最近准备考虑找工作,在招聘网站上面看了一下,感觉条目比较多,看得眼花缭乱,于是写了一个爬虫,爬取符合条件的岗位的关键信息。
1、基本原理
- 需求分析
在前程无忧里面输入搜索条件,我输入的岗位是大数据开发工程师,地点是武汉,出现了4页搜索结果:

每一个大概有50条岗位信息,首页展示的只有职位名,公司名,工作地点的部分信息,薪资以及发布日期。对于找工作来说,我希望看到的还有:
公司具体地址: 如果离家太远,上下班会比较花时间。
工作经验要求:判断自身经验是否达到要求
同一个公司职位发布条数:判断是否为虚假招聘,有很多虚假招聘的公司,大量发布类似招聘信息。
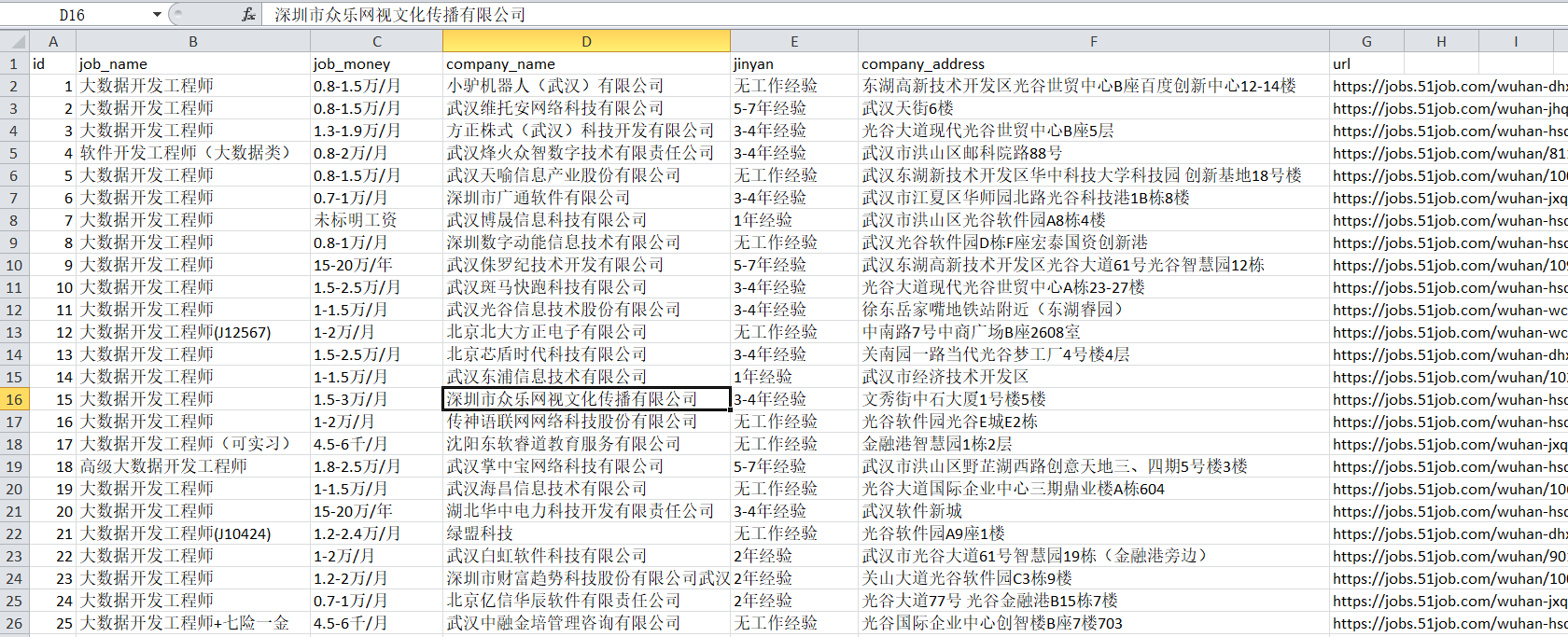
最后,我选择的爬取内容为为:岗位名,公司名,经验要求,公司详细地址,岗位薪资,招聘详细信息页面url。
- 实现过程
本项目中使用了urllib和BeautifulSoup这2个包来处理HTML代码,处理过程如下:
第一步:获取到岗位详情页的url,保存到set中,供下一步遍历使用。
第二步:遍历set中的详情页url,使用BeautifulSoup的select css选择器获取我们需要的字段,将我们需要的字段打包成元组保存到list中。
第三步:将list里面的值保存到MySQL中。
第四步:我把数据导出到了excel里面,进行分析。
2、代码实现
import urllib.request import MySQLdb from bs4 import BeautifulSoup def get_Url_Set(url): index_page = urllib.request.urlopen(url).read().decode('gbk') soup = BeautifulSoup(index_page, features='html.parser') a_list = soup.select("a[href]") url_set = set() i = 0 for item in a_list: href = item["href"] if "wuhan" in href and "https" in href: #print(href) url_set.add(href) return url_set def get_infomation(url_set): job_list = list() for item_url in url_Set: print(item_url) index_page = urllib.request.urlopen(item_url).read().decode('gbk') soup = BeautifulSoup(index_page, features='html.parser') # 获取工作名 job_names = soup.select("h1[title]") job_name = job_names[0]["title"] # 获取工资 moneys = soup.select("div.cn strong") money = moneys[0].string if money is None: money = "未标明工资" # 获取公司名 company_names = soup.select("a.catn") company_name = company_names[0]["title"] # 获取工作经验 jinyans = soup.select("p.msg") list1 = jinyans[0]["title"].split("|") jinyan = list1[1].strip() # 上班地点 address_list = soup.select("p.fp") for item in address_list: if item.span.string == "上班地址:": address = item.contents[2] print(job_name+" "+money+" "+company_name+" "+jinyan+" "+address+" "+item_url) job_list.append((job_name,money,company_name,jinyan,address,item_url)) return job_list def save_jobinfo(job_list): db = MySQLdb.connect("192.168.72.11", "root", "root", "test", charset="utf8") cursor = db.cursor() # 为什么执行 ar_sql = "INSERT INTO `test`.