说明:笔记旨在整理我校CS181课程的基本概念(PPT借用了Berkeley CS188)。由于授课及考试语言为英文,故英文出没可能。
目录
1 Markov Decision Processes mechanics
1.1 Markov Decision definitions
1 Markov Decision Processes mechanics
1.1 Markov Decision definitions
A MDP is defined by:

1.2 Markov 涵义
For markov decision processes, "Markov" means action outcomes depend only on the current state:
1.3 最优策略optimal policy
For MDP, we want an optimal policy :
- A policy π gives an action for each state
- An optimal policy is one that maximizes expected utility if allowed
- An explicity policy defines a reflex agent
1.4 MDP搜索树 MDP search tree

5. Discounting: each time we descend a level, we multiply in the discount once. Redefine Rewards R(s, a, s') with discount γ
2 Solving MDPs
2.1 Optimal Quantities
1. The value (utility) of a state s: =expected utility starting in s and acting optimally.
2. The value (utility) of a q-state (s,a): =expected utility starting out having taken action a from state s and (therefore) acting optimally
3. The optimal policy: =optimal action from state s
2.2 Value of states

2.3 Value iteration
1.Define to be the optimal value of s if the game ends in k more time steps

2.Policy extraction
2.4 Policy iteration
Step1 Policy evaluation:

Step2: Policy improvement: After evaluation(step 1), we get
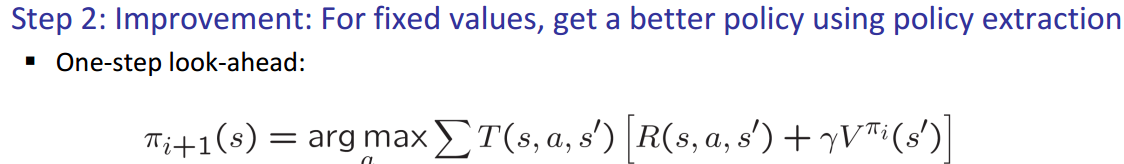
Policy iteration: repeat two steps until policy converges
Reference
1. Artificial Intelligence, A Modern Approach. 3rd Edition. Stuart R., Peter N. Chapter 17
2. UC berkeley, CS188. Lecture 13 Markov Decision Process