Closed-loop Matters: Dual Regression Networks for Single Image Super-Resolution
这篇博客主要介绍一下DRN,这是2020年最新出来超分辨重建文章。相信大家都阅读过很多超分辨率的文章,都知道超分辨率是一病态的问题。因为在现实生活中一张低分辨率图片产生的方式有很多种,而在我们目前的研究当中,几乎所有的研究人员在训练端对端的深度学习模型时,将HR图片下采样到LR图片都通过特定的方式(比如双三次插值)。而DRN这篇文章就是要解决LR到HR解空间大的问题。
论文地址https://arxiv.org/pdf/2003.07018.pdf
项目地址 https://github.com/fengye-lu/DRN-master
在文章的摘要中指出了以下SR重建存在的两个问题:
第一,学习从LR到HR图像的映射通常是一个不适定问题,因为存在无限多可能的HR图像可以降采样获得相同的LR图像。这会导致LR映射到HR图像的解空间变得极大。因此很难在如此大的空间中学习到好的解决方案,模型性能受到限制。为了提高SR的性能,可以通过增加模型的复杂度来设计有效的模型,例如EDSR,DBPN和RCAN。但是,这些方法仍然存在解空间大的问题,从而导致超分辨性能有限,不会产生细致的纹理(见图1)。因此,如何减少映射函数的解空间以提高SR模型的性能成为了比较重要的问题。第一,学习从LR到HR图像的映射通常是一个不适定问题,因为存在无限多可能的HR图像可以降采样获得相同的LR图像。这会导致LR映射到HR图像的解空间变得极大。