`51job` (`job_name`,`job_money`,`company_name`,`jinyan`,`company_address`,`url`) VALUES(%s,%s,%s,%s,%s,%s)" cursor.executemany(ar_sql, job_list) db.commit() cursor.close() db.close() if __name__ == '__main__': url_1 = "https://search.51job.com/list/180200,000000,0000,00,9,99,%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AE%25E5%25BC%2580%25E5%258F%2591%25E5%25B7%25A5%25E7%25A8%258B%25E5%25B8%2588,2,1.html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=" url_2 = "https://search.51job.com/list/180200,000000,0000,00,9,99,%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AE%25E5%25BC%2580%25E5%258F%2591%25E5%25B7%25A5%25E7%25A8%258B%25E5%25B8%2588,2,2.html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=" url_3 = "https://search.51job.com/list/180200,000000,0000,00,9,99,%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AE%25E5%25BC%2580%25E5%258F%2591%25E5%25B7%25A5%25E7%25A8%258B%25E5%25B8%2588,2,3.html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=" url_4 = "https://search.51job.com/list/180200,000000,0000,00,9,99,%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AE%25E5%25BC%2580%25E5%258F%2591%25E5%25B7%25A5%25E7%25A8%258B%25E5%25B8%2588,2,4.html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=" url_list=list() url_list.append(url_1) url_list.append(url_2) url_list.append(url_3) url_list.append(url_4) for item in url_list: url_Set = get_Url_Set(item) jobinfo_list = get_infomation(url_Set) save_jobinfo(jobinfo_list)
3、结果展示

导出到excel中,如下:
4、总结
由于时间比较仓促,代码还有很多不足,代码中也有很多地方是写死的,复用不够灵活,仅供参考。