1、导入包
import requests #取数
from lxml import etree #用xpath解析
import pymysql #连接数据库
import chardet #自动获取编码
2、获取单页html
def get_one_page(url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'}
response = requests.get(url, headers=headers) #习惯先把头部信息加上
response.encoding = chardet.detect(response.content)['encoding'] #用chardet.detect方法自动获取网页的编码,也可以自己手动在网页查
return response.text
3、解析html
def parse_one_page(html):
#对获取内容初始化,再用parse函数etree.HTML解析
result = etree.HTML(html)
item = {} #建立一个字典储存所有职位信息
item['t1'] = result.xpath('//div[@class="el"]/p/span/a/text()') #职位名称
item['t2'] = result.xpath('//div[@class="el"]/span[@class="t2"]/a/text()') #公司名称
item['t3'] = result.xpath('//div[@class="el"]/span[@class="t3"]/text()') #工作地点
t4 = result.xpath('//div[@class="el"]/span[@class="t4"]') #text无法获取空值(薪资数据可能为空),所以要用string方法获取
item['t4'] = []
for i in t4:
item['t4'].append(i.xpath('string(.)')) #遍历出来再用xpath解析,string(.)中间的点表示在当前目录
item['t5'] = result.xpath('//div[@class="el"]/span[@class="t5"]/text()') #发布时间
item['href'] = result.xpath('//div[@class="el"]/p/span/a/@href') #详细链接
4、数据清洗
上面第3步将数取出,存在字典里,接下来做数据清洗,这部分还是在parse_one_page函数体里。
# (1) 去掉每个职位名称前后空白
for i in range(len(item['t1'])): #有多少个职位就遍历多少遍
item['t1'][i] = item['t1'][i].strip() #strip只针对字符串
# (2) 薪资处理
# 定义列表,存储处理后的薪资数据
sal_low = [] #最低月薪
sal_height = [] #最高月薪
for sal in item['t4']: #取出的是字符串
if sal != "": #如果薪资不为空,则先截取
sal = sal.strip().split('-') #将薪资分成两部分
if len(sal) > 1: #若长度>1,则说明薪资是个区间,有最大最小值
#研究薪资结构,一般是万/月,千/月,万/年,其它的设为0值
if sal[1][-3] == '万' and sal[1][-1] == '月': #判断第二部分的构成
sal_low.append(float(sal[0])*10000) #float设置成浮点数
sal_height.append(float(sal[1][0:-3])*10000)
elif sal[1][-3] == '万' and sal[1][-1] == '年':
sal_low.append(round(float(sal[0])*10000/12,1)) #round保留一位小数,月薪=年薪/12
sal_height.append(round(float(sal[1][0:-3])*10000/12,1))
elif sal[1][-3] == '千' and sal[1][-1] == '月':