因此很难在如此大的空间中学习到好的解决方案,模型性能受到限制。为了提高SR的性能,可以通过增加模型的复杂度来设计有效的模型,例如EDSR,DBPN和RCAN。但是,这些方法仍然存在解空间大的问题,从而导致超分辨性能有限,不会产生细致的纹理(见图1)。因此,如何减少映射函数的解空间以提高SR模型的性能成为了比较重要的问题。
第二,当无法获取配对的数据时,很难获得较好的SR模型。这是由于大多数SR方法都依赖于成对的训练数据,即HR图像及其Bicubic降级后的LR图。但是实际情况是,未配对的数据通常更多。而且,真实世界的数据不一定与通过特定的降采样方法(例如,双三次)获得的LR图像具有相同的分布。因此,能处理实际场景的SR模型是非常具有挑战性的。更关键的是,如果我们将现有的SR模型直接应用于现实世界的数据,它们通常会带来严重的泛化性问题,并产生较差的性能。因此,如何有效利用未配对的数据以使SR模型适应实际应用是一个比较重要的问题。

为解决上述两个问题,作者在摘要后面提到:
建议采取双重措施通过引入一个附加约束的回归方案对LR数据减少可能的空间函数。具体来说,除了LR到HR图像的映射外,我们学习一个额外的双重回归映射估计下采样内核重构LR图像形成一个闭环,提供额外的监督。更多的重要的是,由于二元回归过程并不依赖在HR图像上,我们可以直接从LR图像中学习。在从这个意义上说,我们可以很容易地使SR模型适应现实世界数据,例如来自YouTube的原始视频帧。大量的实验配对训练数据和不配对的现实世界数据表明我们的方法优于现有的方法。
