讲下爬前程的思路吧:
1.首先最先想到的就是在下图页面,通过response去获定位Xpath路径来得到值
2.当我去获取class=‘e’ 对应的值发现不是我想要的,往class='t’下方的span时取不到值,返回空列表

3. 这时在网页上右键查看源码,发现class=‘e’得到的值在这,继续往下看发现我们想要的值在javascript中


4.我尝试的点击了第二页获取请求的地址,想尝试的能否获取一个纯json的网址,发现进到的还是第二页的主界面,并没有网址中包含纯json的文本


4. 那就只能想办法从前面的网页源码中获取内容了,这也是前程的反爬措施,想了挺久的,知道怎么去实现苦于没有方法,后面看到一位博主的方法存html文件,利用正则去匹配我们想要的内容,我们想要的内容其实是一串json赋予了一个变量window.SEARCH_RESULT 。利用json的方法将字符串转成字典。后续的操作就容易多了
5. 在页面上我们可以获取到详细信息的url值

6. 然后通过scrapy.Request 中callback,利用新定义的方法请求这个url地址去解析响应的文本内容
7. 然后通过父级标签获取子标签的所有内容(找了好久得到了个方法,挺实用的)可以参考父级获取子标签的所有文本内容

9. 最后就是构造下一页的url,实现翻页的功能
之前脑子好像有点不好使一直忘记开管道了,导致一直没有保存数据,所以注意一定要开管道设置
附上代码:
spider主程序的py文件
# -*- coding: utf-8 -*-
import scrapy
import json
import re
from scrapy import *
class Job51Spider(scrapy.Spider):
name = 'Job51'
allowed_domains = ['jobs.51job.com', 'search.51job.com']
url = 'https://search.51job.com/list/040000,000000,0000,00,9,99,java,2,{}.html?'
page = 1
start_urls = [url.format(str(page))]
def parse(self, response):
try:
body = response.body.decode("GBK")
with open("job.html", "w", encoding='utf-8') as f:
f.write(body) # 此处需要拿到网页通过正则匹配
data = re.findall('window.__SEARCH_RESULT__ =(.+)}</script>', str(body))[0] + "}"
data = json.loads(data)
for list in data["engine_search_result"]:
item = {
}
item["name"] = list["company_name"]
item["price"] = list["providesalary_text"]
item["workarea"] = list["workarea_text"]
item["updatedate"] = list["updatedate"]
item["companytype"] = list["companytype_text"]
item["jobwelf"] = list["jobwelf"]
item["companyind"] = list["companyind_text"]
item["href"] = list["job_href"]
# print(type(item["href"]))
detail_url = item["href"]
yield scrapy.Request(
detail_url,
callback=self.parser_detail,
meta={
"item": item}
)
self.page += 1
next_url = self.url.format(str(self.page))
yield scrapy.Request(
next_url,
callback=self.parse
)
except TypeError:
print("爬取结束")
def parser_detail(self,response):
item = response.meta["item"]
welfare = response.xpath("//div[@class='bmsg job_msg inbox']").xpath('string(.)').extract()[0]
item["content"] = welfare
yield item
piplines.py文件
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
from pymongo import MongoClient
client = MongoClient(host="127.0.0.1", port=27017)
collection = client["Job"]["result"]
class JobPipeline(object):
def process_item(self, item, spider):
collection.insert(dict(item))
return item
setting文件(仅开启项)
BOT_NAME = 'Job'
SPIDER_MODULES = ['Job.spiders']
NEWSPIDER_MODULE = 'Job.spiders'
ROBOTSTXT_OBEY = True
COOKIES_ENABLED = False
DEFAULT_REQUEST_HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36',
'Cookie': 'guid=e93e7f6213a66f3dde7a0e1; _ujz=MTY0MTc3NDk3MA%3D%3D; ps=needv%3D0; 51job=cuid%3D164177497%26%7C%26cusername%3Dfuwei_fw123%2540163.com%26%7C%26cpassworB6%25CE%25B0%26%7C%26cemail%3Dfuwei_fw123%2540163.com%26%7'
ITEM_PIPELINES = {
'New.pipelines.NewPipeline': 300,
}
}
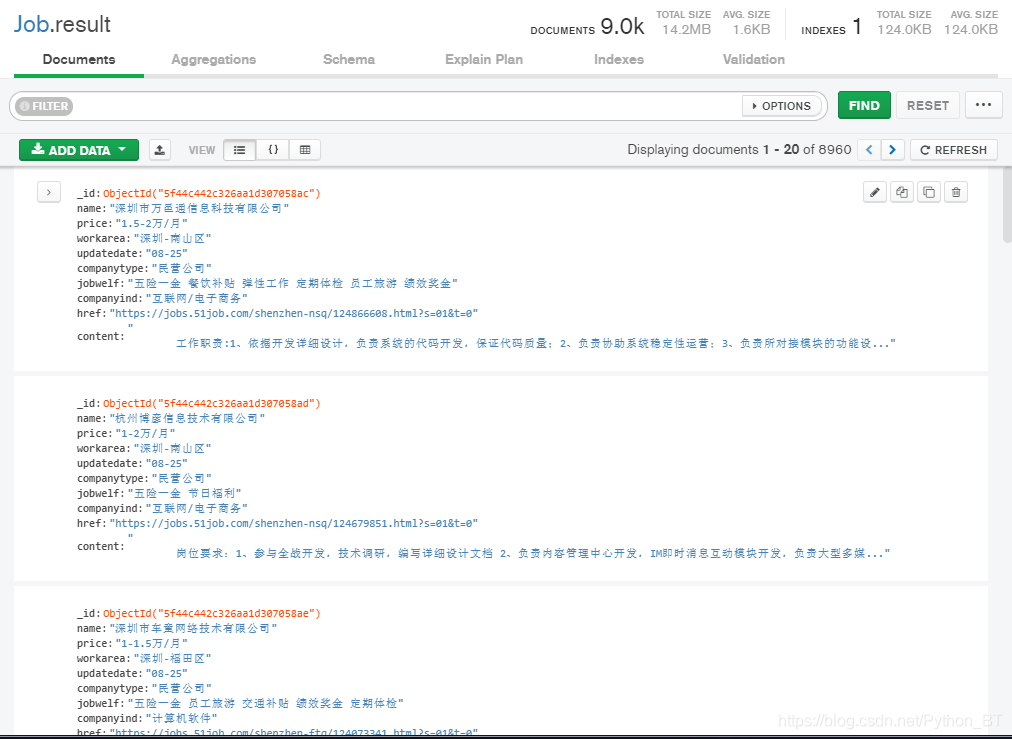
附上mongodb的截图(爬取的速度还是慢了,后续优化为分布式爬虫)