本文讲解思路从马科夫过程(MP) 到马尔科夫奖励过程(MRP)最后到马尔科夫决策过程(MDP)。
首先我们要了解马尔科夫性,在上一章1.3我们也提到,当前状态包含了对未来预测所需要的有用信息,过去信息对未来预测不重要,该就满足了马尔科夫性,严格来说,就是某一状态信息包含了所有相关的历史,只要当前状态可知,所有的历史信息都不再需要,当前状态就可以决定未来,则认为该状态具有马尔科夫性。下面用公式来描述马尔科夫性:

根据公式将来的状态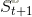
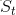
我们用状态转移概率来描述马尔科夫性
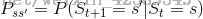
对于很多状态,我们有状态转移概率矩阵
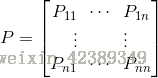
其中n表示状态数量,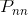
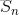
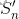
一、马尔科夫过程(Markov Process)
马尔科夫过程又叫马尔科夫链(Markov Chain),它是一个无记忆的随机过程,可以用一个元组<S,P>表示,其中S是有限数量的状态集,P是状态转移概率矩阵。
下面用个逛商城的例子描述:
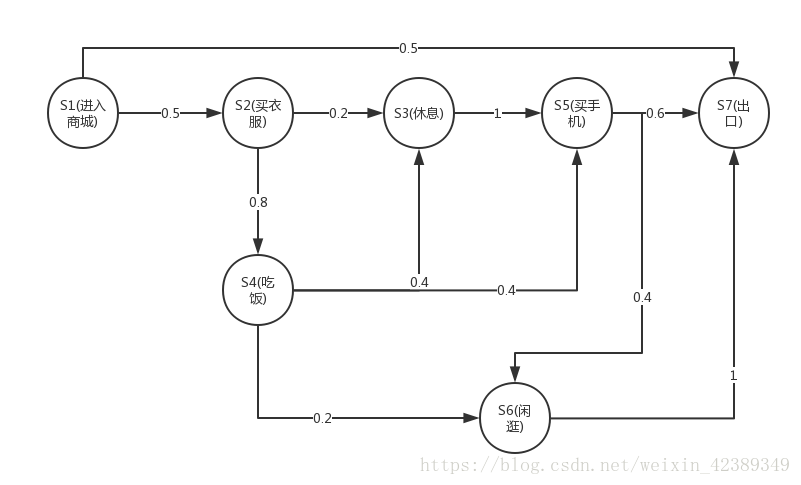
图中圆圈表示数字,箭头表示状态转移,箭头上的数字表示状态转移的概率。很显然,进入商城是初始状态,出口是终止状态,当处于进入商城状态时,有50%的概率会直接去出去,有50%的概率去买衣服。当处于买衣服的状态时,20%的概率选择买完衣服后去休息,有80%的概率在买完衣服后去吃饭。
根据上面的状态图我们从进入商城开始,终止于出口,过程中会产生很多可能性,可以称为Sample Episodes,比如下面可能产生的Episode:
- S1,S2,S3,S5,S7
- S1,S2,S4,S3,S5,S7
- S1,S2,S4,S6,S7
- S1,S2,S3,S5,S6,S7
我们用状态转移概率矩阵来描述所有可能:

转移概率矩阵上每一行的和都为1。
二、马尔科夫奖励过程(Markov Reward Process)
马尔科夫奖励过程是在马尔科夫过程基础上增加了奖励函数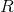
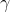
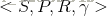

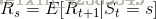
继续用逛商城的例子描述:

上图和前面比较,在每个状态的基础上增加了奖励R。当人进入商城时获得的奖励为-1,进入购买衣服状态后获得的奖励为-2。当处于买衣服的状态时,下一步可能进入休息的状态,获得奖励为-2,还有可能进入吃饭状态,获得奖励为-2,依次下去,直到到达出口状态。
定义:收获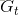

