- 参考:周博磊老师的教程
1. 马尔可夫链
1.1 马尔可夫性质/无后效性(Markov Property)
-
定义:过程或系统在时刻 t 0 t_0 t0 所处的状态为已知的情况下,在时刻 t > t 0 t>t_0 t>t0 所处状态的条件分布与过程在时刻 t 0 t_0 t0 之前所处的状态无关。通俗的说,就是系统下一步状态仅取决于当前状态,而与历史状态无关
-
形式化定义:
- 定义状态历史: h t = { s 1 , s 2 , s 3 , . . . , s t } h_t = \{s_1,s_2,s_3, ...,s_t\} ht={ s1,s2,s3,...,st}
- 定义马尔科夫性:如果系统满足以下性质,我们称这个系统具有马尔科夫性
P ( s t + 1 ∣ s t ) = P ( s t + 1 ∣ h t ) P ( s t + 1 ∣ s t , a t ) = P ( s t + 1 ∣ h t , a t ) P(s_{t+1}|s_t) = P(s_{t+1}|h_t) \\ P(s_{t+1}|s_t,a_t) = P(s_{t+1}|h_t,a_t) P(st+1∣st)=P(st+1∣ht)P(st+1∣st,at)=P(st+1∣ht,at)
-
需要说明的是,这种性质不是为了简化而简化,而是有一定依据的。比如我们都知道的一个走迷宫技巧:在每个岔路总是选择拐弯(这会执行一个深度优先搜索),把我们所在的不同位置看作不同状态,则每个新状态只与当前状态有关
1.2 马尔可夫过程(Markov Process / MP)
- 定义:具有马尔科夫性的随机过程称为马尔科夫过程
- 马尔科夫过程描述的是系统从一个状态到另一个状态转换的随机过程。该过程要求具备马尔可夫性,也就是下一状态的概率分布只与当前的状态有关,而与时间序列中其他前面的事件无关。
1.3 马尔可夫链(Markov Chain)
-
马尔可夫链描述了一个具有马尔可夫性质的系统的状态转移情况
-
把系统的所有状态画成若干个点,然后用箭头和转移概率把它们连接起来,就得到了这个系统的马尔可夫链
-
示例:下图是一个具有4个状态的系统,状态间以一定的概率转移,且这个概率仅取决于当前状态
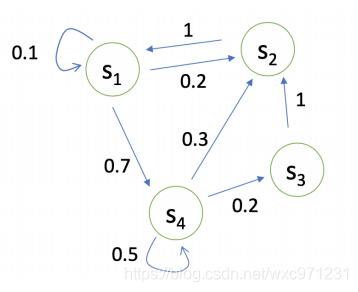
-
形式化描述
-
状态向量: X n = { x 1 n , x 2 n , . . . , x k n } X^n = \{x_1^n,x_2^n,...,x_k^n\} Xn={ x1n,x2n,...,xkn}
- 状态向量描述了第n次观测时,系统可能处于各个状态的概率
- 系统的可能状态数有k个, x 1 n , x 2 n , . . . , x k n x_1^n,x_2^n,...,x_k^n x1n,x2n,...,xkn都是概率,它们的和为1
- X 0 X^0 X0 被称为初始状态
-
状态转移矩阵
-
我们用 P s s ′ P_{ss'} Pss′表示从状态s转移到状态s’的概率,即 P s s ′ = P ( S t + 1 = s ′ ∣ S t = s ) P_{ss'} = P(S_{t+1} = s'|S_t=s) Pss′=P(St+1=s′∣St=s)
-
这样就可以用矩阵的形式表示所有状态的转移概率

称这个矩阵为 “状态转移矩阵” -
注意这个矩阵的行和/列和都是1
-
-
根据无后效性,我们可以得出
X n = X n − 1 P X^{n} = X^{n-1}P Xn=Xn−1P
于是有
X n = X 0 P n X^{n} = X^0P^n Xn=X0Pn
所以只要求出状态转移矩阵P,这个系统(马尔可夫模型)就确定了
-
-
利用马尔可夫链(准确说是利用状态转移矩阵),我们就可以从初始状态预测系统未来任意时刻可能处于的状态概率分布。这个预测本质就是状态转移矩阵的连乘,因此这还涉及一个收敛性的问题,这里不展开讨论,可以参考:数学模型——初步理解马尔可夫链(Markov chain)
2. 马尔可夫奖励过程(MRP)
- 简单看,MRP = Markov chain + reward function
2.1 基础概念
- episode(轨迹):对马尔可夫链采样得到一个状态序列,称为一个轨迹
- Horizon:一个轨迹的最大长度(number of maximum time step),可以是 ∞ \infty ∞,否则称为有限马尔可夫奖励过程
- Return( G t G_t Gt):Horizon中从第 t 步到最后的奖励加权和
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . + γ T − t − 1 R T G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} +...+ \gamma^{T-t-1} R_{T} Gt=Rt+1+γRt+2+γ2Rt+3+...+γT−t−1RT
这里的 γ ∈ [ 0 , 1 ] \gamma \in [0,1] γ∈[0,1] 就是下面MRP定义中的折扣系数。这个return G t G_t Gt 代表着未来可能获取奖励的加权和 - 状态价值函数V(s): V ( S t ) V(S_t) V(St) 代表第 t 步处于状态 s 时的return的期望,即 “未来可能获取奖励的加权和” 的当前期望值