作者的意思就是针对LR到HR解空间大的问题,作者通过设计一个反向的一个网络,实现HR到LR的映射,以此来制约和平衡主网络(也就是LR到HR映射的网络)的训练,怎么平衡的可以通过后面作者给的损失函数看出来。而为了解决HR和LR成对训练的依赖问题,作者通过在训练集中加入不成对的LR图像,那肯定有人要问了,那LR图像没有对应的HR图像那怎么训练呢?这个问题也是能通过后面作者给的损失函数来解决。
论文中给出的概要网络结构:
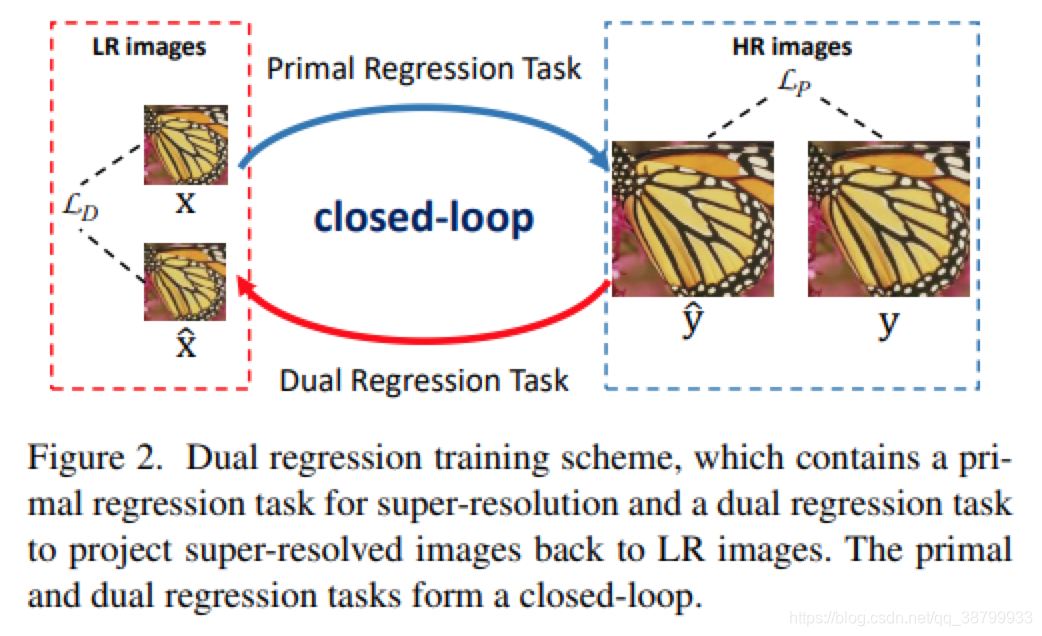
从上面网络结构就能知道,这篇文章的网络结构分为P网络和D网络。
针对配对的训练数据,主要是通过对LR数据引入了一个附加约束,除了学习LR 到HR的映射外,本文还学习了从超分辨图像到LR图像的逆映射。实际上,作者将SR问题公式化为涉及两个回归任务的对偶回归模型。损失函数如下图所示,包含两部分,一个是P网络的损失,一个是D网络的损失,权重推荐设置为0.1。
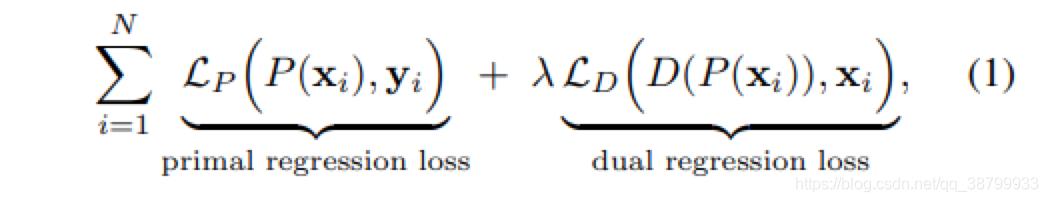
下面重点来了,看懂了下面这个图就能知道作者在源码中是怎么设计训练的了。(注意1sp这个参数)

作者通过1sp这个参数来控制训练LR没有对应HR图像的情况下的训练损失函数,通过后面加上lamda权重的D网络损失函数,来平衡P网络的训练,以此来达到减少LR到HR解空间大的问题。损失函数如下图所示。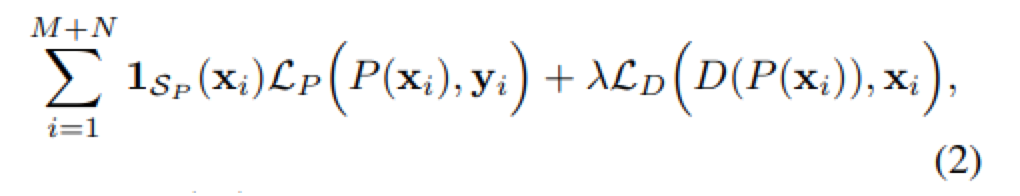
网络的整体结构如下图:
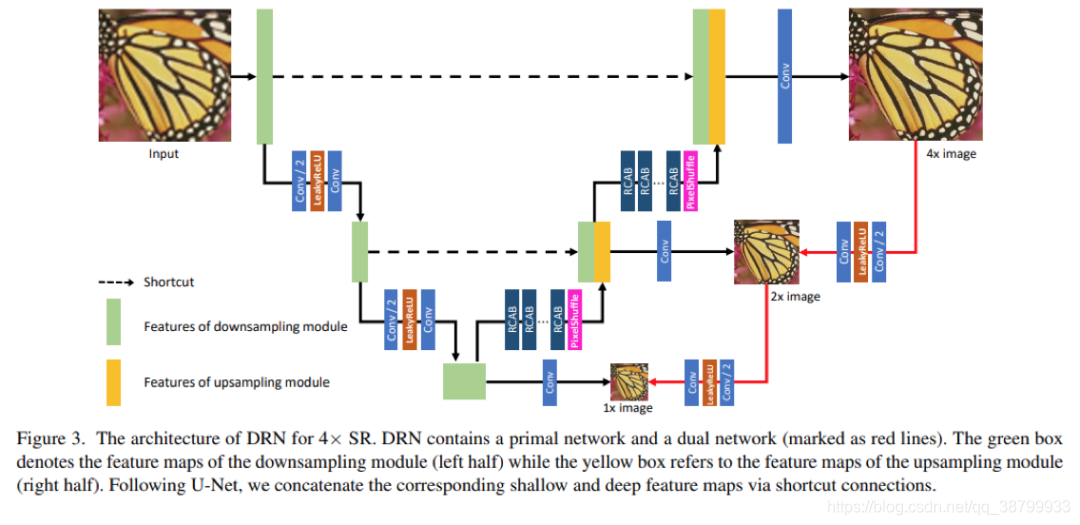
对这个图原论文说的很明白了,不过有一点我要说明白,因为这点我也是通过看源码明白的,论文中没有说明白。