而衰减系数
既然有了收获,我们就需要衡量某一个状态的价值,我们定义如下:
定义:一个马尔科夫奖励过程中某一状态s的价值函数为从该状态开始的马尔科夫链收获

为了理解我们根据上图举例,这次我们从吃饭的状态S4开始,我们有5个马尔科夫链:
- S4,S5,S7
- S4,S5,S6,S7
- S4,S6,S7
- S4,S3,S5,S7
- S4,S3,S5,S6,S7
我们假设
- S4,S5,S7
- S4,S5,S6,S7
- S4,S6,S7
- .................
- .................
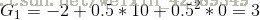

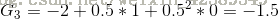
由于计算期望,我们需要知道选择这五条路径的概率,发现我们的转移概率矩阵还没用到,这时我们需要引入Bellman方程。
Bellman方程
我们根据价值函数推导:
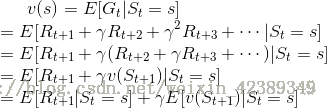
我们可以看到价值函数
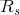
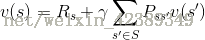
其中S表示下一时刻的所有状态,s'表示下一时刻可能的状态。
根据方程,我们要知道下一个状态的价值,依次下去,很明显这就是动态规划,到达状态S7时,v(S7)=0,我们利用递归就得到结果,当

圆圈内的数字表示该状态的价值v(s)。
上图中
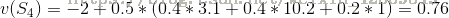
三、马尔科夫决策过程(Markov Decision Process)
马尔科夫决策过程是在马尔科夫奖励过程的基础上加了decisions过程,其实是多了一个动作集合,用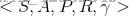
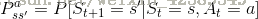
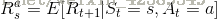
上面公式分别表示动作的概率和动作的奖励函数。如下图,此时箭头表示的是动作,R表示采取动作获得的即时奖励
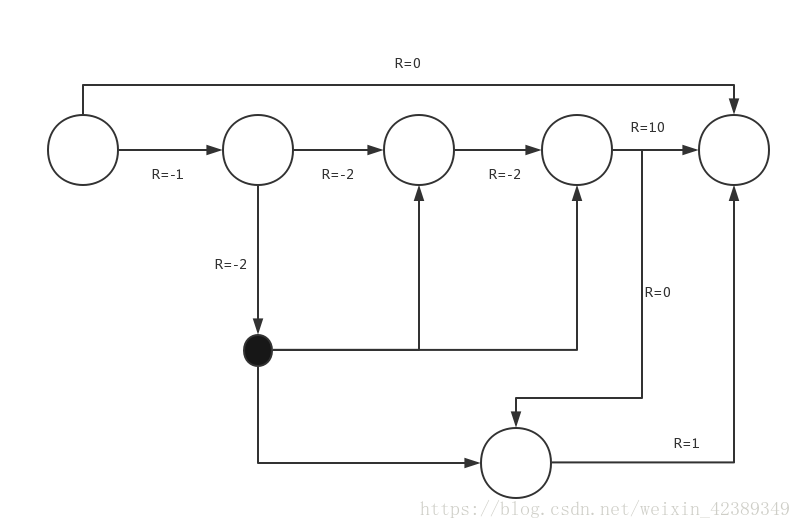
我们用黑色点表示主动进入某个临时状态,当处于这个状态时可能被环境安排到另一种状态,比如人走路,不知不觉就到达新的状态,比如休息室,手机店,注意:此时人是没有选择权的,而是被动的由环境决定到达哪个状态。
策略Policy
我们用

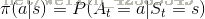
需要注意:
- Policy定义完整定义的个体行为方式,即包括了个体在各状态下的所有行为和概率
- 同时某一确定的Policy是静态的,与时间无关
- Policy仅和当前的状态有关,与历史信息无关,但是个体可以随着时间更新策略
当给定一个MDP和一个策略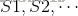
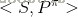
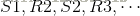
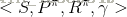
状态转移概率:
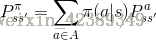
奖励函数:
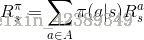
状态转移概率可以描述为:在执行策略
奖励函数可以描述为:在执行策略
我们引入策略,也可以理解为行动指南,更加规范的描述个体的行为,既然有了行动指南,我们要判断行动指南的价值,我们需要再引入基于策略的价值函数。
定义:v(s)是在MDP下的基于策略
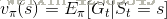
其中
定义: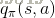
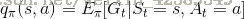
我们根据第二节的Bellman方程做类似推导,可得