V ( S t ) = V ( s ) = E [ G t ∣ S t = s ] = E [ R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . + + γ T − t − 1 R T ∣ S t = s ] V(S_t) = V(s) = \mathbb{E}[G_t|S_t = s] = \mathbb{E}[R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} +...++ \gamma^{T-t-1} R_{T}|S_t = s] V(St)=V(s)=E[Gt∣St=s]=E[Rt+1+γRt+2+γ2Rt+3+...++γT−t−1RT∣St=s]
V ( s ) V(s) V(s)也常记为 V ( S t ) V(S_t) V(St) 或 V S V_S VS ,这是对MRP中状态的一个评鉴指标。它描述了进入状态s可以获取的 “长期价值” (long-term value),这真正表示了进入状态s有多好
2.2 定义
-
马尔可夫奖励过程MRP是一个四元组 < S , P , R , γ > <S,P,R,\gamma> <S,P,R,γ>
- S:有限状态集
- P:状态转移矩阵,定义了 P s s ′ = P ( S t + 1 = s ′ ∣ S t = s ) P_{ss'} = P(S_{t+1} = s'|S_t=s) Pss′=P(St+1=s′∣St=s)
- R:奖励函数 R ( S t = s ) = E [ R t + 1 ∣ S t = s ] R(S_t = s) = \mathbb{E}[R_{t+1}|S_t = s] R(St=s)=E[Rt+1∣St=s]
- γ \gamma γ:折扣系数, γ ∈ [ 0 , 1 ] \gamma \in [0,1] γ∈[0,1]
-
说明
- 奖励函数 R ( S t = s ) R(S_t = s) R(St=s)定义某时刻t处于状态s下的奖励为:离开t时刻时能获得的奖励的期望。式子里写 R t + 1 R_{t+1} Rt+1而不是 R t R_t Rt 可能会引起困惑,其实这只是一个约定。我们一般倾向于任务离开而非进入 S t S_t St 这个状态时才能获取奖励。可以把 R t + 1 R_{t+1} Rt+1 理解为离开 t t t 时刻时获得的奖励,也可以简单地把 R ( s ) R(s) R(s)理解为进入状态s可以获得的奖励。通常会人为地给 R ( s ) R(s) R(s)设定一个值,所以这个期望一般不用算
- 为什么有折扣系数 γ \gamma γ:
- 避免带环的Markov chain中出现无穷的奖励
- 看上面V(s)的公式,越未来的状态乘上的折扣系数越多,这是对于未来奖励不确定性的体现
- 人和动物的行为中都表现出对即刻奖励的追求, γ \gamma γ 可以模拟这一点,它使模型更看重短期奖励(权重更高)
- 某些情况下也会使用不折价的MRP, γ = 1 \gamma = 1 γ=1 时意味着任意时刻的奖励都同样重要; γ = 0 \gamma = 0 γ=0 时意味只考虑当前奖励
- 折扣系数 γ \gamma γ 一般用作超参数,可以通过调整它获取不同行为的agent
2.3 MRP的示例

2.4 状态价值函数 V 如何计算
2.4.1 蒙特卡洛方法
- 价值函数 V ( s ) = E [ G t ∣ S t = s ] V(s) = \mathbb{E}[G_t|S_t = s] V(s)=E[Gt∣St=s] 就是求 G t G_t Gt 的期望,可以从状态s开始采样多个轨迹,分别计算 G t G_t Gt 然后取均值
- 伪代码如下

2.4.2 利用Bellman等式
- 注意:以下用 S t S_t St 或 s 代表当前时刻 t 的状态, S t + 1 S_{t+1} St+1 或 s’ 代表下一时刻的状态
2.4.2.1 Bellman等式
V ( S t ) = R ( S t ) + γ ∑ S t + 1 ∈ S P ( S t + 1 ∣ S t ) V ( S t + 1 ) V(S_t) =R(S_t) + \gamma \sum\limits_{S_{t+1} \in S} P(S_{t+1} | S_t) V(S_{t+1}) V(St)=R(St)+γSt+1∈S∑P(St+1∣St)V(St+1)
-
这个式子可以分成两部分, R ( S t ) R(S_t) R(St)代表当前状态的立即奖励,后半边可以看做未来奖励的加权和
-
这个式子满足递归特性,即 “这一步的未来奖励期望 = 这一步奖励 + 下一步的未来奖励期望”,可以写成递归矩阵形式
V = R + γ P V V = R + γPV V=R+γPV

-
Bellman等式描述了状态之间的迭代关系,知道了下一步所有可能状态的 V(s’),即可解出当前状态的 V(s)
2.4.2.2 推导