D网络中优化的损失函数不止一个,通过上图可以发现对于最后结果为4x的图像,反向进行下采样可以下采样成2x和1x的。而作者在P网络的设计中一开始Input图像(LR通过插值上采样后的)在输入时也经历了两个阶段就是下采样成2x和1x的,所以这就和D网络对应了起来。P网络的2x和D网络的2x图像形成一对,并进行损失函数优化。1x图像也是如此。如果最后的结果是8x的图像,就多一个4x的P网络和D网络的成对优化。
实验
作者在具有成对的Bicubic数据和不成对的真实数据情况下,对图像超分辨率任务进行了广泛的对比实验。所有实现均是基于PyTorch框架。测试数据集是五个基准数据集,包括SET5,SET14,BSDS100,URBAN100和MANGA109。评价指标是常用的PSNR和SSIM。训练集是DIV2K和Flickr2K数据集。
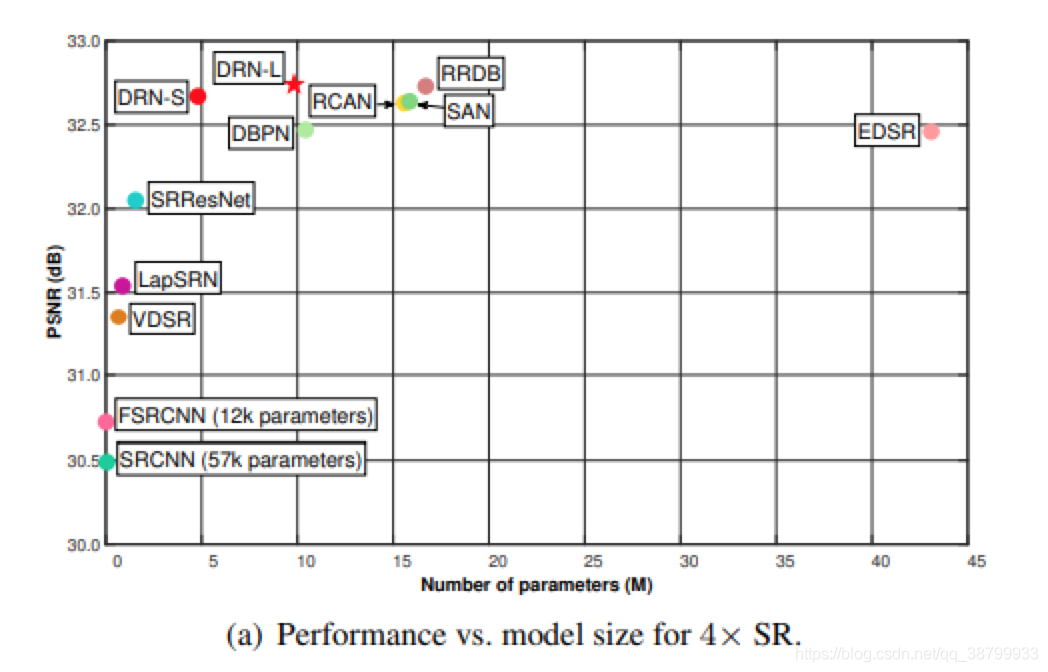
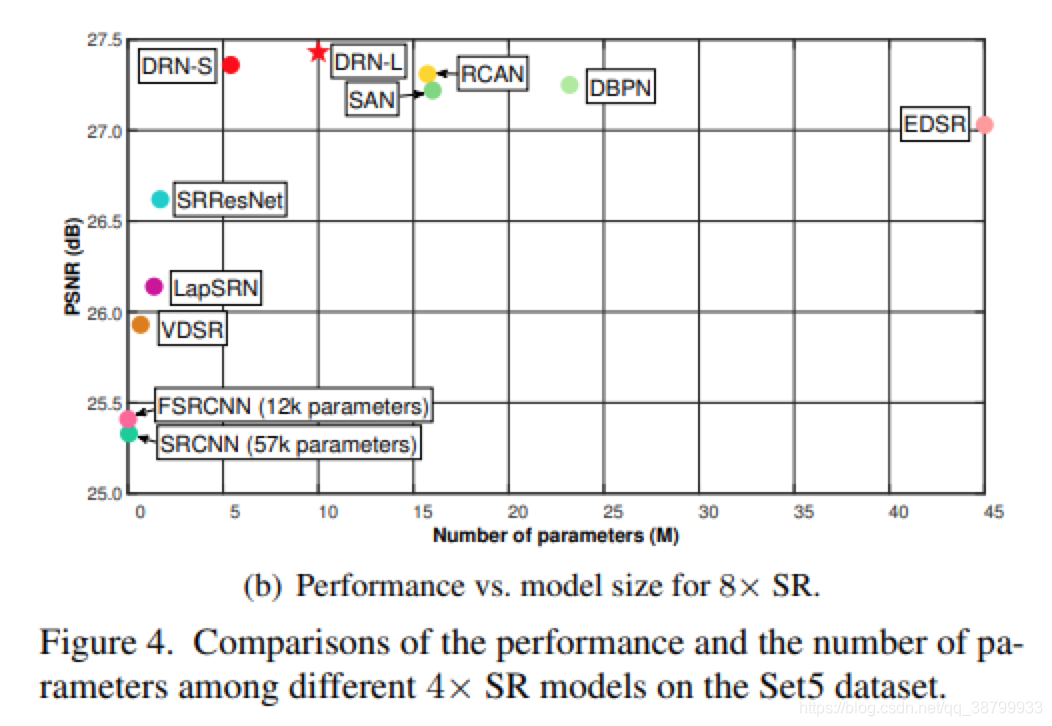
作者首先展示了4x和8x SR的性能和模型大小的比较。在实验中,作者提出了两种模型,即小模型DRN-S和大模型DRN-L。而对比的方法是从它们的预训练模型,开源的代码或是原始论文中获得的结果。结果如下:
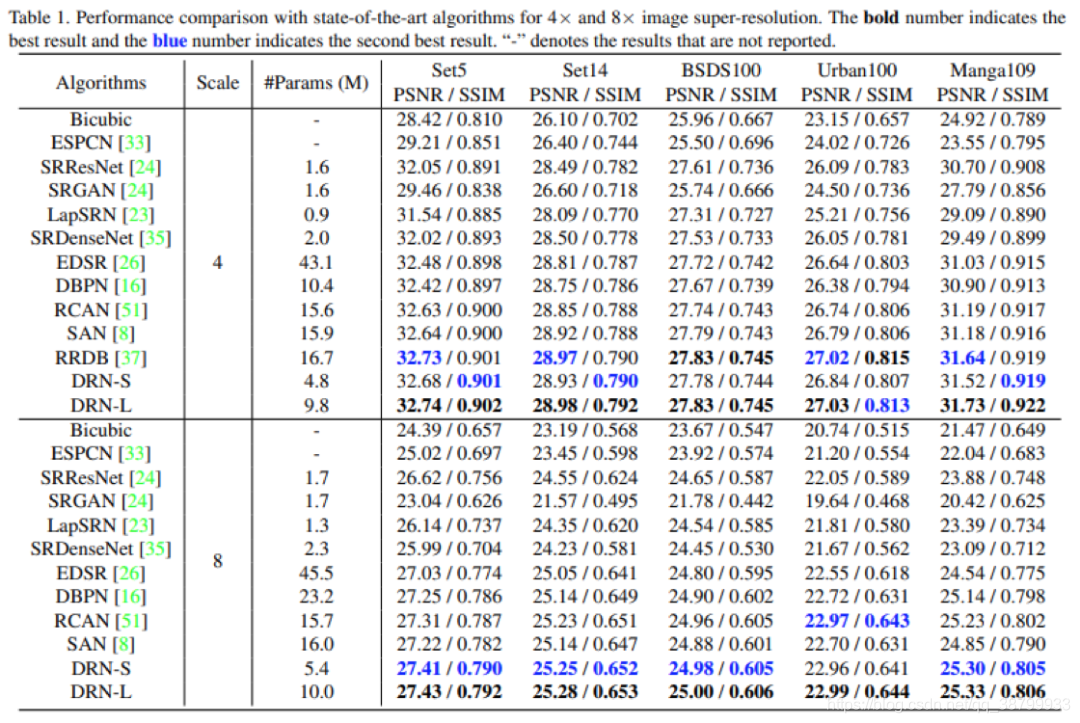

不同分辨率下,各种方法的对比:
最后,作者对比了在真实场景下的重构效果,这里仅展示了视觉上的结果。也对比了使用不同插值方法下的效果,可发现本文的效果均是最优的。