sal_low.append(float(sal[0])*1000)
sal_height.append(float(sal[1][0:-3])*1000)
else:
sal_low.append(0) #若存在其它情况则全部设为0
sal_height.append(0)
else:
#否则,薪资只有一个固定值
if sal[0][-3] == '元' and sal[0][-1] == '天':
sal_low.append(sal[0][0:-3]) #直接把数字填进去(日薪)
sal_height.append(sal[0][0:-3]) #因为只有一个值,所以最低最高薪资是相同的
else:
sal_low.append(0)
sal_height.append(0)
else: #若为空
sal_low.append(0)
sal_height.append(0)
# 将处理后的薪资存储在字典中
item['sal_low'] = sal_low
item['sal_height'] = sal_height
# (3) 时间数据处理
for i in range(len(item['t5'])):
item['t5'][i] = '2019-' + item['t5'][i] # 遍历出来把每个结果前面都加上年份
yield item
5、存储至mysql
def write_to_mysql(content):
# 建立连接
conn = pymysql.connect(host='localhost',user='root',passwd='vicky',db='test_db',charset='utf8')
cursor = conn.cursor()
for i in range(len(content['t1'])):
# 在这里只取了下面7个字段
jobname = content['t1'][i]
company = content['t2'][i]
workplace = content['t3'][i]
salary_low = content['sal_low'][i]
salary_height = content['sal_height'][i]
ptime = content['t5'][i]
href = content['href'][i]
# 在这一步的时候可以去Navicat创建一张表,字段可以多加一个id为主键自增
sql = "insert into wuyoujob values(null,%s,%s,%s,%s,%s,%s,%s)"
parm = (jobname,company,workplace,salary_low,salary_height,ptime,href)
cursor.execute(sql,parm)
conn.commit()
cursor.close()
conn.close()
5、函数回调
函数写好了,实例化就行
def main(page):
url = 'https://search.51job.com/list/080200,000000,0000,00,9,99,%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590%25E5%25B8%2588,2,'+str(page)+'.html?' #这里要注意,原地址中间?后面的内容都可以删掉,取前面就好,做个分页时注意要转成字符串格式才能拼接
html = get_one_page(url)
for i in parse_one_page(html): #遍历字典
print(i) #打印处理后的数据(字典)也可以不打印
write_to_mysql(i) #把字典的内容传给数据库
郑州不孕不育医院:http://jbk.39.net/yiyuanzaixian/zztjyy//
6、回调主函数,完成分页
if __name__ == '__main__':
for i in range(1,9): #这里看自己抓取的网页大概有多少页
main(i)
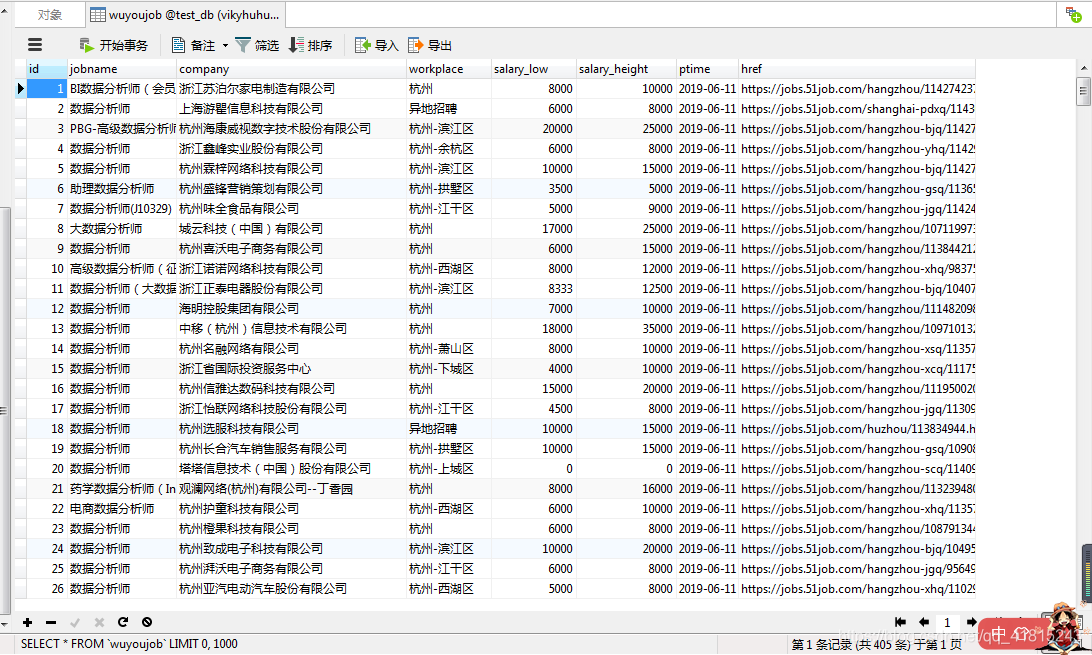
然后打开Navicat,刷新一下表,见证奇迹的时候到了!
dei 没错,我取的是杭州的数据