V ( S t ) = E [ G t ∣ S t = s ] = E [ R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . ∣ S t = s ] = E [ R t + 1 + γ ( R t + 2 + γ R t + 3 + . . . ) ∣ S t = s ] = E [ R t + 1 + γ G t + 1 ∣ S t = s ] = E [ R t + 1 + γ V ( S t + 1 ) ∣ S t = s ] = R ( S t ) + γ ∑ S t + 1 ∈ S P ( S t + 1 ∣ S t ) V ( S t + 1 ) \begin{aligned} V(S_t) &= \mathbb{E}[G_t|S_t = s] \\ &= \mathbb{E}[R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} +...|S_t = s] \\ &= \mathbb{E}[R_{t+1} + \gamma (R_{t+2} + \gamma R_{t+3} +...)|S_t = s] \\ &= \mathbb{E}[R_{t+1} + \gamma G_{t+1}|S_t = s] \\ &= \mathbb{E}[R_{t+1} + \gamma V(S_{t+1})|S_t = s] \\ &=R(S_t) + \gamma \sum\limits_{S_{t+1} \in S} P(S_{t+1} | S_t) V(S_{t+1}) \end{aligned} V(St)=E[Gt∣St=s]=E[Rt+1+γRt+2+γ2Rt+3+...∣St=s]=E[Rt+1+γ(Rt+2+γRt+3+...)∣St=s]=E[Rt+1+γGt+1∣St=s]=E[Rt+1+γV(St+1)∣St=s]=R(St)+γSt+1∈S∑P(St+1∣St)V(St+1)
- 注意 R t + 1 R_{t+1} Rt+1代表 t 时刻最后离开状态 S t S_t St时获得的奖励,就是状态 S t S_t St的奖励 R ( S t ) R(S_t) R(St)
2.4.2.3 用Bellman等式解价值函数
-
直接解: V = R + γ P V V = R + γPV V=R+γPV是一个线性方程,可以通过矩阵求逆直接解,即
V = ( 1 − γ P ) ) − 1 R V = (1- γP))^{-1}R V=(1−γP))−1R
但是矩阵求逆的复杂度为 o ( N 3 ) o(N^3) o(N3),所以直接求解的方式仅适用于小规模MRP问题 -
递推方式求解:适用于状态多的MRP问题,常用的方法有3个
-
动态规划(Dynamic Programming)

这个就是不断用Bellman公式进行迭代计算,直到V收敛为止 -
蒙特卡洛(Monte-Carlo evaluation),详见上文
-
TD学习 (Temporal-Difference learning),这可以看作以上两个的结合
-
3. 马尔可夫决策过程(MDP)
- 简单看,MDP = MRP + Policy,MDP是有决策的MRP
3.1 定义
- 马尔可夫决策过程MDP是一个五元组 < S , A , P a , R , γ > <S,A,P^a,R,\gamma> <S,A,Pa,R,γ>
- S:有限状态集
- A:有限动作集
- P a P^a Pa:状态转移矩阵,定义了 P s s ′ = P ( S t + 1 = s ′ ∣ S t = s , A t = a ) P_{ss'} = P(S_{t+1} = s'|S_t=s,A_t =a) Pss′=P(St+1=s′∣St=s,At=a)
- R:奖励函数 R ( S t = s , A t = a ) = E [ R t + 1 ∣ S t = s , A t = a ] R(S_t = s,A_t=a) = \mathbb{E}[R_{t+1}|S_t = s,A_t=a] R(St=s,At=a)=E[Rt+1∣St=s,At=a]
- γ \gamma γ:折扣系数, γ ∈ [ 0 , 1 ] \gamma \in [0,1] γ∈[0,1]
- MDP中的Policy( π \pi π)
- policy指定了某个状态s下该采取的动作a
- 给定一个状态s,Policy给出一个动作的概率分布( distribution over actions)
π ( a ∣ s ) = P ( A t = a ∣ S t = s ) \pi(a|s) = P(A_t=a|S_t=s) π(a∣s)=P(At=a∣St=s) - Policy最终给出的是从状态s的动作分布 π ( a ∣ s ) \pi(a|s) π(a∣s) 上采样的一个action
- Policy是静态的(时间独立),每个时刻的动作 A t A_t At 都是 π ( a ∣ s ) \pi(a|s) π(a∣s)上的一个采样
3.2 MDP和MRP
3.2.1 从MDP转换到MRP
-
给出MDP < S , A , P , R , γ > <S,A,P,R,\gamma> <S,A,P,R,γ> 以及 Policy π \pi π
-
使用S、P 和 π \pi π 可以构造 马尔可夫过程MP: < S , P π > <S,P^{\pi}> <S,Pπ>,这对应一个 “状态序列” S 1 , S 2 , . . . S_1,S_2,... S1,S2,...
