版权声明:本文为博主原创文章,欢迎交流分享,未经博主允许不得转载。 https://blog.csdn.net/qjf42/article/details/79657139
《Reinforcement Learning: An Introduction》 读书笔记 - 目录
Agent-Environment Interface
- agent
- learner and decision maker
- environment
- 与agent交互,包括所有agent之外的东西
- environment’s state
- action
- reward
MDP
几个要素
- state, action, reward集合
- 在
Finite MDP中,这几个集合都是有限集
- 在
-
- Markov性质,简化问题
- 只考虑最近的一次action
- 中其实仍然可以包含 及以前的信息
- 在此基础上,还可以得到几个相关的,如:
- 状态转移概率
- 期望收益
- Markov性质,简化问题
- 例子
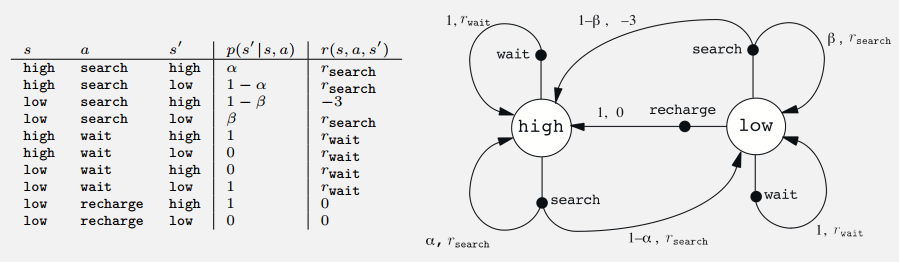
- recycling robot
- recycling robot
目标
- agent的目标是最大化
- reward hypothesis:
That all of what we mean by goals and purposes can be well thought of as the maximization of the expected value of the cumulative sum of a received scalar signal (called reward).
一些概念
- episode
- episodic task
- 有终止的 或者说 一段一段的
- continuing task
- 无限的 或者 不确定能否结束的(?)
- episodic task
- discounted return
- 迭代式:
Policies & Value Functions
policy
- 在状态
下,执行各策略
的概率
- 当是确定型策略时,其中有唯一 ,值为1
- 在状态
下,执行各策略
的概率
- 如何评价一个策略的好坏
state-value function
action-value function
Bellman 方程
-
-
- 出发的边不同,求全概率时用的累加顺序也有所不同:一个 ,一个
- 已知参数( 等),则为线性方程组,对于小规模的状态集,可以直接求解
-
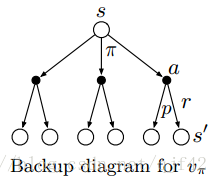
backup diagrams
- 例子
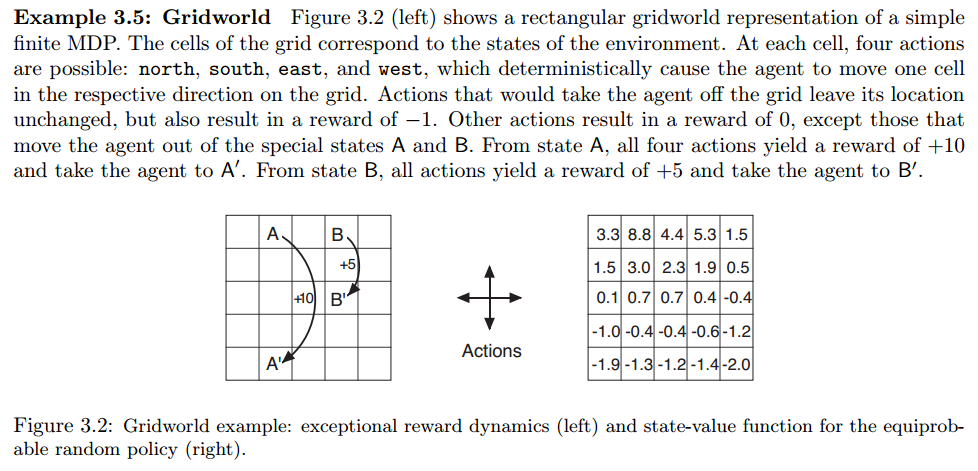
- Gridworld
- Gridworld
最优Policies & 最优Value Functions
optimal policy
- 当已知最优策略时,可以直接采用greedy action
- 因为其定义中的value function已经考虑了长期的reward
- markov性质
- optimal value function
optimal state-value function
optimal action-value function
- search(已知当前
,求最优
)
- 用 需要one-step ahead search,就是要知道所有可行的action及其能达到的state
- 用 的话就省掉了这一步,相当于cache了
- Bellman optimality equation
-
-
- 非线性方程组,有唯一解
-
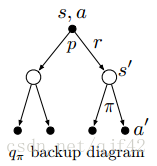
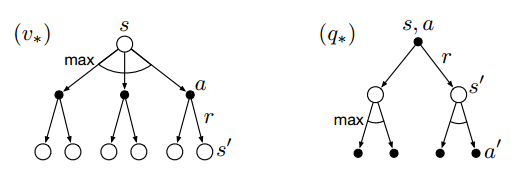
- backup diagrams
- 例子
- recycling robot
- Gridworld
- recycling robot


其它
- Exercise 3.14/3.15: 所有reward都加一个常数c,对value function/optimal policy有影响吗?
- continuing:相当于加了一个无穷等比数列,和为常数,不影响policy
- episodic:因为等比数列的长度不确定,所以不同长度的episode的return增加的也不一样,e.g 加一个接近非常大的正数,会倾向于”拖延”(有些任务timestep越少越好)