出处:http://www.fengchang.cc/post/11
参考这里
和 这里
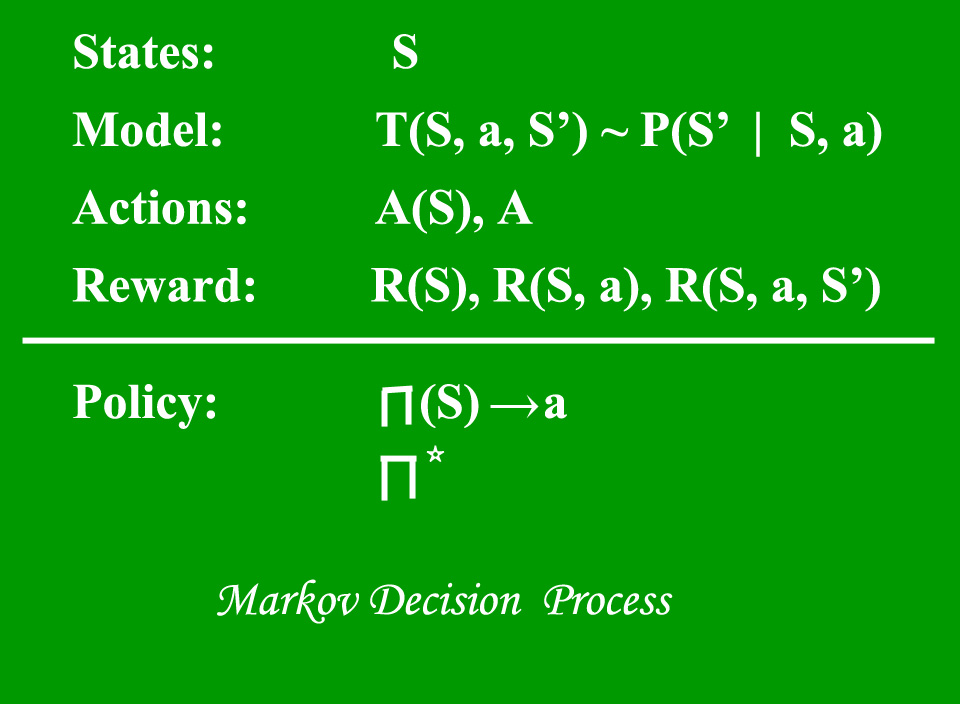
A Markov Decision Process (MDP) model contains:
- A set of possible world states S.
- A set of Models.
- A set of possible actions A.
- A real valued reward function R(s,a).
- A policy the solution of Markov Decision Process.