-
使用S,P,R, γ \gamma γ 和 π \pi π 可以构造 马尔可夫奖励过程MRP: < S , P π , R π , γ > <S,P^{\pi},R^{\pi},\gamma> <S,Pπ,Rπ,γ>,这里 P π , R π P^{\pi},R^{\pi} Pπ,Rπ都是把某个状态下所有动作做加权和(求期望),从而消除了动作A:
P π ( s ′ ∣ s ) = ∑ a ∈ A π ( a ∣ s ) P ( s ′ ∣ s , a ) R π ( s ) = ∑ a ∈ A π ( a ∣ s ) R ( s , a ) P^{\pi}(s'|s) = \sum\limits_{a \in A}\pi(a|s) P(s'|s,a) \\ R^{\pi}(s) = \sum\limits_{a \in A}\pi(a|s) R(s,a) Pπ(s′∣s)=a∈A∑π(a∣s)P(s′∣s,a)Rπ(s)=a∈A∑π(a∣s)R(s,a)这对应一个 “状态奖励序列” S 0 , R 1 , S 1 , R 2 , . . . S_0,R_1,S_1,R_2,... S0,R1,S1,R2,...
-
MDP本身对应一个 “状态动作奖励序列”: S 0 , A 0 , R 1 , S 1 , A 1 , R 2 , . . . S_0,A_0,R_1,S_1,A_1,R_2,... S0,A0,R1,S1,A1,R2,...
3.2.2 对比MDP和MRP
- 相比MRP,MDP从状态s出发后首先要在动作分布中选一个action a,然后才能得到转移概率P,进而转移到新状态s’。“选action” 这一环就是 “决策”

- 有一个很经典的比喻
- MRP好像一个纸船,在马尔可夫链上的各个状态之间按概率转移矩阵随波逐流
- MDP好像有人在架船,它有Policy,会根据当前的状态采取不同的action,进而影响下一个进入的状态
3.3 MDP的 价值函数 & 动作价值函数
-
价值函数 V π ( s ) V^{\pi}(s) Vπ(s):从状态s开始,以Policy π \pi π 运行的return G t G_t Gt 的期望
V π ( s ) = E π ( G t ∣ S t = s ) V^{\pi}(s) = \mathbb{E}_{\pi}(G_t|S_t = s) Vπ(s)=Eπ(Gt∣St=s) -
动作价值函数 q π ( s , a ) q^{\pi}(s,a) qπ(s,a):从状态s,采取动作a开始,以Policy π \pi π 运行的return G t G_t Gt 的期望
q π ( s , a ) = E π ( G t ∣ S t = s , A t = a ) q^{\pi}(s,a) = \mathbb{E}_{\pi}(G_t|S_t = s,A_t=a) qπ(s,a)=Eπ(Gt∣St=s,At=a) -
二者关系:把每个状态s下所有可能采取a的价值 q π ( s , a ) q^{\pi}(s,a) qπ(s,a) 求和(就是求期望),即得s的价值 V π ( s ) V^{\pi}(s) Vπ(s)
V π ( s ) = ∑ a ∈ A π ( a ∣ s ) q π ( s , a ) V^{\pi}(s) = \sum\limits_{a \in A} \pi(a|s) q^{\pi}(s,a) Vπ(s)=a∈A∑π(a∣s)qπ(s,a)
3.4 Bellman等式
-
类似MRP中的Bellman等式,先把return G t G_t Gt和 q q q 分解成立即奖励和未来奖励两部分
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . = R t + 1 + γ ( R t + 2 + γ R t + 3 + . . . ) = R t + 1 + γ G t + 1 \begin{aligned} G_t &= R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} +... \\ &= R_{t+1} + \gamma (R_{t+2} + \gamma R_{t+3} +...) \\ &= R_{t+1} + \gamma G_{t+1} \end{aligned} Gt=Rt+1+γRt+2+γ2Rt+3+...=Rt+1+γ(Rt+2+γRt+3+...)=Rt+1+γGt+1 -
