最近因为研究需要,要开始学习机器学习了。之前只是懂些CNN什么的皮毛,对机器学习的整体认识都比较缺乏,后面我会从头开始一点点打基础,正好也用博客把自己的学习历程记录一下,如果有大牛看到博文中有错误,欢迎指正!
正好目前有个智能控制的小项目,我就先从增强学习开始。主要的参考文献是吴恩达的专题论文:Shaping and policy search in Reinforcement learning
增强学习(reinforcement learning,RL)是近年来机器学习和智能控制领域的主要方法之一。在增强学习中有三个概念:状态、动作和回报。
“状态(state)”是描述当前情况的。对一个正在学习行走的机器人来说,状态是它的两条腿的位置。对一个围棋程序来说,状态是棋盘上所有棋子的位置。
“动作(action)”是一个智能体在每个状态中可以做的事情。给定一个机器人两条腿的状态或位置,它可以在一定距离内走几步。通常一个智能体只能采取有限或者固定范围内的动作。例如一个机器人的步幅只能是0.01米到1米,而围棋程序只能将它的棋子放在19×19路棋盘(361个位置)的某一位置。
“回报(reward)”是一个描述来自外界的反馈的抽象概念。回报可以是正面的或者负面的。当回报是正面的时候,它对应于我们常规意义上的奖励。当回报是负面的时候,它就对应于我们通常所说的惩罚。
因此,增强学习的核心目标就是解决这样的问题:一个能够感知环境的自治agent,怎样学习到最优动作策略π:S->A,它能在给定当前状态S集合中的s时,从集合A中输出一个合适的动作a。
在研究用于寻找策略的算法之前,我们必须充分了解马尔科夫决策过程(MDP)。
马尔科夫决策过程(MDP)
在面对许多问题时,马尔科夫决策过程为我们提供了一种对规划和行动进行推理的形式。大家应该都知道马尔科夫链(Markov Chain),它与MDP有一个共同性质就是无后效性,也就是指系统的下个状态只与当前状态有关,而与更早之前的状态无关,这一特性为我们增强学习打下了理论基础。不同的是MDP考虑了动作,即系统下个状态不仅和当前的状态有关,也和当前采取的动作有关。
因此MDP可以表示为一个元组(S, A, Psa, R):
- S:所有可能状态的集合。
- A:针对每个状态,我们都要做出动作,这些动作的集合就是A。
- Psa:状态转换分布(statetransition distribution),如果我们在状态s中采取了动作a,系统会转移到一个新的状态,状态转换分布描述了转移到哪个状态的概率分布。
- R:回馈函数(rewardfunction),增强学习的核心概念,描述了动作能够产生的回报。比如Rπ(s,a)描述了在状态s下采用策略π所对应的动作a的回报,也叫做立即回报,回馈函数可以有不同的表达形式。
但是在选取最优策略的过程中,我们只看立即回报并不能判定哪种策略更优,我们希望的是在采取了策略π以后,可以使得整个状态序列的折扣回馈最大:
R(s0, a0)+ γR(s1, a1) + γ2R(s2, a2)+ (1)
其中γ被称为折扣因子,在经济学上的解释叫做无风险折现率(risk-freeinterest rate),意思是马上得到的钱(回馈)比未来得到钱更有价值。
因此,以上概念就组成了增强学习的完整描述:找到一种策略,使得我们能够根据状态s0, s1, s2…采取策略中对应的动作a0, a1, a2…,并使公式(1)的期望值最大化,这也叫做价值函数(value function)Vπ: S→R,表明当前状态下策略π的长期影响。这个函数从状态s开始,根据π来采取行动:
Vπ(s) =Eπ[ R(s0, a0) + γR(s1, a1)+ γ2R(s2, a2) + … | s0= s ]
这个函数也被称为状态价值函数(statevalue function),因为初始状态s和策略π是我们给定的,动作a = π(s)。与之相对应的是动作价值函数(actionvalue function),也叫做Q函数:
Qπ(s, a)= Eπ[ R0 + γR1 + γ2R2 + …| s0= s, a0= a]
其中的初始状态和初始动作都是我们给定的。
函数最优与求解:
进一步,我们定义了最优价值函数(optimalvalue function)和最优Q函数(optimal Q-function):
V*(s) =maxπ Vπ(s)
Q*(s, a)= maxπ Qπ(s, a)
不难证明,V*和Vπ满足下面两个方程:
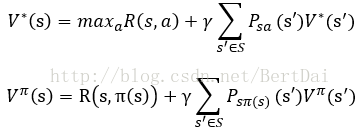
上式称为最优贝尔曼方程,给出了V*和Vπ的递归定义形式,也是V的求解方法。V*的公式说明了通过每一步选取最优的动作a,并在后面的动作中也保持最优,就可以得到V*。Vπ的含义是:如果我们持续根据策略π来选择动作,那么策略π的期望回报就是当前的回报加上未来的期望回报。
相似的,下列对于Q函数的方程也成立:
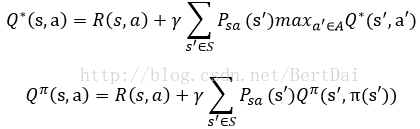
这种递归的定义形式也有利于我们在具体实现时的求解。
在知道V*和Q*后,我们可以通过下面的公式来得到最优的策略π*:
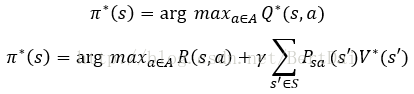
也就是说,如果我们知道了Q*,可以更加方便的计算出最优策略,而要从V*得到最优策略,还必须知道状态转换分布Psa才行。
对于寻找最优策略的具体算法,包括了价值迭代、策略迭代、蒙特卡洛算法和Q学习算法等,后期我会继续整理。