-
What is a Model?
A Model (sometimes called Transition Model) gives an action’s effect in a state. In particular, T(S, a, S’) defines a transition T where being in state S and taking an action ‘a’ takes us to state S’ (S and S’ may be same). For stochastic actions (noisy, non-deterministic) we also define a probability P(S’|S,a) which represents the probability of reaching a state S’ if action ‘a’ is taken in state S. Note Markov property states that the effects of an action taken in a state depend only on that state and not on the prior history.
What is a Reward?
A Reward is a real-valued reward function. R(s) indicates the reward for simply being in the state S. R(S,a) indicates the reward for being in a state S and taking an action ‘a’. R(S,a,S’) indicates the reward for being in a state S, taking an action ‘a’ and ending up in a state S’.
What is a Policy?
A Policy is a solution to the Markov Decision Process. A policy is a mapping from S to a. It indicates the action ‘a’ to be taken while in state S.
Let us take the example of a grid world: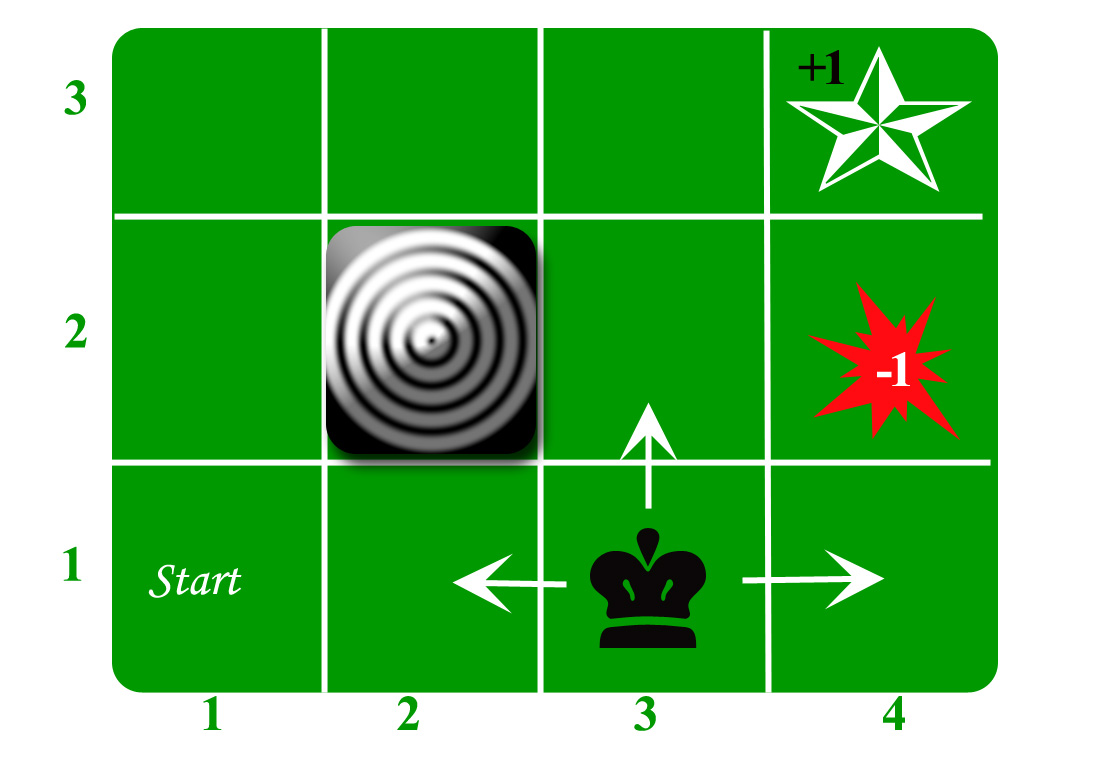

另一个例子:

自己总结下来,有理解上的几个重点,
第一,理解哪些是定的已知的,哪些是变的,在这里状态是定的。
其实就是Model的定义,这个Model是定的,也就是说这样一个条件概率,即在某状态下,采取了某行动后,会跳到哪里是定的,例如上面的格子跳转问题,并不是说在某个格子下就能定好下一个跳转方向的概率,而是说确定了格子位置(状态),以及确定了指令(上下左右,注意,指令是个概率指令,说向上不一定真的向上跳),才知道最终跳到哪个格子的概率是多少。汽车例子也是一样,线的颜色代表概率指令,比如Fast开,但其结果可能导致cool或者warm,并确定了分配的概率(图中是五五分)。另外就是reward是定的,一旦发生了某个具体跳转,例如从某个格子,向上跳了一步,则reward的分数是定的
第二,理解目标是什么,约束条件是什么
目标是找到一个映射(在某状态下做什么),或者说“概率指令”(在第一个我说向右,不一定真的向右走),总之感觉格子这个例子不如汽车例子来得清晰,因为“概率向右”跟“实际向右”容易混淆,但其实实际向右应该理解为一个状态始末变迁的结果(重在末尾状态是什么),而非向右这个过程。那么一旦确定了每个状态的到action的映射,可以定下来的并非一个确定的reward和,而是一个reward和的数学期望,目标就是最大化这个数学期望。约束条件就是model和reward
第三,理解与状态序列的“无关”和“有关”
马尔科夫性就在于跟下一步状态跟前序状态无关(一阶马尔科夫),从跳格子这个问题,可以理解,当前处于的格子决定你到最终目标的最优路径,而至于之前是怎么到当前格子的,并不重要,所以跟之前的状态都是以“无关”的。但是当计算MDP的最优policy时,往往用动态规划去做,思路是从当前状态算起,根据如果往某个方向跳,概率多少,奖惩多少,用条件概率把之后所有的可能一步步串起来,就可以得到数学期望,所以后面的步骤都是“相关”的