所以有
V π ( S t ) = E π [ G t ∣ S t = s ] = E π [ R t + 1 + γ G t + 1 ∣ s ] = E π [ R t + 1 + γ V π ( S t + 1 ) ∣ s ] \begin{aligned} V^{\pi}(S_t) &= \mathbb{E}_{\pi}[G_t|S_t = s] \\ &= \mathbb{E}_{\pi}[R_{t+1} + \gamma G_{t+1}| s] \\ &= \mathbb{E}_{\pi}[R_{t+1} + \gamma V^{\pi}(S_{t+1})| s] \end{aligned} Vπ(St)=Eπ[Gt∣St=s]=Eπ[Rt+1+γGt+1∣s]=Eπ[Rt+1+γVπ(St+1)∣s]q π ( S t , A t ) = E π [ G t ∣ S t = s , A t = a ] = E π [ R t + 1 + γ G t + 1 ∣ s , a ] = E π [ R t + 1 + γ q π ( S t + 1 , A t + 1 ) ∣ s , a ] \begin{aligned} q^{\pi}(S_t,A_t) &= \mathbb{E}_{\pi}[G_t | S_t = s,A_t=a] \\ &= \mathbb{E}_{\pi}[R_{t+1} + \gamma G_{t+1}|s,a] \\ &= \mathbb{E}_{\pi}[R_{t+1} + \gamma q^{\pi}(S_{t+1},A_{t+1})|s,a] \end{aligned} qπ(St,At)=Eπ[Gt∣St=s,At=a]=Eπ[Rt+1+γGt+1∣s,a]=Eπ[Rt+1+γqπ(St+1,At+1)∣s,a]
-
对于 q π q^{\pi} qπ固定a加和s,对于 V π V^{\pi} Vπ固定s加和a,去掉期望符号后得到二者关系
-
关系式
q π ( s , a ) = R ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) V π ( s ′ ) q^{\pi}(s,a) = R(s,a) + \gamma \sum\limits_{s' \in S} P(s'|s,a) V^{\pi}(s') qπ(s,a)=R(s,a)+γs′∈S∑P(s′∣s,a)Vπ(s′)V π ( s ) = ∑ a ∈ A π ( a ∣ s ) q π ( s , a ) V^{\pi}(s) = \sum\limits_{a \in A} \pi(a|s) q^{\pi}(s,a) Vπ(s)=a∈A∑π(a∣s)qπ(s,a)
-
看图理解一下 q π q^{\pi} qπ和 V π V^{\pi} Vπ的关系


-
-
再上面二式互相带入,即得相邻时刻 q π q^{\pi} qπ 和相邻时刻 V π V^{\pi} Vπ 的关系
-
关系式
q π ( s , a ) = R s a + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) ∑ a ∈ A π ( a ′ ∣ s ′ ) q π ( s ′ , a ′ ) q^{\pi}(s,a) = R_s^a + \gamma \sum\limits_{s' \in S} P(s'|s,a) \sum\limits_{a \in A} \pi(a'|s') q^{\pi}(s',a') qπ(s,a)=Rsa+γs′∈S∑P(s′∣s,a)a∈A∑π(a′∣s′)qπ(s′,a′)V π ( s ) = ∑ a ∈ A π ( a ∣ s ) [ R ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) V π ( s ′ ) ] V^{\pi}(s) = \sum\limits_{a \in A} \pi(a|s) [ R(s,a)+ \gamma \sum\limits_{s' \in S} P(s'|s,a) V^{\pi}(s')] Vπ(s)=a∈A∑π(a∣s)[R(s,a)+γs′∈S∑P(s′∣s,a)Vπ(s′)]
-
看图理解一下


-