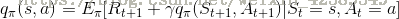
我们知道策略就是用来描述各个不同状态下执行各个不同行为的概率,而状态价值是遵循当前策略时所获得的收获的期望,即状态s的价值体现为在该状态下遵循某一策略而采取所有可能行为的价值按行为发生概率的乘积求和,有如下图:
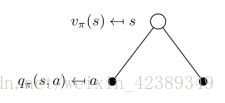
我们可以得到状态价值函数和行为价值函数的关系

继续看图
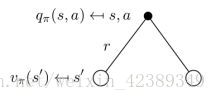
一个某一个状态下采取一个行为的价值,可以分为两部分:其一是离开这个状态的价值,其二是所有进入新的状态的价值于其转移概率乘积的和,一个行为价值函数也可以表示成状态价值函数的形式

上述公式组合可得


下面我们用实例来理解上述公式

假设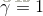
举例:5.5=0.5*(10+0)+0.5*(0+1*1)
1.65=0.5*(-2+0.4*3.5+0.4*5.5+0.2*1)+0.5*(-2+1*3.5)
四*、最优策略
最优状态价值函数指的是在从所有策略产生的状态价值函数中,选取使状态s价值最大的函数:
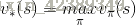
类似的,最优行为函数从所有策略产生的行为价值函数中,选取是状态行为对<s,a>价值最大的函数
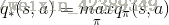
对于任何状态s,遵循策略π的价值不小于遵循策略π'下的价值,则策略π优于策略π’
定理:对于任何MDP,下面几点成立:1.存在一个最优策略,比任何其他策略更好或至少相等;2.所有的最优策略有相同的最优价值函数;3.所有的最优策略具有相同的行为价值函数。
根据上面定理,我们可以通过最大化最优行为价值函数来找到最优策略。
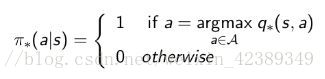
Bellman最优方程
一个状态的最优价值等于从该状态出发采取的所有行为产生的行为价值中最大的那个行为价值
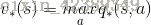
在某个状态s下,采取某个行为的最优价值由2部分组成,一部分是离开状态 s 的即刻奖励,另一部分则是所有能到达的状态 s’ 的最优状态价值按出现概率求和

组合公式可得
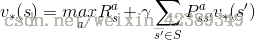

Bellman最优方程是非线性的,没有固定的解决方案,通过一些迭代方法来解决:价值迭代、策略迭代、Q学习、Sarsa等。
简单介绍一下迭代流程
策略迭代(Policy Iteration)
假设我们有一个策略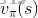
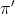
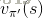
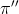

值迭代(Value Iteration)
策略迭代算法包含了一个策略估计的过程,而策略估计则需要扫描(sweep)所有的状态若干次,其中巨大的计算量直接影响了策略迭代算法的效率,实际上没有必要精确计算

上述算法是马尔可夫决策过程的动态规划解法,如果有想深入理解相关内容可以,参考https://zhuanlan.zhihu.com/p/28084955
总结
至此我们了解了马尔可夫决策过程和相关动态规划解法,动态规划的优点在于它有很好的数学上的解释,但是要求一个完全已知的环境模型,显然前面的计算我们都从上帝视角了解整个环境,这在现实中是很难做到的。另外,当状态数量较大的时候,动态规划法的效率也将是一个问题。下一篇我们将介绍不基于模型的算法,蒙特卡洛(MC),时序差分学习(TD)的Q learning和Sarsa learning。
个人相关深度强化学习github地址:https://github.com/demomagic
PS: 如果觉得本篇本章对您有所帮助,欢迎关注、评论、赞!如果要转发请注明作者和出处
参考文献:
[1]《强化学习》第二讲 马尔科夫决策过程:https://zhuanlan.zhihu.com/p/28084942