做类似的工作,
③使权重比你的网络更滞后或更深层
Covariate shift: 协变量位移
④Batch归一化减少了输入值改变的问题,它的确使这些值变得更稳定,神经网络的之后层就会有更坚实的基础。即使使输入分布改变了一些,它会改变得更少。它做的是当前层保持学习,当改变时,迫使后层适应的程度减小了,你可以这样想,它减弱了前层参数的作用与后层参数的作用之间的联系,它使得网络每层都可以自己学习,稍稍独立于其它层,这有助于加速整个网络的学习。
⑤Batch归一化还有轻微的正则化效果,因为它是用有些噪音的均值和方差(mini-batch)计算得出的。这迫使后部单元不过分依赖任何一个隐藏单元,类似dropout正则化,这是一个神奇的副作用
3.7 测试时的Batch Norm(Batch Norm at test time)
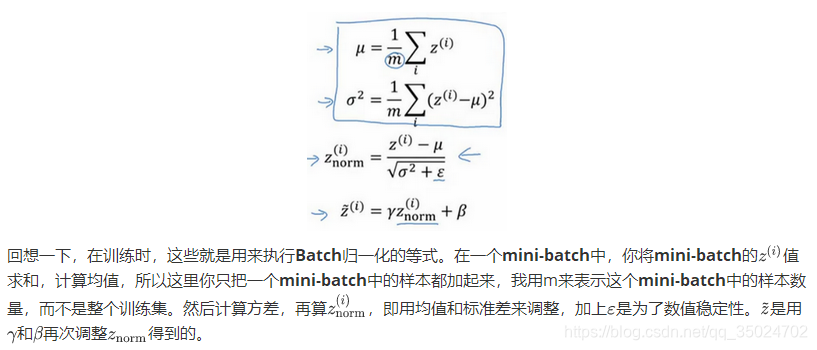
在训练时,μ和σ2是在整个mini-batch 上计算出来的包含了像是64或28或其它一定数量的样本
在测试时,你可能需要逐一处理样本,方法是根据你的训练集估算μ和σ2,估算的方式有很多种,理论上你可以在最终的网络中运行整个训练集来得到μ和σ2,但在实际操作中,我们通常运用指数加权平均 来追踪在训练过程中你看到的μ和σ2的值。然后在测试中使用μ和σ2的值来进行你所需要的隐藏单元值的调整。
3.8 Softmax 回归(Softmax Regression)
C:表示输入会被分入的类别总个数
Softmax层:
在神经网络的最后一层,你将会像往常一样计算各层的线性部分,然后运用Softmax激活函数
简单来说就是将它归一化,使总和为1
适用于多分类任务,不适用与多任务学习

我们的激活函数都是接受单行数值输入,例如Sigmoid和ReLu激活函数,输入一个实数,输出一个实数。Softmax 激活函数的特殊之处在于,因为需要将所有可能的输出归一化,就需要输入一个向量,最后输出一个向量。

3.9 训练一个Softmax 分类器(Training a softmax classifier)
Softmax激活函数:

计算损失函数:
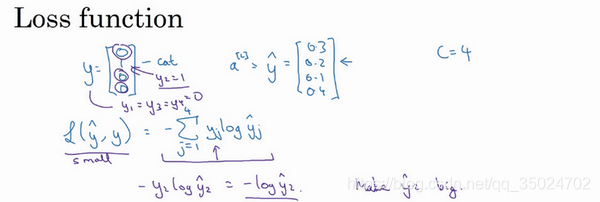
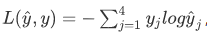
损失函数所做的就是它找到你的训练集中的真实类别,然后试图使该类别相应的概率尽可能地高
计算代价函数:

Softmax输出层的梯度下降法:
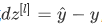
3.10 深度学习框架(Deep learning frameworks)

选择框架的标准:
1.便于编程,这既包括神经网络的开发和迭代,还包括为产品进行配置,为了成千上百万,甚至上亿用户的实际使用,取决于你想要做什么。
2.运行速度,特别是训练大数据集时,一些框架能让你更高效地运行和训练神经网络。
3.这个框架是否真的开放,要是一个框架真的开放,它不仅需要开源,而且需要良好的管理。
3.11 TensorFlow(TensorFlow)
略
